CMU最新《可信赖强化学习》综述为可信的RL的鲁棒性、安全性和可泛化性提供一个统一的框架。

一个可信的强化学习算法应该能够解决具有挑战性的现实世界问题,包括鲁棒地处理不确定性,满足安全约束以避免灾难性故障,以及在部署过程中泛化到未见过的场景。考虑到可信强化学习在鲁棒性、安全性和泛化性等方面的内在脆弱性,对可信强化学习的主要研究方向进行了综述。特别地,我们给出了严格的公式,分类了相应的方法,并讨论了每个视角的基准。此外,我们还提供了一个展望部分,通过对考虑到人类反馈的外部漏洞的简要讨论来促进有希望的未来方向。我们希望这项综述能将不同的研究线索整合到一个统一的框架中,促进强化学习的可信性。
https://www.zhuanzhi.ai/paper/03e8a85b822658f3d9de0c2b3d84d958
强化学习(RL)[173]具有解决世界上一些最紧迫问题的巨大潜力,被应用于交通[68]、制造[133]、安全[75]、医疗[211]和世界饥饿[44]。随着RL开始转向在现实问题上的部署,它的快速发展伴随着风险和回报[3,42,161]。在消费者接受rl授权的服务之前,研究人员的任务是证明他们创新的可信性。
针对内在漏洞的可信RL概览图:鲁棒性、安全性、泛化性
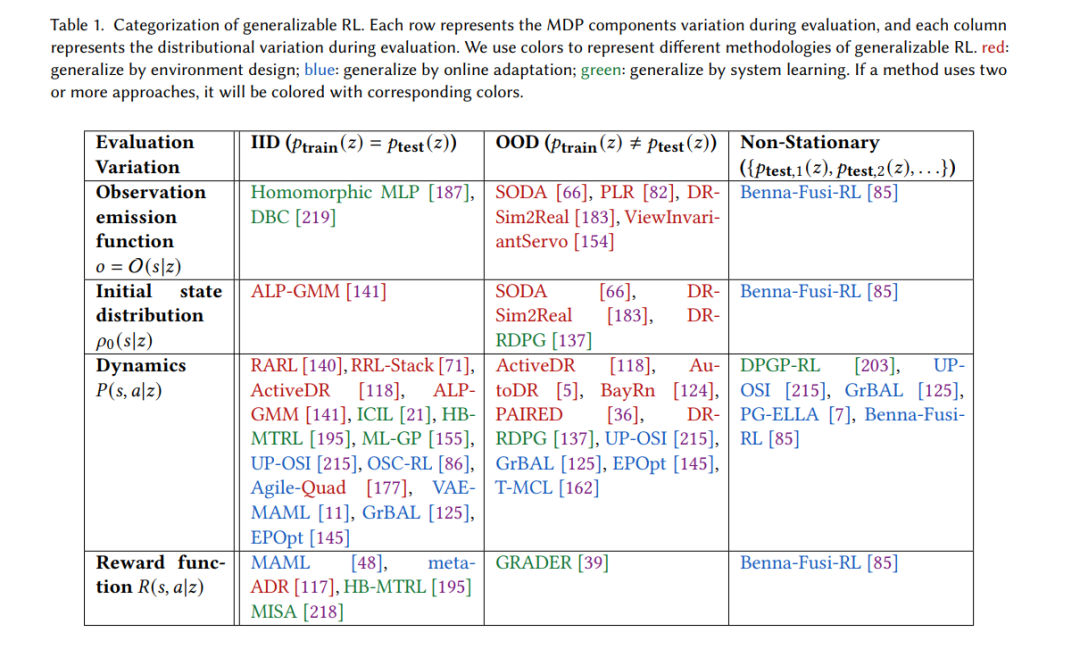
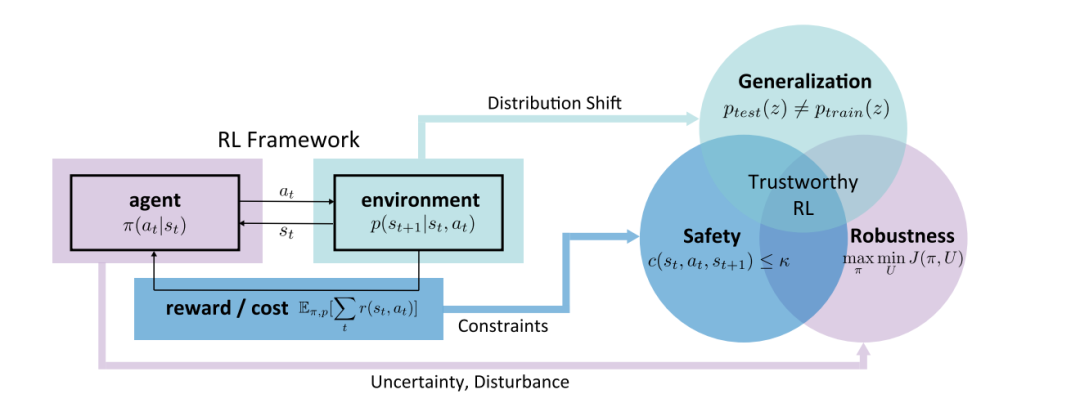
可信度是为了最大化人工智能系统的利益,同时最小化它们的风险[3]。它有超出其字面意义的丰富含义,并激发了一个包括多种原则、要求和标准[3]的综合框架。最近,可信的RL领域取得了令人振奋的进展[2,5,48,107,108,121,129,137,140,145,148,165,171,201],这极大地促进了我们对可信的RL的内在漏洞和特定方面的潜在解决方案的理解。很明显,迈向值得信赖的RL的下一个飞跃将需要对这些问题的挑战、现有值得信赖的RL方法的弱点和优点进行全面和根本的理解,并在现有工作的基础上对值得信赖的RL进行范式转变。与传统机器学习(ML)中的可信性问题相比,强化学习中的问题要复杂几个数量级,因为强化学习是一个多方面的系统,包含多个马尔可夫决策过程(MDP)组件(观察、环境动态、行动和奖励)[173]。值得注意的是,这些组件可能受到不同的鲁棒性、安全性、泛化和安全方面的考虑,这些在传统的ML中已经或没有考虑过。比较静态的部分(例如,观察)中的考虑可以在ML研究中找到根源,而那些与系统交互特性更相关的部分(例如,动作)是RL所独有的,研究较少。此外,当将RL看作两个阶段(模型训练之后是模型部署)时,我们可以单独研究两个阶段的漏洞以及它们之间的联系。 为了促进该领域的发展,本文从MDP的四个要素和两个阶段三个方面对可信RL进行了全面的考察。
扰动和不确定性的鲁棒性, RL的安全性,以限制破坏性成本,以及 泛化到域内和域外未见过的环境。
对于具有强互连的智能体来说,这些要求通常是同时需要的。以自动驾驶汽车为例,具体阐述了可信度的三个方面。首先,自动驾驶汽车的观察结果容易受到对手干扰相机或激光雷达输入的影响,在训练自动驾驶汽车时,环境动力学和奖励可能被毒化,执行部署的良性策略时,执行器也可能被对手操纵。关于两个阶段及其连接,在训练过程中,希望安全探索,使汽车不会发生碰撞;在部署过程中,还应遵守安全约束,以避免危险后果。此外,还需要从自动驾驶汽车的训练环境到测试环境进行良好的泛化。AV应该在不同的城市、不同的天气和季节之间进行泛化。
尽管可信度存在这些相互关联的方面,但现有的调查主要集中在有限的部分。García等[52]、Gu等[62]和Brunke等[25]研究安全RL,而Moos等[121]和Kirk等[88]分别关注鲁棒性和泛化。它们通过提供值得信任的RL的一个方面的具体描述来推进该领域,但是缺乏我们前面所设想的对RL内在弱点的全面描述。在本次综述中,我们希望为可信的RL的三个方面提供一个统一的框架。对于每个方面,我们将1)阐明术语,2)分析它们的内在漏洞,3)介绍解决这些漏洞的方法,4)总结流行的基准测试。如图1所示,鲁棒性、安全性和泛化性与智能体、环境、奖励和成本有很强的相关性,这些与MDP的组成部分相对应。为了在读者容易理解的范围内,我们将综述限制在MDP设置中。本文将该综述视为RL固有的可信方面,因为我们假设人类的偏好和智能体和环境的设置是预定义的。在展望部分,我们将讨论内在可信性和外在可信性之间的联系。特别地,我们将对四个基本问题进行展望
如何认证和评估值得信赖的强化学习? 可信度的不同方面之间有什么关系? 如何与物理智能体和环境共同设计可信的RL ? 如何实现以人为本的值得信赖的RL设计?
我们希望这项综述将把不同的研究线索汇集在一个统一的框架中,并激发新的研究,以全面了解值得信赖的强化学习的内在方面。调查的其余部分组织如下。从第2节到第4节,每一节都涉及可信性的一个方面。我们将在第5节解释我们对调查之外的未来方向的关键挑战的三个方面的展望。我们将在第6节中总结10个结论。
鲁棒强化学习
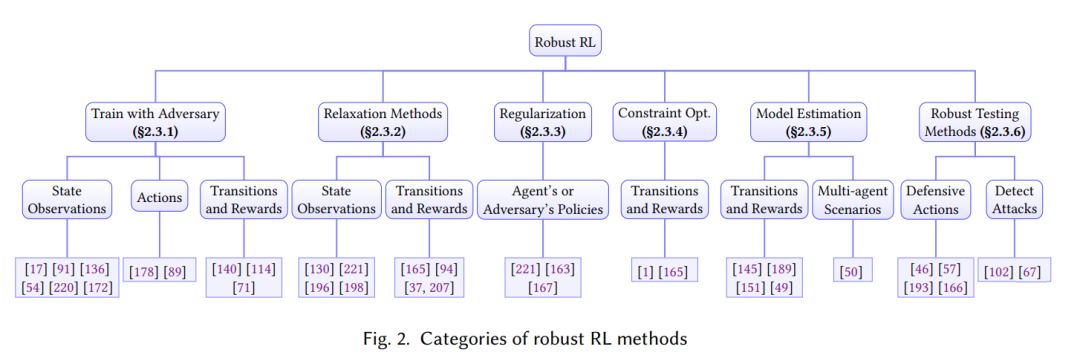
鲁棒强化学习旨在确定性地或统计地提高算法在面对不确定性和对抗性攻击时的最差性能。训练任务和测试任务之间的差异普遍存在。例如,在连续控制任务中,真实的物理参数可能与仿真中不同,而在自动驾驶场景中,周围的智能体可能具有新颖的驾驶行为。这种差异促进了鲁棒RL的发展。此外,现实世界应用程序的安全关键特性使得鲁棒性成为帮助避免灾难性故障的重要特性。研究RL中有效的攻击和防御的兴趣激增。这两个领域的详细综述可在[28,76,121]中找到。在本节中,我们首先从不同MDP组件(包括观察/状态、操作、转换和奖励)对不确定性的鲁棒性方面总结第2.2节中的鲁棒性RL公式。然后,我们在第2.3节中提出了鲁棒训练和测试方法,以提高对每个组件的不确定性或人为设计的攻击的鲁棒性。我们在图2中总结了鲁棒RL方法。最后,我们在第2.4节中介绍了用于测试所提议的鲁棒RL算法的鲁棒性的应用程序和基准。
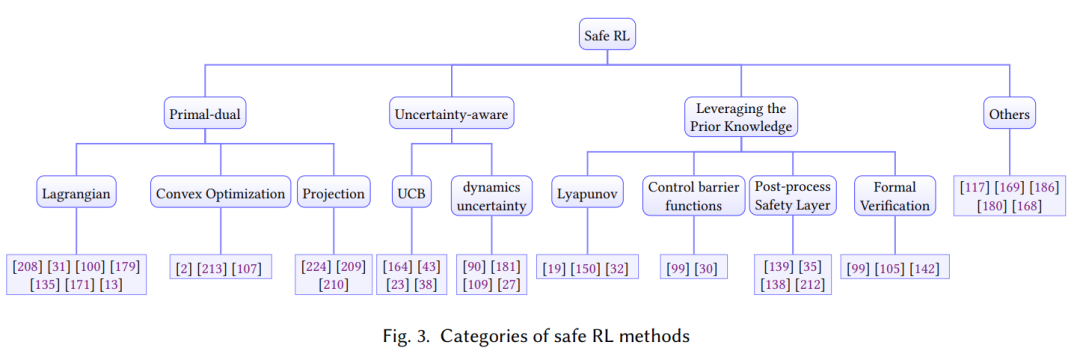
安全强化学习
在将它们部署到现实世界的安全关键应用程序(如自动驾驶汽车)时,安全性也是另一个主要问题。传统的强化学习只关注从环境中获得的任务奖励最大化,缺乏满足安全约束的保证。安全的策略应该明确考虑训练期间的安全约束,并防止强化学习智能体造成破坏性成本或处于危险状态。例如,如果将RL算法部署在真实的机器人手臂上,安全约束将是避免碰撞脆弱的物体和周围的人,这可能会破坏宝贵的财产或造成伤害。类似地,自动驾驶应用中的RL智能体应该遵守交通规则,并避免与周围障碍物的碰撞。因此,为现实世界的应用开发安全的强化学习算法是很重要的,这些算法允许它们在满足一定的安全约束的情况下完成任务。安全强化学习又称约束强化学习,其目的是在满足安全约束条件的情况下,学习最大化预期任务奖励的策略。根据安全要求和训练要求,safe RL有不同的配方。在安全要求方面,有轨迹方面的安全约束和状态方面的安全约束。从训练需求的角度,我们可以将安全的RL分为两类:安全部署和安全探索,安全部署的目的是在模型训练结束后安全行动,但在训练过程中可能会违反约束;安全部署是指在训练过程中提供安全保障,使整个训练过程能够完成,而不会造成灾难性的不安全行为。注意在RL设置中,智能体需要从故障中学习,在安全RL设置中类似。有人可能会说,我们应该始终使用领域知识而不是主动学习来避免任何安全关键故障。然而,在这项调查中,我们发现在许多情况下,对环境风险的精确描述是不可用的。这也是我们既要注意安全部署,又要注意安全探索,管理风险的原因。
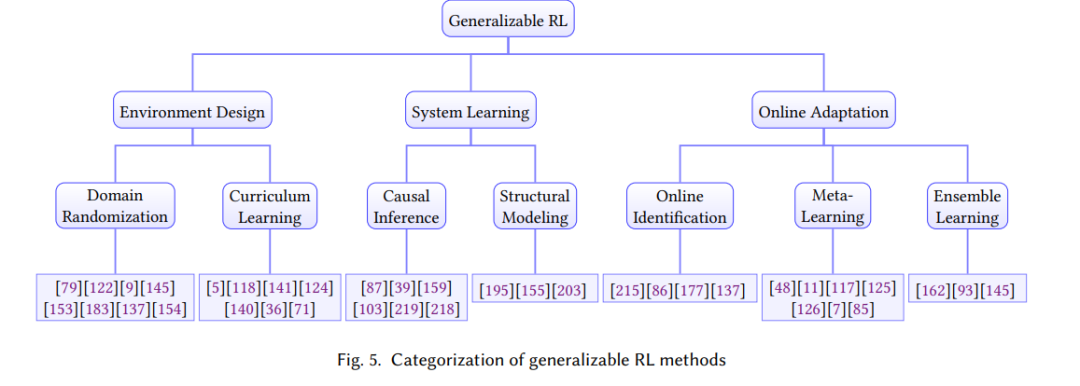
强化学习泛化性
强化学习中的泛化侧重于设计算法,以产生可以迁移或适应各种环境的策略,而不会对训练环境过度拟合。这种能力对于现实生活中RL智能体的部署至关重要,因为测试时的环境通常不同于训练环境,或者本质上是动态的。现有的一些调查根据他们的方法[88,188,225]对RL泛化研究进行了分类。然而,在本次调查中,我们采用了一种不同的方法,根据他们的评价变化进行分类。