摘要
深度强化学习 (RL) 中的泛化研究旨在产生 RL 算法,其策略可以很好地泛化到部署时新的未知情况,避免过度拟合其训练环境。如果要在现实世界的场景中部署强化学习算法,解决这个问题至关重要,在现实世界中,环境将是多样的、动态的和不可预测的。本综述是对这一新兴领域的概述,在已有研究的基础上,通过提供了一个统一的格式和术语来讨论不同的泛化问题。继续对现有的泛化基准以及解决泛化问题的方法进行分类。最后,对该领域的现状进行了批判性讨论,包括对未来研究的建议。本文认为对基准设计采用纯程序性内容生成方法不利于推广,其建议快速在线适应和解决RL特定问题,并在未充分探索的问题环境中建立基准,如离线RL概括和奖励函数变化。
引言
强化学习(RL)可以用于一系列应用,如自动驾驶汽车[1]和机器人[2],但为了实现这一潜力,我们需要可以在现实世界中使用的RL算法。现实是动态的、开放的、总是在变化的,RL算法需要对其环境的变化具有健壮性,并在部署过程中具有迁移和适应不可见(但类似)环境的能力。
然而,目前许多RL研究工作都是在诸如Atari[3]和MuJoCo[4,5]等基准测试上进行的,这些基准测试不具备上述属性:它们在训练策略时所处的环境中评估策略,这与现实场景不匹配(图1左列)。这与监督学习的标准假设形成了鲜明的对比,在监督学习中,训练集和测试集是不相交的,很可能导致强评估过拟合[6]。这导致策略即使在稍微调整的环境实例(环境中的特定关卡或任务)上表现也很糟糕,并且经常在用于随机初始化上失败[7,8,9,10]。
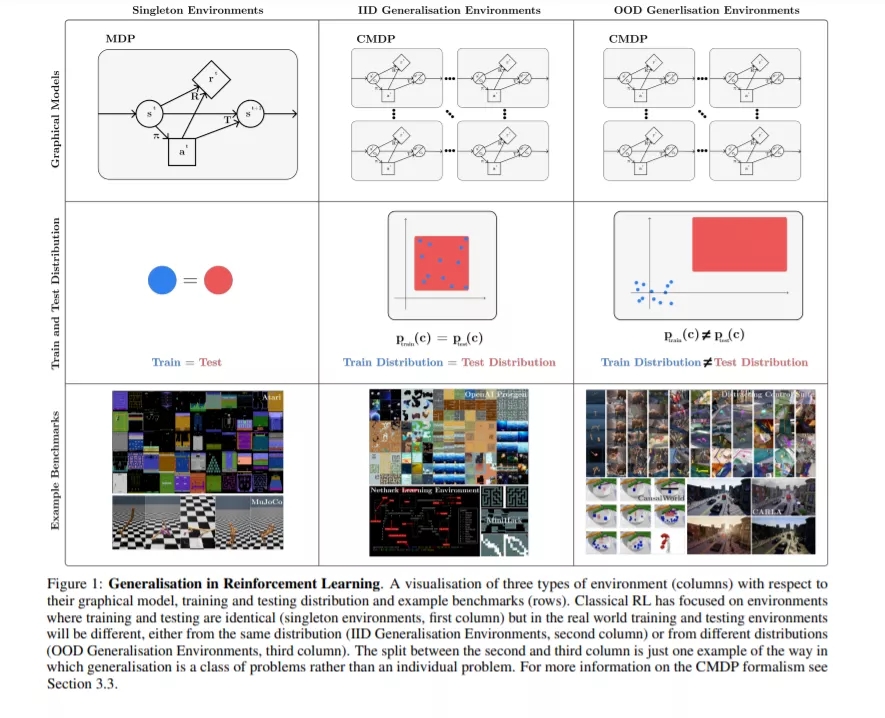
许多研究人员已经认真对待这些批评,现在专注于提高RL的泛化(从这项综述的内容可以看出)。本研究的重点是生成策略具有预期鲁棒性、迁移和自适应特性的算法,挑战训练和测试将是相同的基本假设(图1中右列)。虽然这项研究是有价值的,但目前它经常缺乏清晰或连贯的论文。我们认为,这部分是因为泛化(尤其是在RL中)是一类问题,而不是一个特定的问题。改进“泛化”,但不明确需要哪种泛化,这是不明确的;我们不太可能从总体上改进泛化,因为这类问题太广泛了,以至于适用于一些类似于No Free Lunch定理[11]的类比:在某些情况下改进泛化可能会损害在其他情况下的泛化。图1中右两栏显示了两大类泛化问题。
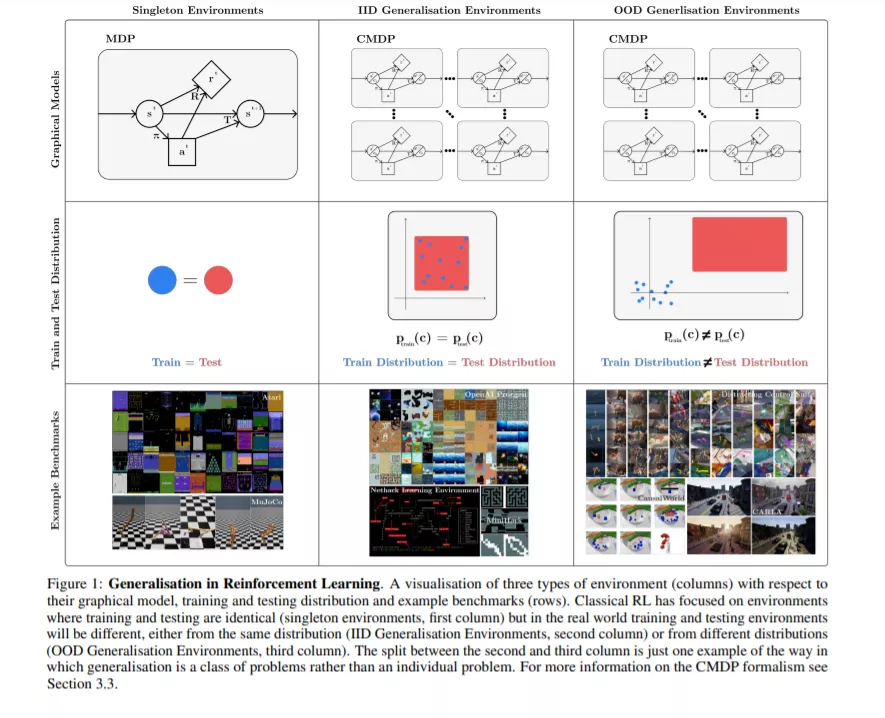
我们将泛化概念作为一个单一的问题来解决。我们提出了一种理解这类问题的形式化(建立在以前的工作[12,13,14,15,16]),以及在指定一个泛化问题时有哪些选择。这是基于特定基准所做出的选择,以及为验证特定方法而做出的假设,我们将在下面讨论这些。最后,我们在泛化中提出了一些尚未被探索的设置,但对于RL的各种现实应用仍然至关重要,以及未来在解决不同泛化问题的方法上的许多途径。我们的目标是使该领域的研究人员和实践者在该领域内外更容易理解,并使讨论新的研究方向更容易。这种新的清晰性可以改善该领域,并使更通用的RL方法取得稳健的进展。
综述结构。综述的结构如下。我们首先在第2节中简要描述相关工作,如其他概述。在第3节中,我们介绍了RL中泛化的形式化和术语,包括相关的背景。然后,在第4节中,我们继续使用这种形式化来描述用于RL泛化的当前基准,讨论环境(第4.1节)和评估协议(第4.2节)。我们将在第5节中对处理泛化的工作产生方法进行分类和描述。最后,我们将在第6节中对当前领域进行批判性的讨论,包括在方法和基准方面对未来工作的建议,并在第7节中总结综述的关键结论。
-
我们提出了关于泛化的一种形式主义和术语,这是建立在以往多部工作[12,13,14,15,16]中提出的形式主义和术语基础上的。我们在这里的贡献是将这些先前的工作统一为RL中被称为泛化的一类问题的清晰的正式描述。
-
我们提出了一个现有基准的分类,可以用来进行泛化测试,将讨论分为分类环境和评估协议。我们的形式主义让我们能够清楚地描述纯粹的PCG方法在泛化基准和环境设计方面的弱点:拥有一个完全的PCG环境限制了在该环境下进行研究的精确度。我们建议未来的环境应结合PCG和可控变异因素。
-
我们提出现有的分类方法来解决各种泛化问题,出于希望使它容易对从业人员选择的方法给出一个具体的问题。我们指出了许多有待进一步研究的途径,包括快速在线适应、解决RL特定的一般化问题、新颖的架构、基于模型的RL和环境生成。
-
我们批判性地讨论了RL研究的泛化现状,并提出了未来的研究方向。特别地,我们指出,构建基准将使离线的RL一般化和奖励功能变化取得进展,这两者都是重要的设置。此外,我们指出了几个值得探索的不同设置和评估指标:调查上下文效率和在连续的RL设置中工作都是未来工作的必要领域。