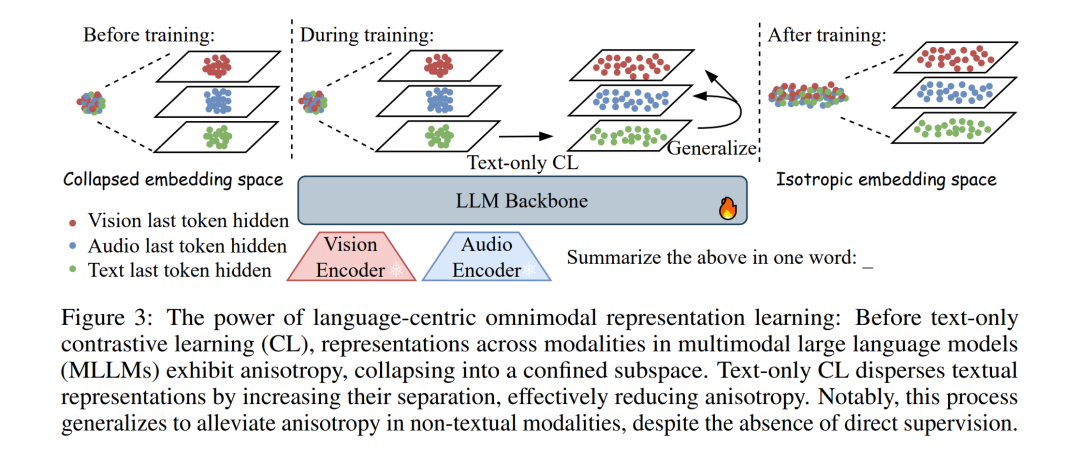
近年来,利用多模态大语言模型(Multimodal Large Language Models, MLLMs)并结合对比学习(Contrastive Learning, CL)进行微调的多模态嵌入方法表现出令人瞩目的成果,但其优越性的根本原因尚未得到充分探究。本文指出,基于 MLLM 的方法之所以具备关键优势,源于生成式预训练过程中隐式形成的跨模态对齐(implicit cross-modal alignment)。在这一阶段,语言解码器(language decoder)学会在共享表征空间中利用多模态信号,以生成单模态输出。 通过对各向异性(anisotropy)与核相似性结构(kernel similarity structure)的实证分析,本文证实了 MLLM 表征内部确实存在潜在的对齐关系,使得对比学习可以作为一种轻量级的后续精炼阶段。基于这一洞见,我们提出了一种以语言为中心的全模态嵌入框架(Language-Centric Omnimodal Embedding Framework, 简称 LCO-EMB)。在多种主干网络与基准任务上的广泛实验表明,该框架在不同模态下均取得了当前最先进(state-of-the-art)的表现。 此外,我们发现并提出了一个生成–表征缩放定律(Generation–Representation Scaling Law, GRSL),揭示了通过对比学习精炼获得的表征能力与 MLLM 的生成能力之间存在正相关关系。这一规律表明:提升模型的生成能力,本质上是一种增强表征质量的有效范式。我们进一步从理论上解释了 GRSL,形式化地建立了 MLLM 的生成质量与其表征性能上界之间的联系。最后,我们在一个具有挑战性的低资源视觉文档检索任务上验证了该理论,结果显示:在进行对比学习之前持续开展生成式预训练,能够进一步释放模型的嵌入潜力。