
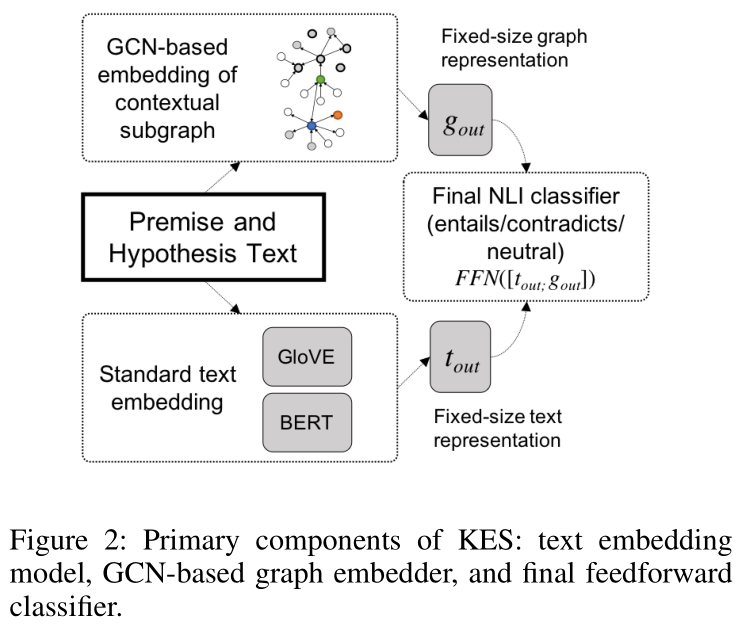
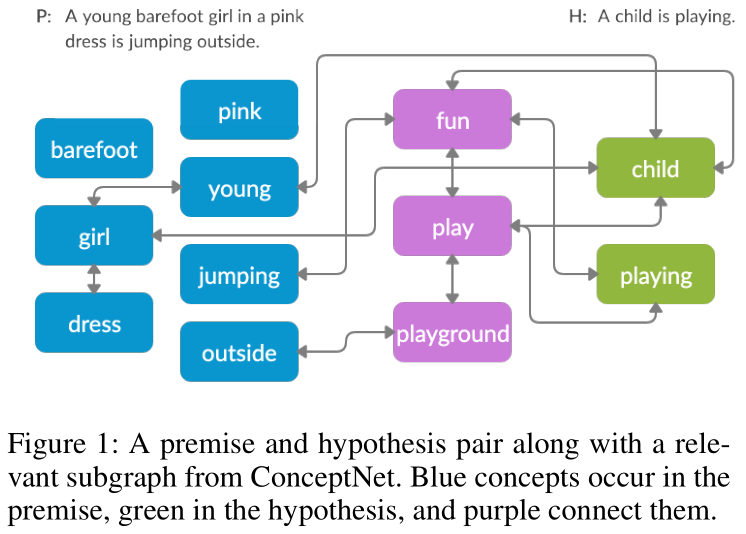
摘要:文本蕴涵是自然语言处理的基本任务。大多数解决这个问题的方法只使用训练数据中的文本内容。一些方法已经表明,来自外部知识来源(如知识图谱)的信息除了文本内容之外,还可以通过提供对任务至关重要的背景知识来增加价值。然而,所提出的模型并没有充分利用通常大而有噪声的公斤中所包含的信息,而且也不清楚如何有效地编码这些信息以使其对加密有用。我们提出了一种方法,通过(1)使用个性化的PageR- ank生成低噪声的上下文子图和(2)使用图卷积网络捕获KG结构对这些子图进行编码,用KGs的信息来补充基于文本的嵌入模型。我们的技术扩展了文本模型挖掘知识结构和语义信息的能力。我们在多个文本蕴涵数据集上评估了我们的方法,并表明使用外部知识有助于提高预测准确性。这一点在极具挑战性的BreakingNLI数据集中表现得尤为明显,我们看到在多个基于文本的entailment模型上有5-20%的绝对改进。
成为VIP会员查看完整内容
相关内容

知识图谱(Knowledge Graph),在图书情报界称为知识域可视化或知识领域映射地图,是显示知识发展进程与结构关系的一系列各种不同的图形,用可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识及它们之间的相互联系。
知识图谱是通过将应用数学、图形学、信息可视化技术、信息科学等学科的理论与方法与计量学引文分析、共现分析等方法结合,并利用可视化的图谱形象地展示学科的核心结构、发展历史、前沿领域以及整体知识架构达到多学科融合目的的现代理论。它能为学科研究提供切实的、有价值的参考。
专知会员服务
76+阅读 · 2020年1月16日
专知会员服务
25+阅读 · 2019年11月15日
专知会员服务
49+阅读 · 2019年11月15日
专知会员服务
95+阅读 · 2019年11月8日
Arxiv
23+阅读 · 2019年11月5日
Arxiv
3+阅读 · 2019年1月3日
Arxiv
4+阅读 · 2018年6月25日
相关主题




相关VIP内容
专知会员服务
76+阅读 · 2020年1月16日
专知会员服务
25+阅读 · 2019年11月15日
专知会员服务
49+阅读 · 2019年11月15日
专知会员服务
95+阅读 · 2019年11月8日
相关资讯
相关论文
Arxiv
23+阅读 · 2019年11月5日
Arxiv
3+阅读 · 2019年1月3日
Arxiv
4+阅读 · 2018年6月25日