
题目:
Transfer Learning in Visual and Relational Reasoning
简介:
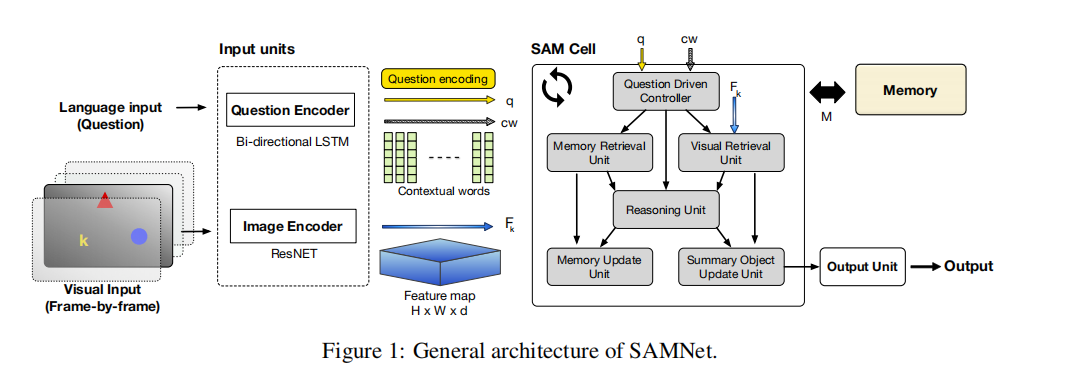
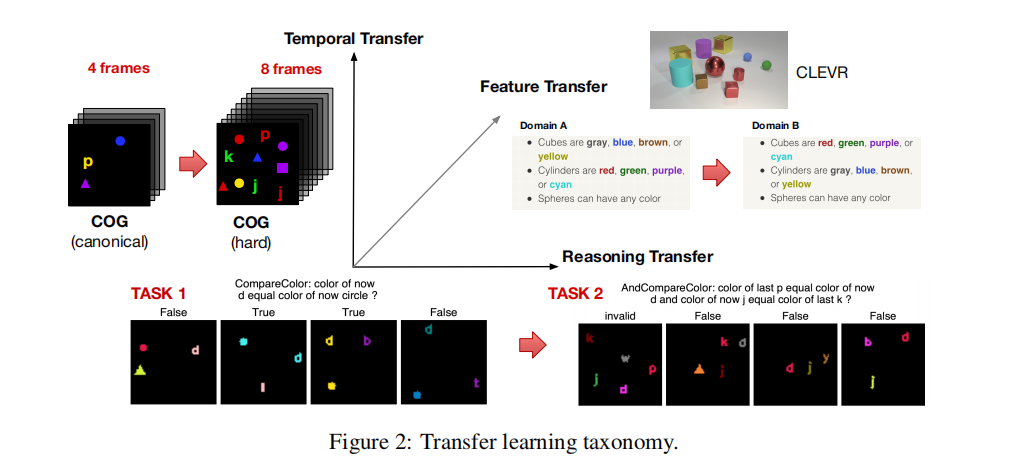
迁移学习已成为计算机视觉和自然语言处理中的事实上的标准,尤其是在缺少标签数据的地方。通过使用预先训练的模型和微调,可以显着提高准确性。在视觉推理任务(例如图像问答)中,传递学习更加复杂。除了迁移识别视觉特征的功能外,我们还希望迁移系统的推理能力。而且,对于视频数据,时间推理增加了另一个维度。在这项工作中,我们将迁移学习的这些独特方面形式化,并提出了一种视觉推理的理论框架,以完善的CLEVR和COGdatasets为例。此外,我们引入了一种新的,端到端的微分递归模型(SAMNet),该模型在两个数据集上的传输学习中均显示了最新的准确性和更好的性能。改进的SAMNet性能源于其将抽象的多步推理与序列的长度解耦的能力及其选择性的关注能力,使其仅能存储与问题相关的信息外部存储器中的对象。
目录:
成为VIP会员查看完整内容
相关内容

迁移学习(Transfer Learning)是一种机器学习方法,是把一个领域(即源领域)的知识,迁移到另外一个领域(即目标领域),使得目标领域能够取得更好的学习效果。迁移学习(TL)是机器学习(ML)中的一个研究问题,着重于存储在解决一个问题时获得的知识并将其应用于另一个但相关的问题。例如,在学习识别汽车时获得的知识可以在尝试识别卡车时应用。尽管这两个领域之间的正式联系是有限的,但这一领域的研究与心理学文献关于学习转移的悠久历史有关。从实践的角度来看,为学习新任务而重用或转移先前学习的任务中的信息可能会显着提高强化学习代理的样本效率。
专知会员服务
66+阅读 · 2020年4月17日
专知会员服务
87+阅读 · 2020年3月1日
专知会员服务
64+阅读 · 2020年1月11日
专知会员服务
95+阅读 · 2019年11月8日
Arxiv
10+阅读 · 2020年3月12日
Arxiv
3+阅读 · 2019年1月20日
Arxiv
7+阅读 · 2018年5月24日




相关VIP内容
专知会员服务
66+阅读 · 2020年4月17日
专知会员服务
87+阅读 · 2020年3月1日
专知会员服务
64+阅读 · 2020年1月11日
专知会员服务
95+阅读 · 2019年11月8日
相关资讯
相关论文
Arxiv
10+阅读 · 2020年3月12日
Arxiv
3+阅读 · 2019年1月20日
Arxiv
7+阅读 · 2018年5月24日