
因果性是现在机器学习关注的焦点之一。伦敦大学学院和牛津大学的学者发布了《因果机器学习》综述,非常值得关注!

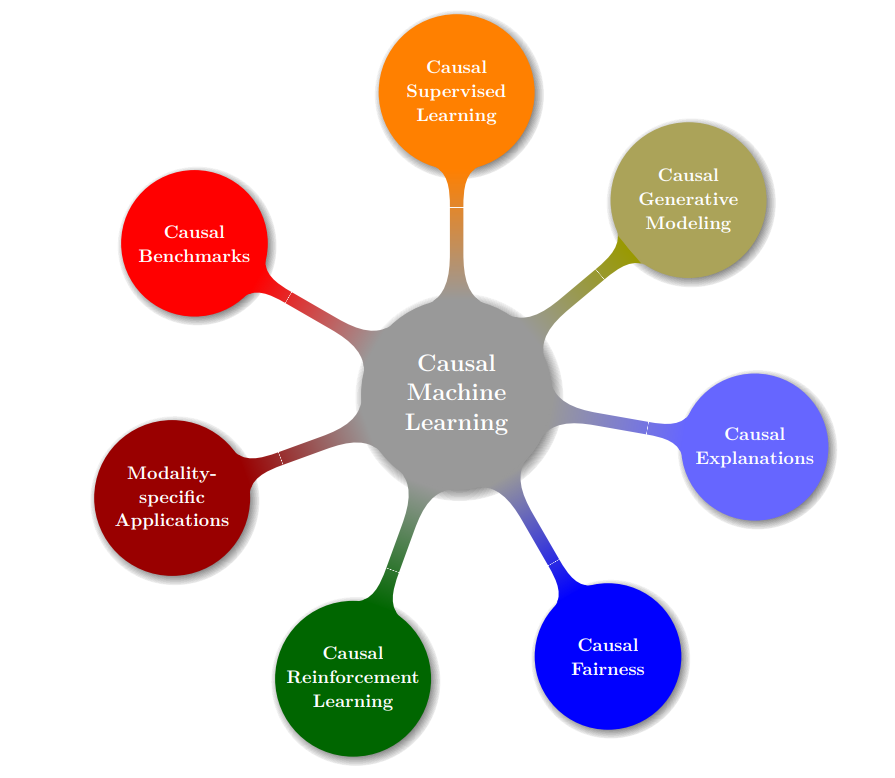
因果机器学习(CausalML)是将数据生成过程形式化为结构因果模型(SCM)的机器学习方法的总称。这使得人们可以对这一过程的变化的影响(即干预)和事后会发生什么(即反事实)进行推理。根据他们所解决的问题,我们将CausalML中的工作分为五组:(1)因果监督学习,(2) 因果生成模型,(3) 因果解释,(4) 因果公平,(5) 因果强化学习。对每一类方法进行了系统的比较,并指出了有待解决的问题。此外,我们回顾了特定模式在计算机视觉、自然语言处理和图形表示学习中的应用。最后,我们提供了因果基准的概述,并对这一新兴领域的状态进行了批判性的讨论,包括对未来工作的建议。
引言
机器学习(ML)技术今天擅长在独立和同分布(i.i.d)数据中寻找关联。一些基本原则,包括经验风险最小化、反向传播和架构设计中的归纳偏差,已经为解决计算机视觉、自然语言处理、图表示学习和强化学习等领域的问题带来了巨大的进步。然而,在将这些模型部署到现实环境中时,出现了新的挑战。这些挑战包括: (1) 当数据分布转移[1]时泛化性能大幅下降,(2) 生成模型[2]样本缺乏细粒度控制,(3) 有偏见的预测强化了某些子种群的不公平歧视[3,4],(4) 可解释性[5]的概念过于抽象和问题独立,(5)强化学习方法对真实世界问题[6]的不稳定转换。
许多工作认为,这些问题的部分原因在于现代ML系统缺乏因果形式主义[7,8,9,10,11]。随后,研究社区对因果机器学习(CausalML)的兴趣激增,这是利用关于被建模系统的因果知识的方法本调查涵盖了因果关系如何被用来解决开放式ML问题。简而言之,因果推理提供了一种语言,通过结构因果模型(SCMs)[12]将关于数据生成过程(DGP)的结构知识形式化。使用SCM,我们可以估计在对数据生成过程进行更改(称为干预)后,数据会发生什么变化。更进一步,它们还允许我们在事后模拟变化的后果,同时考虑实际发生的情况(称为反事实)。我们将在第2章中更详细地介绍这些概念,假设没有因果关系的先验知识。
尽管在设计各种类型的CausalML算法方面做了大量的工作,但仍然缺乏对其问题和方法论的明确分类。我们认为,部分原因在于CausalML通常涉及对大部分ML不熟悉的数据的假设,这些假设在不同的问题设置之间联系起来通常很棘手,这使得很难衡量进展和适用性。这些问题是本次综述的动机。


**1. 我们对完全独立的因果关系中的关键概念进行了简单的介绍(第2章)。**我们不假设对因果关系有任何先验知识。在整个过程中,我们给出了如何应用这些概念来帮助进一步的地面直觉的例子。
2. 我们将现有的CausalML工作分类为因果监督学习(第3章)、因果生成模型(第4章)、因果解释(第5章)、因果公平(第6章)、因果强化学习(第7章)。对于每个问题类,我们比较现有的方法,并指出未来工作的途径。
3.我们回顾了特定模式在计算机视觉、自然语言处理和图表示学习中的应用(第8章),以及因果基准(第9章)。
4. 我们讨论了好的、坏的和丑陋的:我们关于与非因果ML方法相比,因果ML可以给我们带来哪些好处的观点(好的),人们必须为这些方法付出什么代价(坏的),以及我们警告从业者要防范哪些风险(丑陋的)(第10章)。
结论发现**
- 因果推理(第二章),与统计或概率推理相反,允许我们对介入和反事实的估计进行推理。
- 因果监督学习(第3章)通过学习不变特征或机制来改进预测泛化,两者都旨在消除模型对虚假关联的依赖。未来的工作应该研究学习不变性的目标基准测试、对抗鲁棒性的联系以及元学习,以及额外监督信号的潜在利用。
- 因果生成模型(第4章)支持从介入的或反事实的分布中采样,自然地分别执行原则可控的生成或样本编辑任务。所有现有的方法都学习结构作业;一些人还从数据中推断出因果结构。对于不同的应用程序应该考虑什么层次的抽象,如何将分配学习扩展到更大的图,以及反事实生成的数据增强何时有效(何时无效),这些都有待探索。
- 因果解释(第5章)解释模型预测,同时解释模型机制或数据生成过程的因果结构。方法可以分为特征归因(量化输入特征的因果影响)和对比解释(表示获得期望结果的改变实例)。到目前为止,还不清楚如何最好地统一这两类方法,扩大解释范围,使它们对分布转移具有鲁棒性,对攻击者安全和私有,以及如何规避不可避免的对追索敏感性的鲁棒性权衡。
- 因果公平(第6章)为评估模型的公平性以及减轻潜在数据因果关系的有害差异的标准铺平了道路。该标准依赖于反事实或介入性分布。未来的工作应该阐明在标准预测设置之外的平等、公平、较弱的可观察性假设(例如隐藏的混淆)以及对社会类别的干预主义观点的有效性。
- 因果强化学习(第7章)描述了考虑决策环境的显性因果结构的RL方法。我们将这些方法分为7类,并观察到它们比非因果方法的好处包括反发现(导致更好的泛化)、内在奖励和数据效率。开放的问题表明,一些形式主义可能是统一的,离线数据的反发现在离线RL部分很大程度上没有解决,而代理根据反事实做出的决定可能会提供进一步的好处。
- 模态-应用:我们回顾了之前介绍的和模态特定原则如何提供机会来改善计算机视觉、自然语言处理和图形表示学习设置。
