「深度学习模型鲁棒性」最新2022综述
深度学习模型鲁棒性最新综述论文

摘要
引言
受益于计算力和智能设备的飞速发展,全世界正在经历第三次人工智能浪潮。人工智能以计算机 视觉、序列处理、智能决策等技术为核心在各个应 用领域展开,并延伸到人类生活的方方面面,包括 自适应控制[1]、模式识别[2]、游戏[3]以及自动驾驶[4] 等安全攸关型应用。例如,无人驾驶飞机防撞系统 (Aircraft Collision Avoidance System, ACAS)使用 深度神经网络根据附近入侵者飞机的位置和速度 来预测最佳行动。然而,尽管深度神经网络已经显 示出解决复杂问题的有效性和强大能力,但它们仅 限于仅满足最低安全完整性级别的系统,因此它们 在安全关键型环境中的采用仍受到限制,主要原因 在于在大多数情况下神经网络模型被视为无法对 其预测行为进行合理解释的黑匣子,并且在理论上难以证明其性质。

随着深度学习的对抗攻击领域日益广泛,对抗 样本的危险性日益凸显[7,12,13],即通过向正常样例中添加精细设计的、人类无法感知的扰动达到不干 扰人类认知却能使机器学习模型做出错误判断。以图像分类任务为例,如图 1 所示,原始样本以 57.7% 的置信度被模型分类为“熊猫”,而添加对抗扰动之 后得到的样本则以 99.3%的置信度被错误地分类为 “长臂猿”,然而对于人而言,对抗样本依然会被 视为熊猫。由于这种细微的扰动通常是人眼难以分辨的,因而使得攻击隐蔽性极强、危害性极大,给 ACAS 等安全攸关型应用中部署的深度学习模型带 来了巨大的安全威胁。
为了防御对抗样本攻击,研究者进行了一系列的防御方法探索[5-11]。然而,即使是被广泛认可并且迄今为止最成功的ℓ∞防御[5],它的ℓ0鲁棒性比未防御的网络还低,并且仍然极易受到ℓ2的扰动影响[14]。这些结果表明,仅对对抗攻击进行经验性的防御无法保证模型的鲁棒性得到实质性的提升,模型的鲁棒性需要一个定量的、有理论保证的指标进行评估。因此,如果要将深度学习模型部署到诸如自 动驾驶汽车等安全攸关型应用中,我们需要为模型 的鲁棒性提供理论上的安全保证,即计算模型的鲁 棒性边界。模型鲁棒性边界是针对某个具体样本而 言的,是保证模型预测正确的条件下样本的最大可 扰动范围,即模型对这个样本的分类决策不会在这 个边界内变化。具体地,令输入样本𝑥的维度为𝑑, 输出类别的个数为𝐾,神经网络模型为𝑓: ℝ𝑑 → ℝ𝐾, 输入样本的类别为 𝑐 = 𝑎𝑟𝑔𝑚𝑎𝑥 𝑓𝑗 𝑥 ,𝑗 = 1,2, … ,𝐾,在ℓ𝑝空间假设下,模型对𝑥提供ϵ-鲁棒性 保证表明模型对𝑥的分类决策不会在这个样本ℓ𝑝空 间周围ϵ大小内变化。
在本文中,我们首先阐述了深度学习模型鲁棒性分析现存的问题与挑战,然后从精确与近似两个角度对现有的鲁棒性分析方法进行系统的总结和科学的归纳,并讨论了相关研究的局限性。最后,我们讨论了深度学习模型鲁棒性分析问题未来的研究方向。
问题与挑战
目前,深度神经网络的鲁棒性分析问题的挑战主要集中在以下几个方面:
(1)神经网络的非线性特点。由于非线性激 活函数和复杂结构的存在,深度神经网络具有非线 性、非凸性的特点,因此很难估计其输出范围,并 且验证分段线性神经网络的简单特性也已被证明 是 NP 完全问题[15]。这一问题的难点在于深度神经 网络中非线性激活函数的存在。具体地,深度神经 网络的每一层由一组神经元构成,每个神经元的值 是通过计算来自上一层神经元的值的线性组合,然 后将激活函数应用于这一线性组合。由于这些激活 函数是非线性的,因此这一过程是非凸的。以应用 最为广泛的激活函数 ReLU 为例,当 ReLU 函数应 用于具有正值的节点时,它将返回不变的值,但是 当该值为负时,ReLU 函数将返回 0。然而,使用 ReLU 验证 DNN 属性的方法不得不做出显著简化 的假设,例如仅考虑所有 ReLU 都固定为正值或 0 的区域[16]。直到最近,研究人员才能够基于可满足 性模理论等形式方法,对最简单的 ReLU 分段线性 神经网络进行了初步验证[15,21]。由于可满足性模理 论求解器难以处理非线性运算,因此基于可满足性 模理论的方法通常只适用于激活函数为分段线性的神经网络,无法扩展到具有其它类型激活函数的神经网络。
(2)神经网络的大规模特点。在实际应用中, 性能表现优秀的神经网络通常具有大规模的特点。因此,尽管每个 ReLU 节点的线性区域可以划分为 两个线性约束并有效地进行验证,但是由于线性片 段的总数与网络中节点的数量成指数增长[17,18],对 整个网络进行精确验证是非常困难的。这是因为对 于任何大型网络,其所有组合的详尽枚举极其昂 贵,很难准确估计输出范围。此外,基于可满足性 模理论的方法严重受到求解器效率的限制,仅能处 理非常小的网络(例如,只有 10 到 20 个隐藏节点 的单个隐藏层[20]),无法扩展到大多数现实世界中 的大型网络,而基于采样的推理技术(例如黑盒蒙 特卡洛采样)也需要大量数据才能在决策边界上生 成严格的准确边界[19]。
总之,由于不同学者所处的研究领域不同,解 决问题的角度不同,所提出的鲁棒性分析方法也各 有侧重,因此亟需对现有的研究工作进行系统的整 理和科学的归纳、总结、分析。典型的模型鲁棒性 分析方法总结如表 1 所示。目前的模型鲁棒性分析 方法主要分为两大类:(1)精确方法:可以证明精 确的鲁棒性边界,但计算复杂度高,在最坏情况下 计算复杂度相对于网络规模是成指数增长的,因此 通常只适用于极小规模的神经网络;(2)近似方法:效率高、能够扩展到复杂神经网络,但只能证明近似的鲁棒性边界。
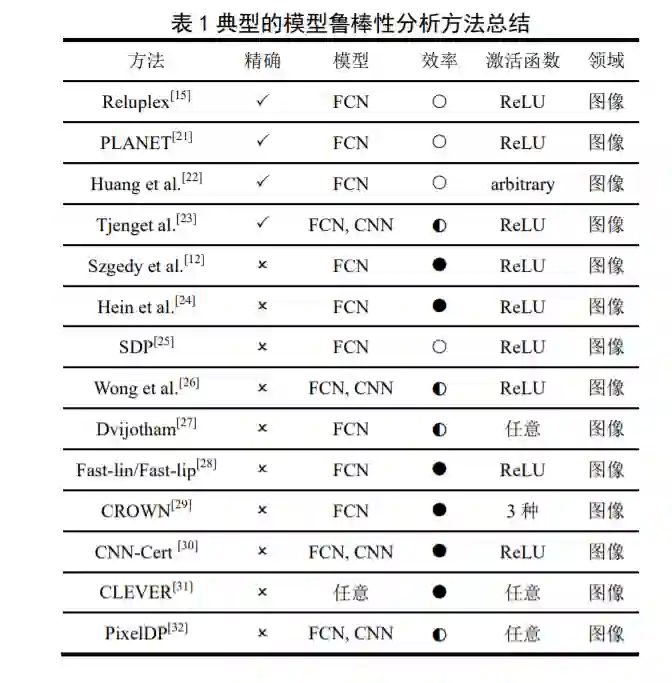

精确方法
精确方法主要是基于离散优化 (DiscreteOptimization)理论来形式化验证神经网 络中某些属性对于任何可能的输入的可行性,即利 用可满足性模理论(Satisfiability Modulo Theories, SMT)或混合整数线性规划(Mixed Integer Linear Programming, MILP)来解决此类形式验证问题。这 类方法通常是通过利用 ReLU 的分段线性特性并在 搜索可行解时尝试逐渐满足它们施加的约束来实 现的。图 2 梳理了典型模型鲁棒性精确分析方法的 相关研究工作。

近似方法
由于在ℓ𝑝 − 𝑏𝑎𝑙𝑙假设空间内,对于激活函数为 ReLU 的神经网络,计算其精确的鲁棒性边界是一 个 NP 完备(NP-Complete,NPC)问题[15],因此大 多数研究者通常利用近似方法计算模型鲁棒性边 界的下界,下文提到模型鲁棒性边界时通常也指的 是这个下界。此外,对抗攻击[12]可以得到模型鲁棒 性边界的上界[24]。因此,精确的模型鲁棒性边界可 以由上界和下界共同逼近。这类方法通常基于鲁棒 优化思想,通过解决公式(1)的内层最大化问题 来估计模型鲁棒性边界:
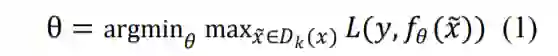
其中,𝑥代表正常样本,𝑥 代表对抗样本,𝐷𝑘 (𝑥)代 表对抗样本可能存在的范围,𝑦代表样本真实标签, 𝑓𝜃代表以θ为参数的模型,𝐿代表损失函数。图 3 梳 理了典型模型鲁棒性近似分析方法的相关研究工 作。


未来研究方向
本文介绍了模型鲁棒性分析问题的背景与挑战,探讨了相关定义,进而对目前主流的模型鲁棒性方法与性能做了介绍。从目前已有的相关方法来 看,我们认为今后对模型鲁棒性分析方法的研究, 将主要围绕以下几个方向展开:
(1)进一步拓展对抗扰动的类型。从攻击者 添加扰动的类型来看,现存的大多数模型鲁棒性方 法都是针对在像素点上添加扰动的对抗攻击进行 的鲁棒性分析,然而在实际中,对抗性图像有可能 经过旋转、缩放等几何变换,而现存大多数方法无 法扩展到此类变换。虽然 Balunovic 等人提出的 DeepG[102]初步尝试了将抽象解释的思想用于分析 几何变换对抗攻击的模型鲁棒性空间,但是这个方 向仍然值得更多深入研究,进一步提升精度和可扩展性。
(2)不同鲁棒性类型之间的平衡。输入样本𝑥 的局部鲁棒性(即神经网络应为以𝑥为中心的半径 为ϵ的球中的所有输入产生相同的预测结果)依赖 于在输入空间上定义的合适的距离度量标准,在实 际中,对于在非恶意环境中运行的神经网络而言, 这可能是太过苛刻的要求。同时,由于仅针对特定 输入定义了局部鲁棒性,而对于未考虑的输入不提 供保证,因此局部鲁棒性也具有固有的限制性。全 局鲁棒性则通过进一步要求输入空间中的所有输 入都满足局部鲁棒性来解决这个问题。除了在计算 上难以控制之外,全局鲁棒性仍然太强而无法实际 使用。因此,在实际中如何更好地平衡局部鲁棒性 与全局鲁棒性,仍然是一个亟待解决的挑战。
(3)进一步提升模型鲁棒性验证方法。从实 证结果来看,大多数基于经验的防御方法非常容易 被更强的攻击所攻破,而其他鲁棒性分析方法在很 大程度上取决于神经网络模型的体系结构,例如激 活函数的种类或残差连接的存在。相比之下,随机 平滑不对神经网络的体系结构做任何假设,而仅依 靠在噪声假设下传统模型进行良好决策的能力,从 而将鲁棒分类问题扩展为经典监督学习问题,可用 于社区检测[103]等任务。因此,基于随机平滑的鲁 棒性分析方法可能是研究模型鲁棒空间的最有前 途的方向之一。此外,由于基于概率的方法具有更 宽松的鲁棒性定义,更有可能被实用的神经网络所 满足和验证,因此在合适的扰动分布假设下也是较 有前景的方向之一。
(4)研究可证明鲁棒模型训练方法。此外, 如何训练对对抗性扰动具有可证明鲁棒的神经网 络以及如何训练更容易验证鲁棒性的神经网络,也 是未来的研究方向之一。目前研究者在这个方向进 行的初步探索包括利用正则化技术将模型的形式 化鲁棒边界与模型的目标函数结合起来[104]、经验 性对抗风险最小化(Empirical Adversarial Risk Minimization,EARM)[36,105]、随机自集成[106]、剪 枝[82,107]以及改善神经网络的稀疏性[108]。但是现存 技术主要集中于图像领域,难以扩展到恶意软件等 安全攸关型应用,并且仍然存在精度以及可扩展性 上的不足,需要进一步的深入研究。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“DLCM” 就可以获取《「深度学习模型鲁棒性」最新2022综述》专知下载链接




