摘要
强化学习是一种为需要做出一系列决定的任务制定最佳策略的方法。以平衡短期和长期结果的方式做出决定的能力,使强化学习成为医疗机构中规划治疗的潜在强大工具。不幸的是,传统的强化学习算法需要对环境进行随机实验,这在医疗卫生领域通常是不可能的。然而,强化学习提供了从观察数据中评估策略的工具,这是一个被称为离策略评估的子项目。
在这项工作中,我们讨论了离策略评估在应用于医疗数据时变得如此困难的主要挑战,并设计了一些算法来改进目前执行离策略评估的方法。我们描述了几种改进现有方法的准确性和统计能力的算法,最后介绍了一种新的方法,通过开发一种将专家临床医生及其知识纳入评价过程的评价技术来提高离策略评估方法的可靠性。
简介
强化学习(RL)是机器学习(ML)中的一个子领域,它为学习需要平衡短期和长期结果的任务中的连续决策策略提供了一个框架。RL的关键范式是将学习算法视为一个与环境互动的智能体,采取行动并观察环境对这些行动的变化。通过与环境的不断互动和实验,智能体学会了实现预期目标的最佳策略。这个强大的想法促进了RL算法在广泛的应用中的成功,如游戏和机器人。
然而,在这些应用中,与环境的随机互动--使RL如此强大的关键特性--是不可能的。例如,在医疗保健中,随机治疗病人并观察其反应是不道德的。
从批量观察数据中评估RL决策的任务被称为离策略评估(OPE),这个术语用来表示用于收集数据的策略与我们希望评估的策略不同。OPE只关注评估一个特定的策略,而不是学习一个最优的onc,这是大多数RL应用的目标。
这项工作的动力来自于这样的认识:尽管在OPE方面取得了重大的理论突破,但目前的方法仍然远远不够可靠,无法证明其在实际应用中的使用和部署。这些限制在医疗保健领域尤为突出,因为那里的数据非常嘈杂,而且错误的代价很高。 我们首先强调了使OPE在观察性医疗环境中如此困难的关键因素,并展示了这些算法可能失败的主要方式。然后,我们描述了几种改善OPE算法性能的方法。这些方法可以应用于所有RL领域,但我们在医疗数据中经常遇到的具体特征是其强大的动力。
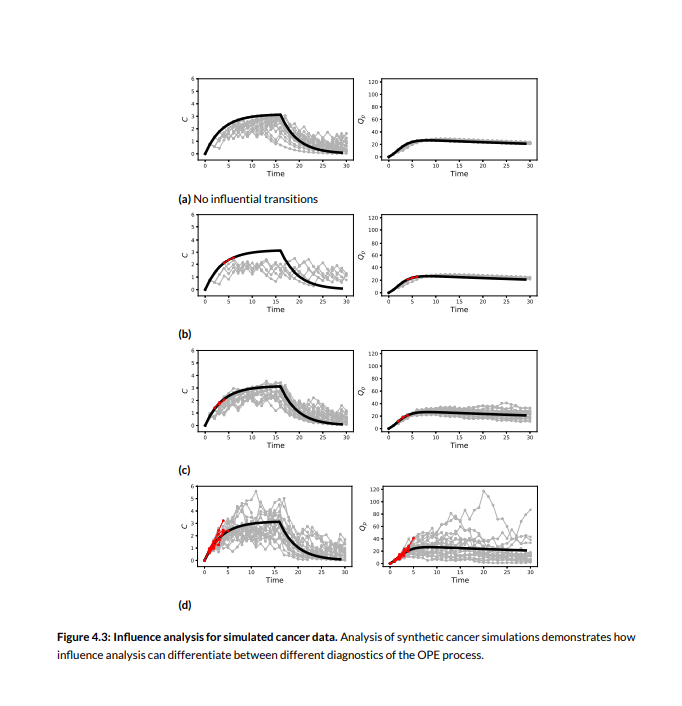
虽然这项工作中所描述的方法有助于提高OPE方法的性能,但它们基本上都试图从数据中提取出更多的统计能力。不幸的是,仅从数据中提取出的知识是有限的,而且往往我们所能做的最好的也是不够好。 然而,试图仅从原始数据中获得知识,却忽视了临床医生和其他医疗专家所拥有的大量知识和专长。在这项工作的最后一部分,我们将论证,为了使OPE的性能足够好,使其能够被信任并用于医疗领域,领域专家必须被纳入评估过程。为了能够在OPE中使用领域专家,必须开发新的方法,使几乎总是不熟悉RL和OPE技术细节的临床医生能够有效地提供对OPE过程有用的意见。我们将在这个方向上迈出一步,描述一种方法,使临床医生能够随意地识别OPE方法何时可能给出不可靠的结果,并讨论发展这一研究途径的未来方向。
总而言之,这项工作应该概述了OPE在医疗领域的状况,以及将其引入现实世界所必须做出的努力--从详细说明当前方法可能失败的方式和解决这些问题的可能方法,到描述临床医生可以被纳入评估过程的方式。本论文的其余部分的结构如下:本章的其余部分介绍了本论文将使用的基本符号,并涵盖了相关文献。 第三章继续讨论基于模型的OPE,并介绍了一种建立模型的方法,该方法的训练强调从评估策略下可能出现的例子中学习,并沿用了Liu等人的工作。最后,在第四章中,我们讨论了如何利用临床医生的输入来调试和验证OPE的结果,沿用了Gottesman等人的方法。