
摘要: 对于没有标注资源的语言,从资源丰富的语言中转移知识是命名实体识别(NER)的有效解决方案。虽然现有的方法都是直接从源学习模型转移到目标语言中,但在本文中,我们建议通过一个测试用例的几个类似例子对学习模型进行微调,这样可以利用类似例子中传递的结构和语义信息来帮助预测。为此,我们提出了一种元学习算法,通过计算句子相似度来寻找一种能快速适应给定测试用例的模型参数初始化方法,并提出了构造多个伪ner任务进行元训练的方法。为了进一步提高模型在不同语言间的泛化能力,我们引入了掩蔽机制,并在元训练中增加了一个最大损失项。我们在五种目标语言中以最少的资源进行了大量的跨语言命名实体识别实验。结果表明,我们的方法在整体上显著优于现有的最先进的方法。
成为VIP会员查看完整内容
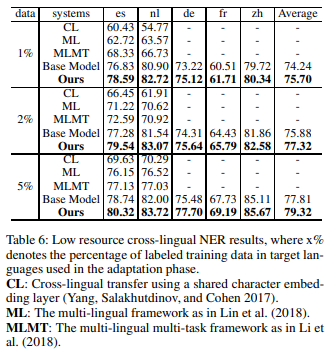
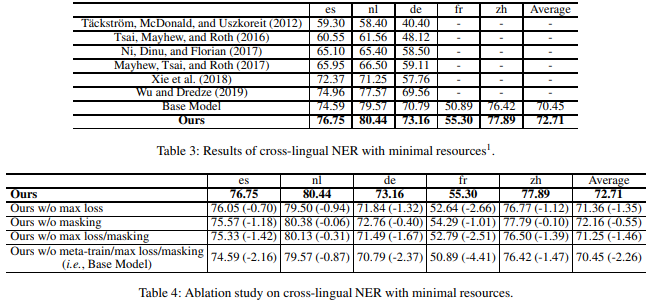


相关内容

专知会员服务
66+阅读 · 2020年4月17日
专知会员服务
27+阅读 · 2020年4月5日
专知会员服务
64+阅读 · 2020年1月11日
专知会员服务
52+阅读 · 2019年12月28日
专知会员服务
102+阅读 · 2019年11月24日
Arxiv
13+阅读 · 2019年11月14日
Arxiv
4+阅读 · 2017年10月26日




相关VIP内容
专知会员服务
66+阅读 · 2020年4月17日
专知会员服务
27+阅读 · 2020年4月5日
专知会员服务
64+阅读 · 2020年1月11日
专知会员服务
52+阅读 · 2019年12月28日
专知会员服务
102+阅读 · 2019年11月24日
相关资讯
相关论文
Arxiv
13+阅读 · 2019年11月14日
Arxiv
4+阅读 · 2017年10月26日