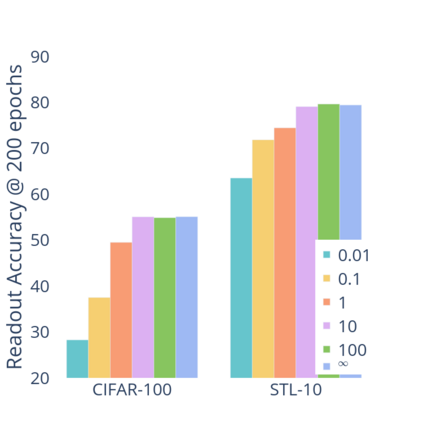
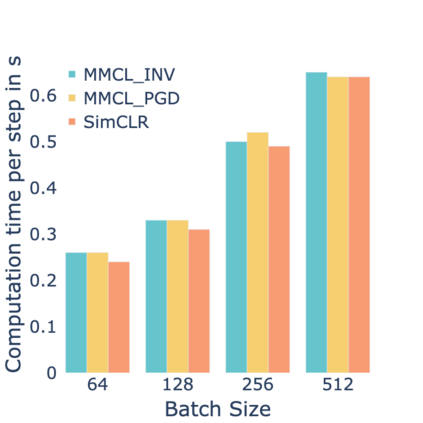
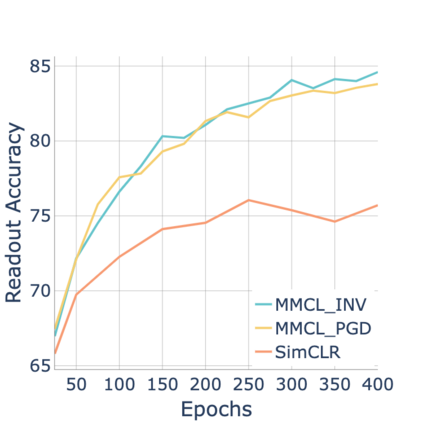
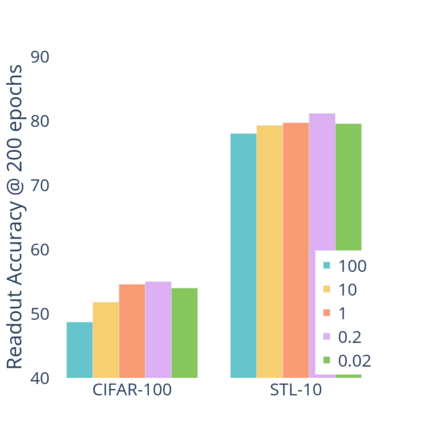
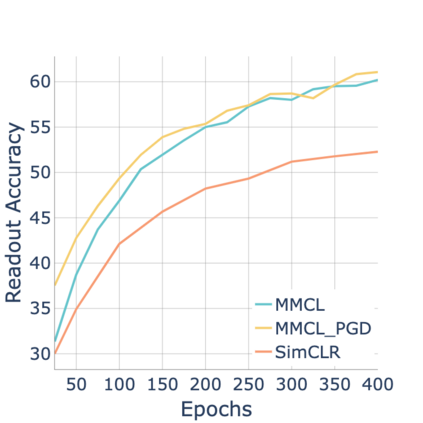
Standard contrastive learning approaches usually require a large number of negatives for effective unsupervised learning and often exhibit slow convergence. We suspect this behavior is due to the suboptimal selection of negatives used for offering contrast to the positives. We counter this difficulty by taking inspiration from support vector machines (SVMs) to present max-margin contrastive learning (MMCL). Our approach selects negatives as the sparse support vectors obtained via a quadratic optimization problem, and contrastiveness is enforced by maximizing the decision margin. As SVM optimization can be computationally demanding, especially in an end-to-end setting, we present simplifications that alleviate the computational burden. We validate our approach on standard vision benchmark datasets, demonstrating better performance in unsupervised representation learning over state-of-the-art, while having better empirical convergence properties.
翻译:标准反向学习方法通常要求大量负面数据,以便有效进行不受监督的学习,而且往往表现出缓慢的趋同。我们怀疑,这种行为是由于用于提供反正反正的负数据选择不够理想。我们从支持矢量机(SVMs)中汲取灵感,以展示最大偏差的反向学习(MMCL)来克服这一困难。我们的方法选择负数据,作为通过二次优化问题获得的稀疏支持矢量,而对比性则通过尽量扩大决定的差值来执行。SVM优化在计算上可能要求很高,特别是在终端到终端的设置中,我们提出了减轻计算负担的简化方法。我们在标准愿景基准数据集上验证了我们的方法,展示了不受监督的代表性学习优于最新技术的更好表现,同时具备了更好的经验趋同性。