论文浅尝 | 基于Universal Schema与Memory Network的知识+文本问答

来源:ACL 2017
链接:http://aclweb.org/anthology/P17-2057
本文提出将 Universal schema 用于自然语言问答中,通过引入记忆网络,将知识库与文本中大量的事实信息结合起来,构建出一个由问答对(question-answer pairs)训练得到的 end2end 模型。通过SPADES填空问答数据集上的评测可以看到,联合文本与知识库信息的策略,相对仅使用单一知识源取得了更好的问答效果,是目前性能最好的模型。
动机
作者认为,现有的问答方法主要利用单一知识库或是粗文本作为事实来源,两者均存在一定的局限性:基于知识库的方法,其性能主要受限于知识库知识的不完整性;粗文本虽然包含了海量事实信息,但呈现为非结构化形式,利用效率相对知识库较低。
Universalschema可以同时处理结构化的知识库信息及非结构化的粗文本信息,并在通用embedding空间中将它们对齐,这一性质使得结合文本与知识库信息用于问答成为可能。
方法
Universal schema
Universal schema 一般被用于处理知识库文本中的关系抽取问题,通过 entity pair 将粗文本规范化,而后得到实体之间的关系表示。这种关系可以是知识库的 relation,也可以是大语料中两个实体间存在的某种模式(pattern)。
利用这种方法,可以将粗文本中的“实体-关系-实体”通过模式的形式呈现出来,也就作为后一步 embedding 的基础。
Memory Networks
记忆神经网络就是在常规的 attention 模型基础上,添加额外的记忆信息保存和引用机制(memory slot),在知识问答中的一个常规用法是将知识库三元组放入记忆槽(slot)中,本文则是将文本获取到的实体模式也作为三元组放入其中。
Model Frame
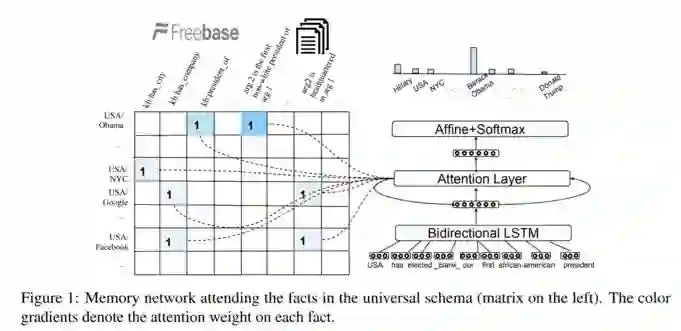
整体的实验模型可以分为两个部分:
左侧是通过Universalschema将文本与知识库知识投影在一个通用空间中,作为融合知识存在,也就是模型的外部记忆信息。
右侧是问答处理机制,输入一个待填空的问句,通过双向LSTM整合为对应上下文向量,而后由一个循环的attention操作引入与该问题实体相关的三元组信息,不断更新该向量,最终得到与知识最相关的问题表示,而后利用softmax选出最相关答案实体,由此完成问答过程
实验
实验数据集
KB: Freebase
Text source:Clue Web
问答数据集:SPADES(填空问答数据集)包含 93K sentences 1.8M entities
实验设计
1. 仅使用文本知识的问答模型
2. 仅知识库知识问答模型
3. 文本+知识库知识问答模型:
a. ENSEMBLE(采用线性模型关联1,2模型)
b. UNISCHEMA(本文方法)
实验结果
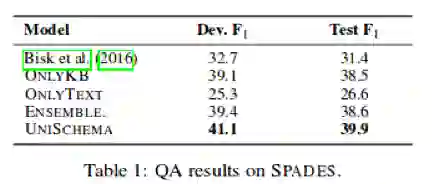
表1:问答实验的结果显示本文方法相对Bisk et al.更优的性能。

表2:通过一些事实结果反应出本文方法引入的文本信息有效弥补了知识库知识的不足
论文笔记整理:谭亦鸣,东南大学博士,研究方向为知识库问答、自然语言处理。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。


