AAAI 2020论文解读:关注实体以更好地理解文本

作者 | 梁晨
编辑 | 唐里

下面要介绍的论文选自AAAI 2020,题目为:「Attendingto Entities for Better Text Understanding」,axriv地址为:https://arxiv.org/abs/1911.04361。
关注实体以更好理解文本
摘要:NLP最新进展是基于Transformer的大规模预训练语言模型(GPT,BERT,XLNet等)的开发,并且该模型在一系列任务中取得了最佳的结果。这清楚的体现了当足够多的层与大量的预训练数据配对时self-attention堆叠结构的强大功能。然而,在需要处理复杂且远距离推理任务时,表面层级的内容是往往不够的,预训练模型与人类表现之间仍然存在很大差距。Strubell等人最近表明,通过监督的self-attention可以将句法的结构知识注入模型。我们认为将语义知识类似的注入到现有模型中,将会提高模型在此类复杂问题上的表现。在LAMBADA任务上,我们发现从零开始训练并同时作为self-attention的辅助监督的模型优于最大的GPT-2模型。与GPT-2相比,该模型包含的参数很小。我们还对模型架构和监督设置的不同变体进行了全面分析,为以后将类似技术应用于其他问题提供了建议。
1.相关介绍
什么时候才能明确考虑语言结构有助于NLP任务的执行?
诸如ELMo,GPT,BERT和XLNet之类的大规模预训练模型最近在各种任务上都取得了最新的成果。这些模型大多基于Transformer中的self-attention结构,没有经过明确的经过语言结构的训练,但是无论如何,它们已经显示出可以编码一些语言知识,特别是与语法结构相关的知识。
但是,在某些需要复杂且远距离推理任务,包括需要更广泛的论述、共指解析或者识别有效推理的任务时,预训练模型与人类表现之间仍然存在较大差距。特别是对于基于语言结构的显式信息是否有用,应该如何注入语言结构,是否对现有的语言模型有帮助这样的任务,仍然是一个很有意思的问题。
Strubell等人研究了如何通过self-attention权重的监督将语法知识注入Transformer模型。有趣的是,他们将ELMo嵌入应用于语义角色标注,比使用嵌入但没有监督self-attention的基准有所提高。
在本文中,我们考虑了一项需要远距离知识的任务,即LAMBADA任务。LAMBADA是一种针对叙述文本段落的语言建模任务,在给定几个句子的较多上下文时,对于人类来说很容易解决,但在仅给出一个句子的情况下,人类是很难解决的。在最初引入LAMBADA的论文中,Paperno等人的模型准确性仅为7.3%。较新的模型(GPT-2)提高到63.24%,而人类性能超过80%。因此,在LAMBADA数据集上预训练模型与人类性能之间仍存在较大差距。
我们实验中与Strubell等类似的方式注入语言知识,在现有的非Transformer模型上添加self-attention,以提高此复杂任务的性能。由于LAMBADA专注于叙事文本,因此我们假设有关段落中提到的实体的语义知识对于解决任务是非常有用的(比如在图一中,知道“you”代表“Jon”,“he”代表“Tony”对做出正确的预测是很重要的)。我们将实体知识描述为关于段落中共指链的知识。我们发现,基于BIDAF的模型经过共指作为辅助监督训练,仅使用最佳模型(GPT-2)的参数的一小部分,即可实现最佳的性能。我们将进一步详细分析结果,表明辅助监督可以使模型更好地捕获文本中的共指信息。为了提供有关如何将类似技术应用于其他问题的一些见解,我们尝试使用不同的模型变体来测试将监督插入系统的最佳位置,并且我们还测试将不同类型的语言知识作为监督。
2.背景及相关工作
2.1预训练模型
预训练模型在为下游任务提供上下文嵌入方面取得了飞速的发展,在诸如word2vec或Glove之类的传统固定矢量词嵌入上建立了新的技术水平。Peters等人首次引入了ELMo,这是一种在1B Word Benchmark上进行了预训练的双向LSTM语言模型,当时在许多任务上包括阅读理解,语义角色标注,共指解析以及许多其他任务上都达到了最佳效果。
2.2预训练模型中的语言结构
随着NLP中Transformer的日益流行,后来的工作重点转移到了预训练的Transformer模型上。Radford等人引入了GPT,通过在BooksCorpus上预培训12层transformer模型作为生成语言模型。在所研究的12项任务中,有9项任务GPT的表现优于以往的技术。BERT通过允许双向self-attention与新的“掩盖语言模型”预训练目标来增强GPT模型,并取得了比GPT更好的结果。GPT-2直接扩展GPT,具有10倍更大的预训练语料库和更复杂的模型体系结构(多达15亿参数),并在许多语言建模任务上设置了新的技术状态。通过引入新的预训练和优化策略,XLNet和RoBERTa模型比BERT有了进一步改善。
预训练模型中的语言结构前面提到的预训练模型没有考虑任何语言结构,因为预训练目标是预测下一个随机掩盖的单词或句子。尽管这些经过预训练的模型在许多任务上都取得了最新的成果,但在很大程度上尚不清楚语言结构的隐式知识(例如句法结构或共指)在多大程度上改进这些任务。Tenney等人设计了一系列探测任务,以测试从ELMo/GPT/BERT获得的上下文表示在某些核心NLP pipeline上的表现如何,并发现上下文嵌入在语法任务(例如部分词性标记和解析)上有很大的改进,但在语义任务(例如共指)上则没有那么多进步。Strubell等人最近通过将语法知识注入Transformer模型,在语义角色标注方面取得了最新的成果。在他们的LISA模型中,一个self-attention被引导通过辅助监督信号来学习依赖关系,该辅助信号鼓励每个标注只关注其父项语法。他们还表明,这种语法的自注意力可以与ELMo嵌入结合使用,从而在仅具有ELMo和自注意力但没有辅助监督的情况下进一步提高基线的性能。本文旨在研究语义结构的语言知识能否以类似的方式注入。

图1
2.3 LAMBADA 任务
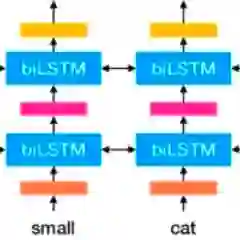
Paperno等人引入了LAMBADA数据集,这是一种经过特殊设计的语言建模任务,其中每个数据点都是由上下文(平均4到5个句子)和目标句子组成的段落,任务是预测目标句子的最后一个单词。数据来源于书籍语料库,并被人工主题过滤,这样当提供整个段落时,人类很容易猜出目标单词,但仅给出目标句子则无法猜出。示例如图1所示。
Paperno等人。还记录了有关该任务的一些标准语言模型的结果,这些结果都非常低,没有一个达到1%的准确率,而以从段落中选择随机大写单词为基准,得出的准确度仅为7.3%,体现了该项任务的难度。
从那时起Chu等人建议将LAMBADA视为阅读理解,句子作为上下文,以目标句子不包含最后一个单词作为查询。然后要求模型从上下文中选择一个单词作为答案。尽管这种设置下模型在有19%的目标词不在上下文中的测试用例中肯定会错误,但这样做仍然大大提高了性能,使得准确率达到了49%。Dhingra等人通过结合Gated-AttentionReader,将准确率提高至55.69%,Hoang、Wiseman和Rush将Attention-SumReader与多任务目标相结合,跟踪上下文中的实体,从而结果进一步提高到59.23%。这两个实验都证明了在任务中使用共指的有效性。
在将Transformer模型应用于任务中也做了一些努力。Dehghani等人使用Transformer其准确率达到56.25%。最近,Radford等人报告中使用GPT-2模型(15亿个参数)将准确率提高到了63.24%,为目前的最高水平。尽管如此,它仍然与Chu等人估计的86%的人类表现相差甚远。
3.方法
3.1任务
我们采用与LAMBADA上大多数工作相同的设置,即将任务视为阅读理解。形式上,我们将上下文语句中的所有标记连接起来以获得上下文输入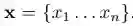
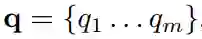
该模型计算出上下文中每个单词的正确答案的概率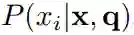
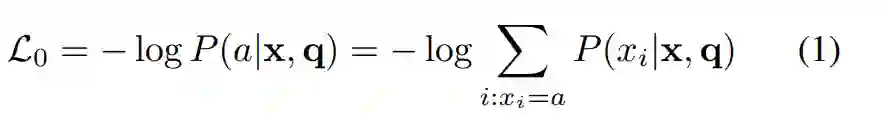
在实验中使用pointer-sum机制来预测上下文中所有不同单词类型中总概率最高的单词类型。
3.2模型
本文旨在测试语义结构的语言知识是否可以通过监督下的self-attention注入到现有模型中,以及该模型在LAMBADA任务上的性能是否可以与大规模预训练模型(如GPT-2)相匹配。
如第2节所述,在先前的工作中已经测试了一系列不同的阅读理解模型,这些模型在该任务上均有相当强的表现;因此我们决定从传统的阅读理解模型入手,并将其融合到一个更简单,更浅显的self-attention中。选择另一个广泛使用的阅读理解模型BiDAF模型作为出发点。BiDAF在许多阅读理解任务基线中一直优于上述模型。
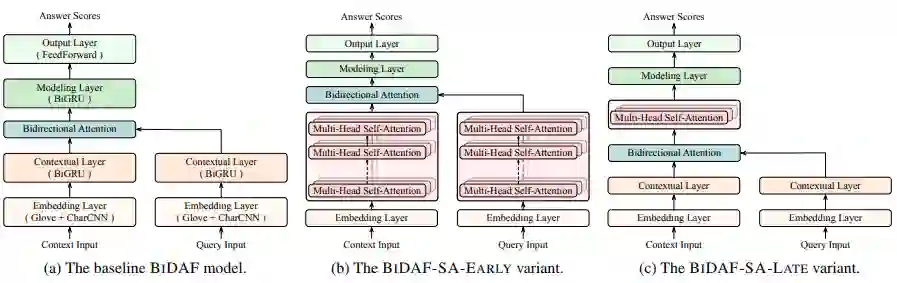
图2
3.2.1 BIDAF基线
如图2a所示,原始的BIDAF模型主要包括以下结构:
1.嵌入层:通过Glove嵌入和Character-CNN嵌入的串联表示上下文和查询中的每个标记。
2.上下文层:使用双向LSTM编码器对上下文和查询序列进行编码。
3.双向注意层:计算query-to-context和context-to-query两个方向的的attention,然后将它们用于合并查询和上下文表示,获取每个上下文单词的query-aware表示。
4.建模层:使用另一个双向LSTM编码对query-aware的上下文表示进行编码,以捕获以查询为条件的上下文词之间的交互信息。
5.输出层:通过前馈层,softmax层,预测每个上下文词是正确答案的概率。
同时使用LSTM替换GRUs,添加了一个规范化层,我们的基线模型基本上与原始BIDAF相同。
3.2.2 带有Self-Attention的BiDAF
为了通过监督注意力将语义知识注入模型,我们需要将堆叠的多头注意力编码融合到BIDAF模型中。直观地讲,self-attention编码器的适用于两个选项:
a)使用编码器替换上下文层,如图2b所示。
这是受到在许多NLP问题中使用self-attention编码器取代传统的基于RNN的编码器的趋势的启发。另外,使用BERT的常见做法是,首先用BERT对原始输入进行编码,然后将输出传递到更高级别的任务特定层,这与我们在此处所做的类似。我们将此变体命名为BIDAF-SA-EARLY。
b)在双向注意层之后添加编码器,如图2c所示。
这受BIDAF++模型的启发,在双向注意层之后添加了一个标准的self-attention层,以帮助对多个段落进行推理。在这里,我们使用多头self-attention,因为在仅具有一个注意头的注意层上应用辅助监督导致在初步实验中表现不佳。我们将此变体命名为BIDAF-SA-LATE。
我们还将探索结合了这两种选择的另一个变体,称为BIDAF-SA-BOTH模型。
3.3 self-Attention的辅助监督
与Strubell等人类似。我们希望在self-attention编码器上应用辅助监督,以指导模型学习特定的语言结构。我们的模型接收上下文以及查询输入,即文章段落与目标句子去掉最后一个单词。我们专注于研究上下文输入的辅助监督,因为在上下文输入中平均有4到5个句子,应该比查询输入这一个句子有更丰富的语言结构。为了检查哪种语言结构对该问题有益,我们尝试了三种类型的监督信号:

图3
DEPPARSE:这类似于Strubell等人使用的辅助监督。只是我们有多个句子而不仅仅是一个句子。如果使用这种语法监督来训练注意头,我们会通过句子边界来约束self-attentio窗口,即每个标记只能关注同一句子中的其他标记,从而使模型更容易接近目标self-attention权重。
CoreferenceSupervision:给定上下文中的共指链列表(每个共指链包含一组对同一实体的引用),我们通过将相同共指中每对引用头之间的权重设置为1来构造目标self-attention权重,其余的则为0,如图3b中间一栏所示。我们将其命名为COREFALL。
我们还测试了共指监督的其他变体,即引导每个引用的仅关注最近一次引用或紧随其后的引用。我们将这两个变体分别称为COREFPREV和COREFNEXT。
NarrativeSupervision:由于LAMBADA数据集是根据叙事小说集构建的,因此我们叙事假设结构(即事件的顺序及其参与者)对于预测缺失的单词可能也很重要。单个事件的谓词和参数之间的交互在很大程度上由上述语法监控捕获。因此,我们将依赖关系解析和共指链相结合,以构建另一种反映高级叙事知识的self-attention目标,如图3b的右列所示:对于每个事件参数a,我们在a和所有与a有共同引用的论据的谓词之间的权重加上1。我们将这种监督叙述命名为NARRATIVE。
注意,虽然需要一些额外的信息(即依赖性解析和关联引用链,如图3a所示)来构造辅助监督信号,但是我们不依赖于训练集或测试集上的任何评注。所有的信息都可以从运行现有的NLP工具获得。我们将在第4节中详细讨论预处理步骤。
如果将任何辅助监督应用于self-attention头,则我们根据监督矩阵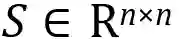

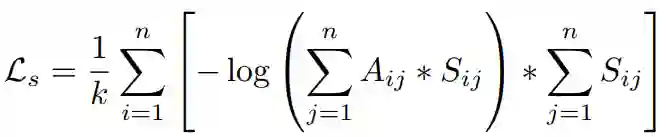
其中k是S中的行数,因此行中至少有一个非零元素。为了说明这一点,对于每一个至少有一个监督目标的标记,我们计算其所有监督目标的负对数似然损失,然后计算其平均值。不管是否应用了辅助监督,该模型以end-to-end的方式进行训练。对于与辅助监督s1,s2,...相结合的模型,优化的总损失是:
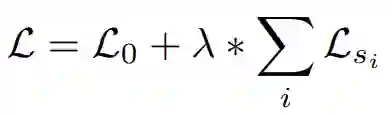
其中λ是在最终预测损失和辅助损失之间进行平衡的超参数。
4.实验结果
4.1数据集和预处理
引入LAMBADA数据集时,Paperno等人将语料库随机分为2个部分,仅对下半部分使用人工过滤过程来创建开发/测试集,而将上半部分的原始数据保留为训练集。通过Chu等人介绍的阅读理解设置。他们还通过要求目标句子中的最后一个词必须存在于上下文中,从原始数据中构造了一个约160万个实例的新训练集。后续工作中Dhingra等人通过删除目标词为停用词的所有实例进一步过滤产生了新训练集,其中大约有70万个实例。我们在这里遵循相同的设置,总结如表1所示。
表1

正如第3节所述,我们还需要从数据中得到依赖关系树和共指链,以便构造辅助监督的目标attention权重。我们使用了斯坦福CoreNLP工具包中的神经依赖性解析器和统计共指系统对整个数据集进行预处理。将在第5节中进一步讨论关于预处理的可替代选择。
4.2实验细节
我们构建模型并使用AllenNLP进行所有实验。对于基线BIDAF模型,我们主要遵循原始模型的超参数,我们对模型进行了10个epochs的训练,并在验证集精度连续两个epoch都没有提高的情况下早停。使用验证集准确性来选择最佳epoch,并对测试集进行评估。
对于BIDAFSA-*变体中的多头注意编码器,我们在每层使用4个注意头。在BIDAF-SA-EARLY中,我们使用了4层堆栈式self-attention编码器,初步实验表明,仅使用1层或2层使得性能严重下降,而使用超过4层对结果没有显著改善。对于BIDAF-SA-LATE,我们只添加了1个多头self-attention层,同样显示使用两个或更多层没有进一步的提高结果。在一些实验中,我们还尝试用预先训练好的ELMo替换嵌入层。
我们发现,模型性能对初始的随机状态非常敏感,这可能是因为训练集和开发/测试集之间存在较大的统计差异。我们在复现文献中的现有模型中时观察到了类似的效果。因此,对于每个模型变体,我们用不同的随机种子训练4次,并记录这4个模型的平均和最佳性能。
4.3 实验结果
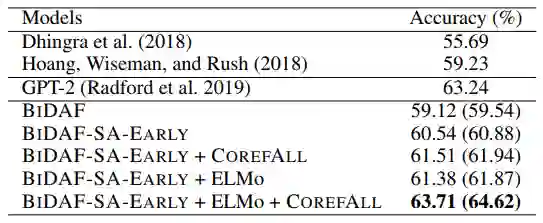
将我们的方法与之前两种没有使用大规模预训练语言以及GPT-2的最佳模型在LAMBADA上进行了比较。需要注意的是,我们不与其他预训练LMs进行比较,是因为BERT以及XLNet都将书籍语料库作为预训练数据。由于LAMBADA任务是由书籍语料库构建的,BERT等模型在训练前已经使用了所有的数据实例,因此这些模型在任务上获得了不公平的优势。
我们在表2中列出主要结果。我们首先关注BIDAF-SA-EARLY模型和COREFALL监督,因为从直觉上讲,关于段落中的共指链知识可能是解决任务的最有利因素。将在第5节中讨论其他变体的结果。
可以看出BIDAF基线已经表现出与GPT-2之前的最佳结果相似的性能。添加COREFALL辅助监督可以不断提高准确性,但与不使用ELMo嵌入相比,使用ELMo嵌入的COREFALL得到了更大的改进。这些结果证实了除了最近的预训练模型之外,通过监督的self-attention来注入语义知识同样对结果有所帮助。同样,ELMo本身仅带来不足1个点的改进而没有COREFALL的事实也强调了这项任务的难度。在借助ELMo嵌入和COREFALL监督下,我们的平均准确度达到63.71%(最佳运行达到64.62%),优于最大的GPT-2模型。考虑到我们的模型仅包含260万个可调参数,远远小于GPT-2(15亿)的参数,这是相当令人惊讶的。
表2
5.分析
在本节中,我们旨在理解共值监督为什么有帮助,什么是应用辅助监督的最佳使用方式,以及不同类型的监督信号该如何比较。
5.1 预处理质量会影响性能吗?
我们从中构造监督信号的斯坦福CoreNLP统计共值系统并不是当前基于基准的最佳共值模型。我们还试验了更新的end-to-end神经共指模型该模型具有更高的基准评分,作为BIDAF-SA-EARLY+COREFALL模型的监督信号,令人惊讶的是,这产生了较差的性能(平均为61.13%,而斯坦福大学的结果为61.51%)。
我们在某些数据点上手动检查了两个共指系统的输出,发现神经共指中经常产生错误的输出,这可能是因为它已针对新闻中心训练数据OntoNotes数据集进行了优化而LAMBADA由叙述文本组成。图4显示了一个示例,其中来自神经系统的共指链导致错误的预测。此示例与图3a中的示例相同,该示例显示了斯坦福系统的共指输出。在此示例中,很难在不知道“you“指“Jon”而“he”指“Tony”的情况下预测出正确的答案,斯坦福系统都正确地预测了这两种情况。这表明更好的共值信息可能会使得任务获得更好的结果。鉴于最近Joshi等人进一步提高了共值性能,我们将在未来的工作中讨论共值信息对结果的提升。
表3
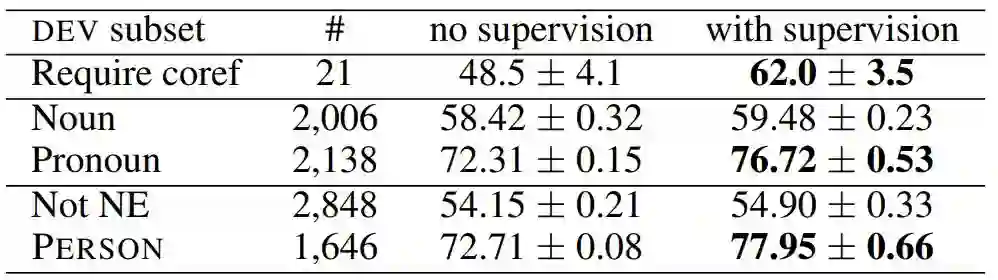

图4
5.2 COREFALL真的学到了共指知识吗?
我们想知道COREFALL的改进是因为监督实际上将使模型更好地学习共指结构,还是由于一些未知的混杂因素。Chu等人手动分析了LAMBADA DEV数据集中的100个随机实例,以确定人做出正确预测所需的推理类型,并发现100个实例中有21个需要共指解析。我们在这21个实例上测试我们的模型。为了获得更大的实例集,我们还比较了DEV集中的目标词是名词的与目标词是代词的实例,同时我们将目标词是PERSON但不是命名实体的情况与其进行比较。(最常见的命名实体类型是PERSON,其他类型很少出现,因此我们更加关注PERSON)。
表4
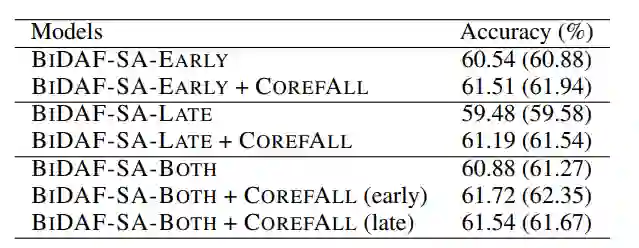
表3中的结果表明,COREFALL监督不仅可以提高手动分类需要共指的21个实例的准确性,而且与"Noun"和"Not NE"对应的对应部分相比,它极大地提高了"Pronoun"和"PERSON"子集的性能。虽然这不是直接证据,但直观地支持辅助监督确实使模型能够更好地捕获共指信息的说法,这尤其有助于对代词和命名实体进行推理。
5.3 应该在哪里实施监督?
在模型的早期阶段(即BIDAF-SAEARLY模型中的上下文层)或后期(即BIDAF-SA-LATE模型中的双向attention层之后)应用辅助监督是否更有利?此外,为了消除结构变化的影响,我们在不同阶段添加监督的情况下尝试使用BIDAF-SA-BOTH模型。
表4显示,在没有监督的情况下,BIDAF-SA-EARLY与BIDAF-SA-LATE相比,EARLY有着更好的结果。尽管在BIDAF-SA-LATE上增加监督可以带来较大的相对改进,但在早期阶段应用监督仍然比在后期阶段进行监督具有更好的性能,这也得到了BIDAF-SA-BOTH上得到了确认。这并不奇怪,因为与上下文输入有关的共指信息有助于获得更好的query-aware表示。
5.4 其他类型的监督也有用吗?
到目前为止,我们专注于COREFALL监督。在表5中,我们记录了应用其他类型的辅助监督的结果。除NAR-RATIVE之外,所有其他类型的辅助监督都比CORE-FALL表现差。如预期的那样,因为LAMBADA任务是专门为要求更广泛的语境而设计的,所以句内句法结构(DEPPARSE)并没有发挥出作用。共指信息的COREFPREV和COREFNEXT变体仅提供对同一共指链中紧接在前或在后引用的指导。当长共指链上的推理对做出预测至关重要时,此类知识是往往不足的。
表5
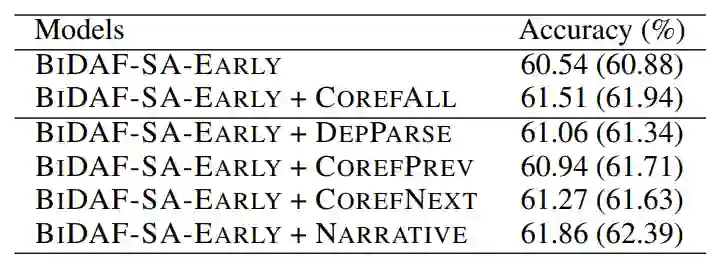
因为NARRATIVE信号是从依赖解析和共指链派生,所以NARRATIVE监督的性能比COREFALL略好。从理论上讲,这种类型的监管应该从COREFALL和DEPPARSE两者中获取有用的语言结构,COREFALL对性能的提高做出了主要贡献,而DEPPARSE则可以提供一些额外的动力。我们通过计算DEV集上两个模型的预测之间的一致性验证了假设,平均而言,仅使用COREFALL和仅使用NARRATIVE结果的在一致性为89.3%,从而确认在NARRATIVE监督下,主要是由于共指提高了最终的成绩。
6.总结
在本文中,我们研究了通过监督的self-attention将语义知识注入现有模型(BIDAF)是否可以在需要复杂和远距离推理的任务上实现更好的性能。在LAMBADA数据集上,当前GPT-2的最佳结果仍远低于人工结果,我们证明了以共指作为辅助监督训练的BIDAF模型仅仅只需要GPT-2中很小一部分参数就能达到最新的水平,同时进一步尝试模型变体,以测试在BIDAF模型中最适合在何处添加带有监督的self-attention层,以及如何比较作为监督信号的不同类型的语言知识。
本文迈出了第一步,即显式地使用结构语义知识来告知self-attention,从而引出了许多有趣的未来方向。首先,我们要测试其他类型的语言知识,例如语义角色标注或AMR解析。我们还希望了解如何将当前方法应用于其他任务,例如新的QUOREF数据集,该数据集需要解决实体间的共同引用才能回答问题。在本文中,我们从现有的NLP pipeline工具中提取监督信息,而这些信息实际上是非常嘈杂的(尤其是在共指时)。当预训练语言模型时,在远距离的监督下(例如,在维基百科文档中,具有指向同一维基百科页面链接的标记应被视为共指)观察这样的语义结构是否可以联合学习是很有意思的。