对比学习(Contrastive Learning)相关进展梳理

©PaperWeekly 原创 · 作者|李磊
学校|西安电子科技大学本科生
研究方向|自然语言处理
最近深度学习两巨头 Bengio 和 LeCun 在 ICLR 2020 上点名 Self-Supervised Learning(SSL,自监督学习) 是 AI 的未来,而其的代表的 Framework 便是 Contrastive Learning(CL,对比学习)。
另一巨头 Hinton 和 Kaiming 两尊大神也在这问题上隔空过招,MoCo、SimCLR、MoCo V2 打得火热,这和 BERT 之后,各大公司出 XL-Net、RoBerta 刷榜的场景何其相似。

很多研究者认为,深度学习的本质就是做两件事情:Representation Learning(表示学习)和 Inductive Bias Learning(归纳偏好学习)。目前的一个趋势就是,学好了样本的表示,在一些不涉及逻辑、推理等的问题上。
例如判断句子的情感极性、识别图像中有哪些东西,AI 系统都可以完成非常不错;而涉及到更高层的语义、组合逻辑,则需要设计一些过程来辅助 AI 系统去分解复杂的任务,ICLR 19 [1] 的一篇 oral 就是做的类似的事情。
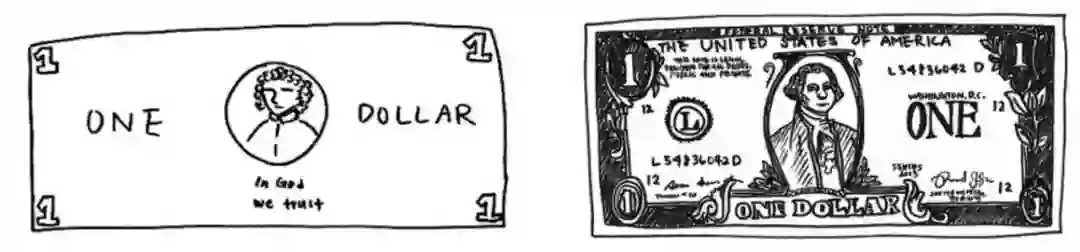
上面这个例子来自于 Contrastive Self-supervised Learning [2] 这篇 Blog,表达的一个核心思想就是:尽管我们已经见过很多次钞票长什么样子,但我们很少能一模一样的画出钞票;虽然我们画不出栩栩如生的钞票,但我们依旧可以轻易地辨别出钞票。
基于此,也就意味着表示学习算法并不一定要关注到样本的每一个细节,只要学到的特征能够使其和其他样本区别开来就行,这就是对比学习和对抗生成网络(GAN)的一个主要不同所在。
1.2 Contrastive Learning Framework
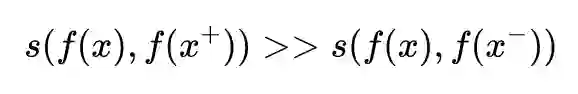
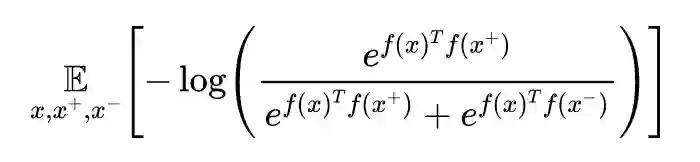
接下来,就会介绍一下 MoCo、SimCLR 以及 Contrasitve Predictive Coding(CPC) 这三篇文章,在构建对比样例中的一些核心观点。

2.1 MoCo

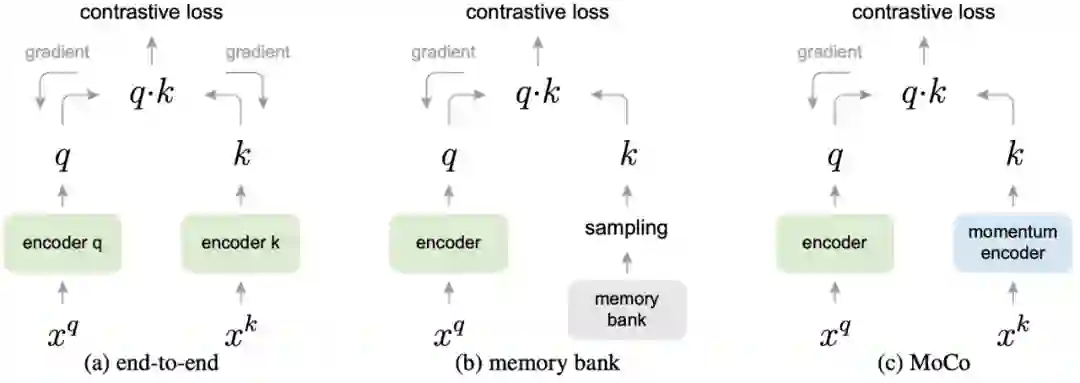
为此,Memory Bank 提出我把所有样本的表示都存起来,然后每次随机采样,这样就可以认为我的负例样本理论上可以达到所有样本的数量,具体的做法就是每一轮来 encode 一次所有的变量,显然,这样很吃内存,并且得到的表示也和参数更新存在一定的滞后。
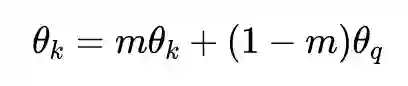
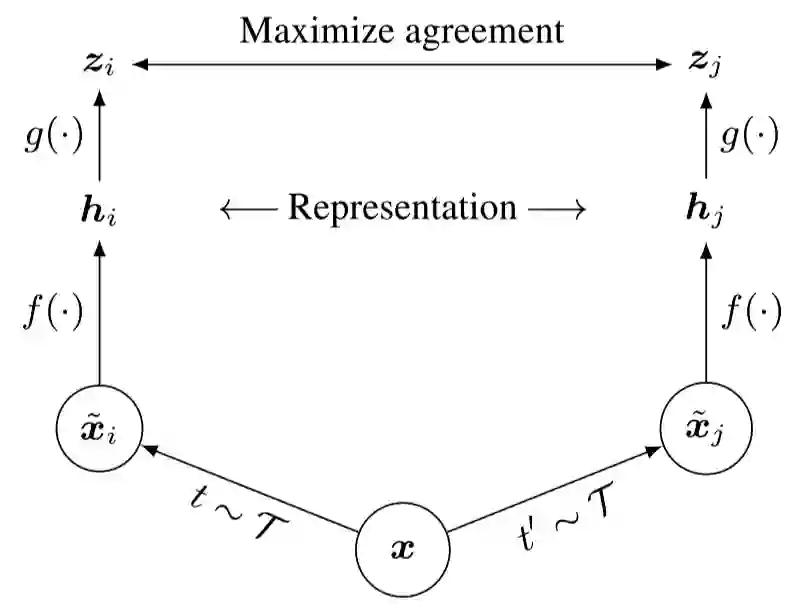
2.2 SimCLR

论文标题:A Simple Framework for Contrastive Learning of Visual Representations
论文链接:https://arxiv.org/abs/2002.05709
代码链接:https://github.com/google-research/simclr
-
对于样本进行变化,即构建正例和负例的 transformation 对于结果至关重要; 用 entropy loss 的 Contrastive Learning,可以通过 normalize representation embedding 以及 temperature adjustment 提点;
-
在计算 loss 之前,让表示再过一个 non-linear hard 能大幅提升效果,即上面框架图中的 ; -
大 batch-size 对于 CL 的增益比 Supervised Learning 更大。
2.3 CPC

前面讨论的两篇文章主要集中在图像数据上,那么对于文本、音频这样的数据,常见的裁剪、旋转等变换操作就无法适用了,并且,因为其数据本身的时序性,设计合理的方法来把这一点考虑进去是至关重要的。
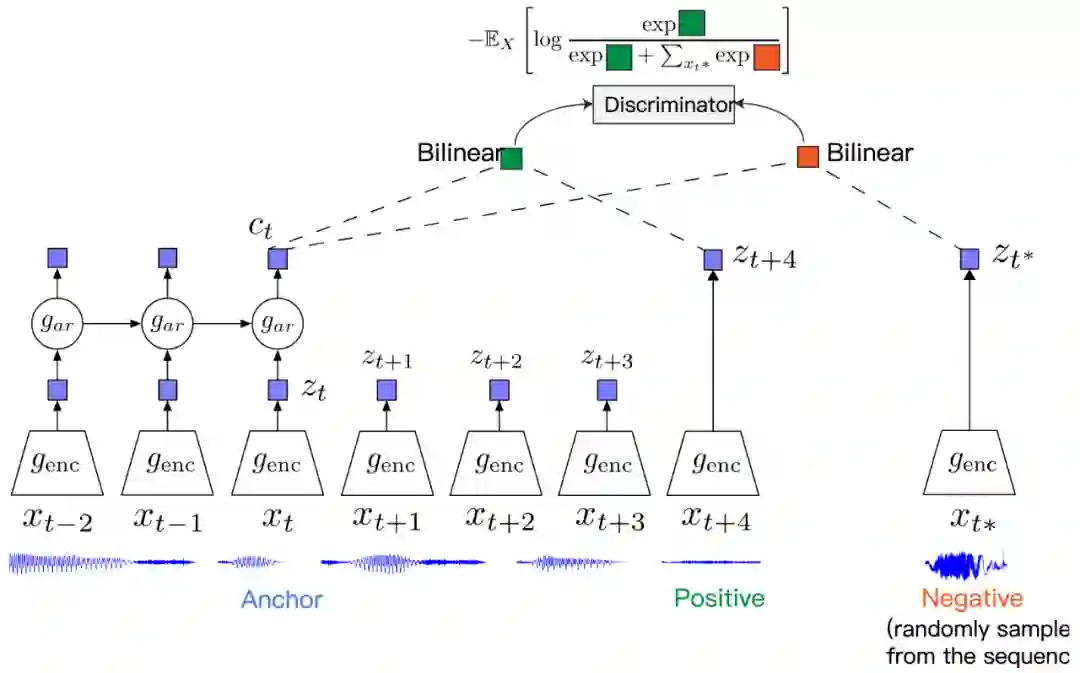

3.1 ICML 2019

这篇文章发表在 ICML 2019 上,对比学习这一框架虽然在直觉上非常 make sense,但是理论上为什么得到的表示就能够在 downstream 例如 classification 上表现良好?
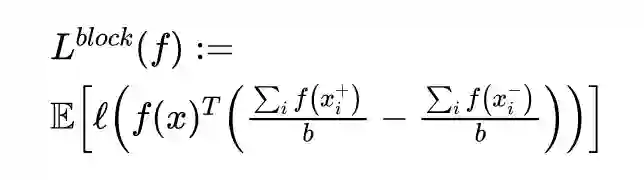
3.2 NIPS 2017

这篇文章希望通过使用对比学习来解决 image captioning 中标题文本可区别性的问题,即尽可能让标题描述和唯一的一张图片对应,而不是笼统而又模糊的可能和多张图片对应。
3.3 ICLR 2020

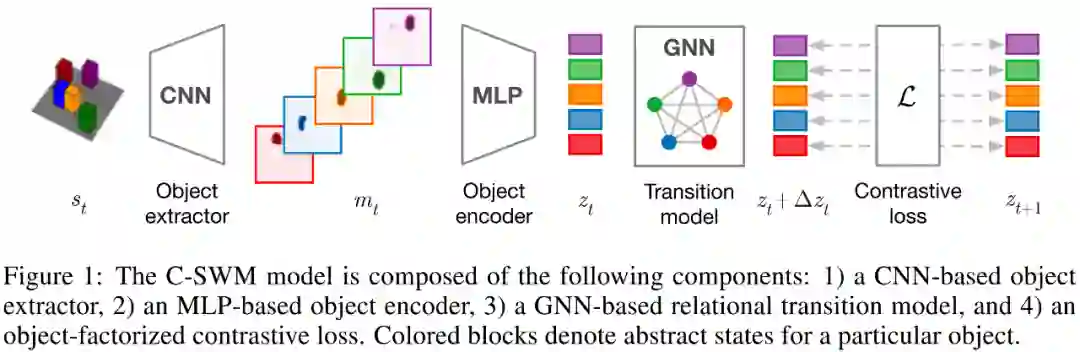
论文标题:Contrastive Learning of Structured World Models
论文来源:ICLR 2020
论文链接:https://arxiv.org/abs/1911.12247
代码链接:https://github.com/tkipf/c-swm
前面提到,表示学习能够较好的解决一些简单的任务,但是理解物体之间的关系以及建模其间的交互关系不单单需要好的表示,同样需要一个好的归纳偏好。
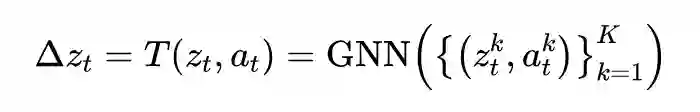
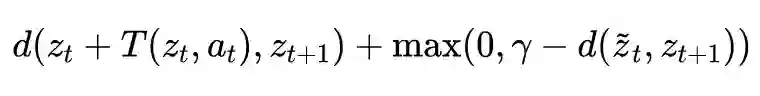

Summary
本文介绍了关于对比学习背后的动机,以及一系列在图像、文本上的一些工作,在计算机视觉领域,其习得的表示能够很好地在下游任务泛化,甚至能够超过监督学习的方法。
回过头来看,预训练模型从 ImageNet 开始,后来这一思想迁移到 NLP,有了 BERT 等一系列通过自监督的预训练方法来学习表示,后来这一想法又反哺了计算机视觉领域,引出了诸如 MoCo、SimCLR 等工作,在一系列分割、分类任务上都取得了惊人的表现。

点击以下标题查看更多往期内容:
-
GELU的两个初等函数近似是怎么来的?
-
BERT在小米NLP业务中的实战探索
-
图神经网络时代的深度聚类
-
针对复杂问题的知识图谱问答最新进展
-
小样本学习(Few-shot Learning)综述
-
将“softmax+交叉熵”推广到多标签分类问题

#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。





