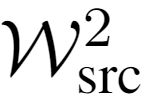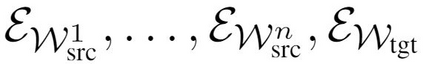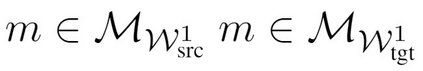We present the zero-shot entity linking task, where mentions must be linked to unseen entities without in-domain labeled data. The goal is to enable robust transfer to highly specialized domains, and so no metadata or alias tables are assumed. In this setting, entities are only identified by text descriptions, and models must rely strictly on language understanding to resolve the new entities. First, we show that strong reading comprehension models pre-trained on large unlabeled data can be used to generalize to unseen entities. Second, we propose a simple and effective adaptive pre-training strategy, which we term domain-adaptive pre-training (DAP), to address the domain shift problem associated with linking unseen entities in a new domain. We present experiments on a new dataset that we construct for this task and show that DAP improves over strong pre-training baselines, including BERT. The data and code are available at https://github.com/lajanugen/zeshel.
翻译:我们提出“零点实体”连接任务,其中提及必须与没有主域标签数据、没有主域标签的无形实体相联系。目标是实现向高度专门化领域的可靠转让,从而不假定元数据或别名表格。在这一背景下,实体只能通过文字说明确定,模型必须严格依赖语言理解才能解决新实体。首先,我们表明,在大型无标签数据方面经过预先培训的强力阅读理解模型可以用于对隐形实体进行概括。第二,我们提出一个简单有效的适应性培训前战略,我们称之为域适应前培训(DAP),以解决与在新领域连接隐形实体相关的域转移问题。我们介绍了我们为这项任务构建的新数据集的实验,并表明DAP在强大的培训前基线(包括BERT)上有所改进。数据和代码可在https://github.com/lajanugen/zeshel查阅。