什么是因果机器学习?UCL&牛津大学最新《因果机器学习》书册,165页pdf阐述因果机器学习体系
因果性是现在机器学习关注的焦点之一。伦敦大学学院和牛津大学的学者发布了《因果机器学习》综述,非常值得关注!

https://www.zhuanzhi.ai/paper/115ede7bdf331e6ac4f725900ec23c38


-
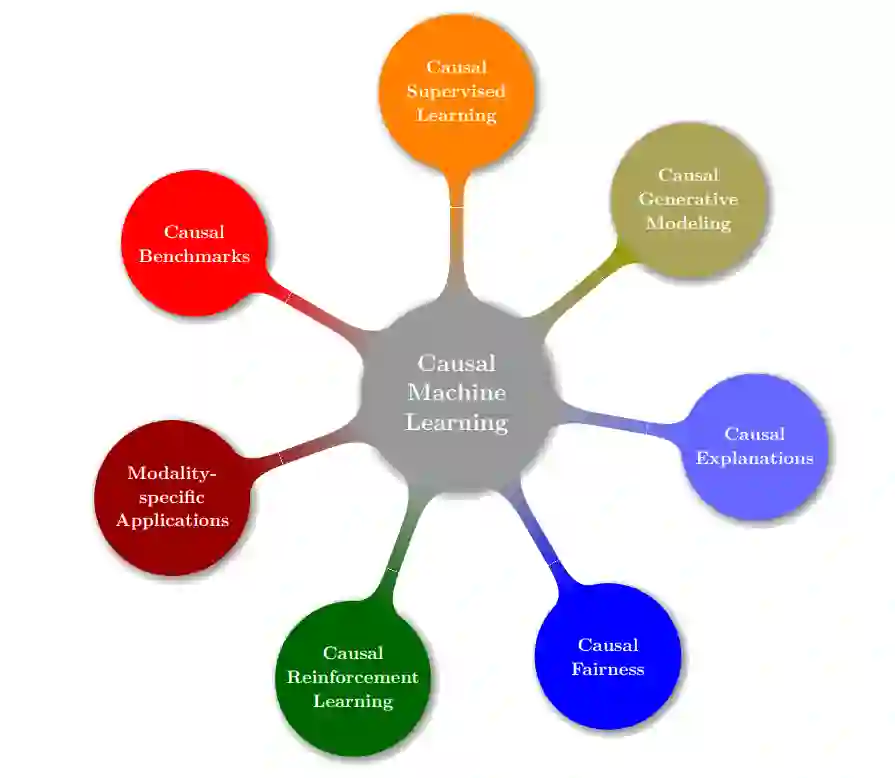
因果推理(第二章),与统计或概率推理相反,允许我们对介入和反事实的估计进行推理。
-
因果监督学习(第3章)通过学习不变特征或机制来改进预测泛化,两者都旨在消除模型对虚假关联的依赖。未来的工作应该研究学习不变性的目标基准测试、对抗鲁棒性的联系以及元学习,以及额外监督信号的潜在利用。 -
因果生成模型(第4章)支持从介入的或反事实的分布中采样,自然地分别执行原则可控的生成或样本编辑任务。所有现有的方法都学习结构作业;一些人还从数据中推断出因果结构。对于不同的应用程序应该考虑什么层次的抽象,如何将分配学习扩展到更大的图,以及反事实生成的数据增强何时有效(何时无效),这些都有待探索。 -
因果解释(第5章)解释模型预测,同时解释模型机制或数据生成过程的因果结构。方法可以分为特征归因(量化输入特征的因果影响)和对比解释(表示获得期望结果的改变实例)。到目前为止,还不清楚如何最好地统一这两类方法,扩大解释范围,使它们对分布转移具有鲁棒性,对攻击者安全和私有,以及如何规避不可避免的对追索敏感性的鲁棒性权衡。 -
因果公平(第6章)为评估模型的公平性以及减轻潜在数据因果关系的有害差异的标准铺平了道路。该标准依赖于反事实或介入性分布。未来的工作应该阐明在标准预测设置之外的平等、公平、较弱的可观察性假设(例如隐藏的混淆)以及对社会类别的干预主义观点的有效性。 -
因果强化学习(第7章)描述了考虑决策环境的显性因果结构的RL方法。我们将这些方法分为7类,并观察到它们比非因果方法的好处包括反发现(导致更好的泛化)、内在奖励和数据效率。开放的问题表明,一些形式主义可能是统一的,离线数据的反发现在离线RL部分很大程度上没有解决,而代理根据反事实做出的决定可能会提供进一步的好处。 -
模态-应用:我们回顾了之前介绍的和模态特定原则如何提供机会来改善计算机视觉、自然语言处理和图形表示学习设置。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“C165” 就可以获取《什么是因果机器学习?UCL&牛津大学最新《因果机器学习》书册,165页pdf阐述因果机器学习体系》专知下载链接



登录查看更多
相关内容


相关VIP内容
相关资讯
相关论文