
简介: Yann Lecun在演讲中介绍了“蛋糕类比”,以说明自我监督学习的重要性。 尽管对此类比法进行了辩论(参见:《机器人的深度学习》(幻灯片96), Pieter Abbeel),但我们已经看到了自我监督学习在自然语言处理领域的影响,该领域的最新发展(Word2Vec,Glove,ELMO,BERT) 进行自我监督并取得了最新成果。
“如果智力是蛋糕,那么蛋糕的大部分是自我监督学习,蛋糕上的糖衣是监督学习,蛋糕上的樱桃是强化学习(RL)。”
核心思想:
要应用监督学习,我们需要足够的标签数据。 为此,人工注释者手动标记数据(图像/文本),这既耗时又昂贵。 还有一些领域,例如医学领域,获取足够的数据本身就是一个挑战。
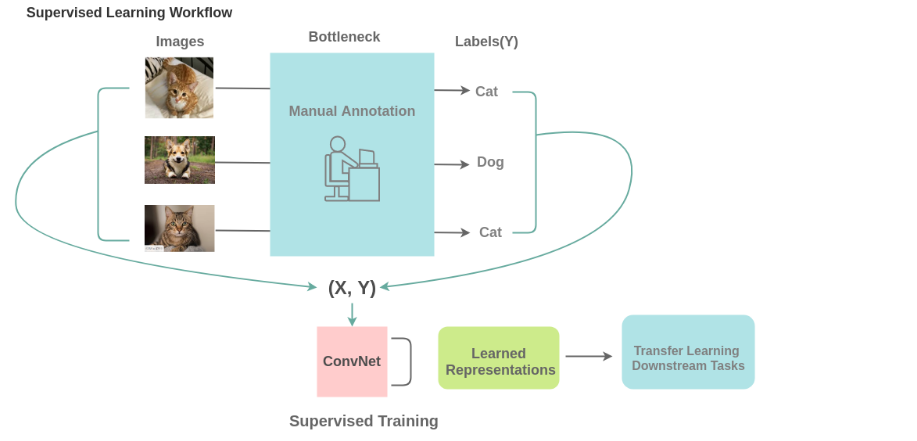
这是自我监督学习发挥作用的地方。 为此提出了以下问题: 我们是否可以通过这样的方式设计任务,即可以从现有图像中生成几乎无限的标签,并以此来学习表示形式?
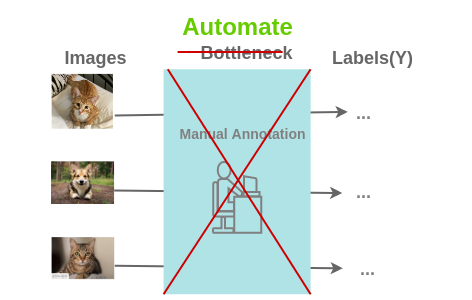
现存的方法:
- 图片
- 图片着色
- 图片超分辨率
- 图像修补
- 图像拼图
- 上下文预测
- 图像几何变换识别
- 图像聚类
- 图片合成
- 视频
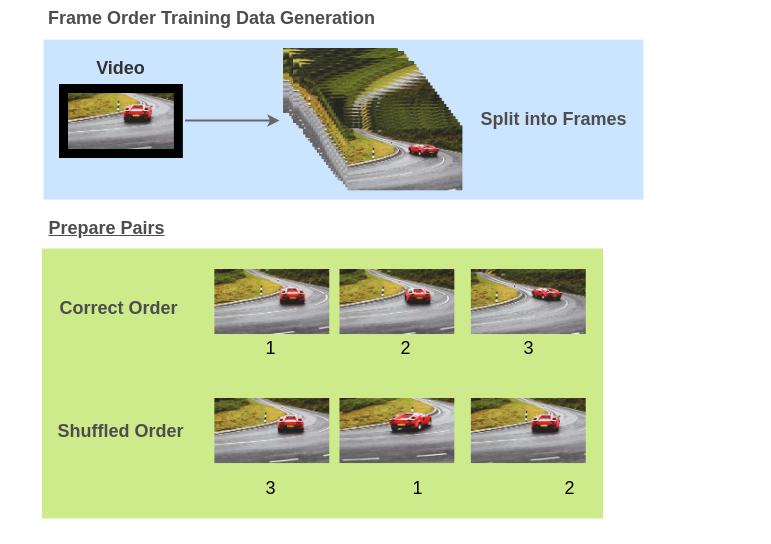
- 图片帧顺序验证
成为VIP会员查看完整内容
相关内容

Arxiv
5+阅读 · 2019年9月26日



相关VIP内容
相关资讯
相关论文
Arxiv
5+阅读 · 2019年9月26日