
题目: CURL: Contrastive Unsupervised Representations for Reinforcement Learning
摘要:
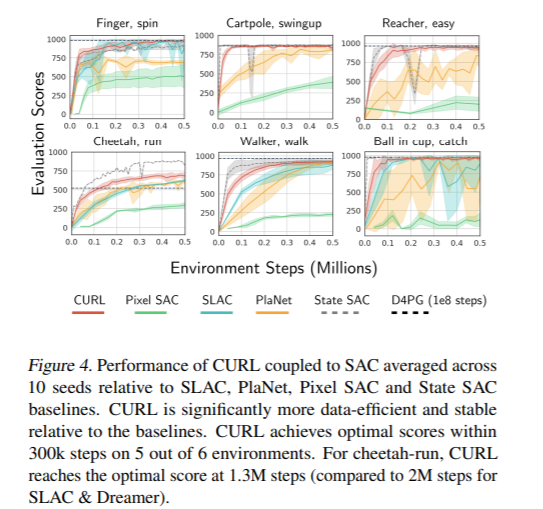
我们提出了CURL:用于强化学习的对比无监督表示法。CURL使用对比学习从原始像素中提取高级特征,并在提取的特征之上执行off-policy控制。在DeepMind控制套件和Atari游戏中,在100K交互步骤基准测试中,CURL在复杂任务上的表现优于先前基于模型和非模型的基于像素的方法,分别提高了2.8倍和1.6倍的性能。在DeepMind控制套件中,CURL是第一个基于图像的算法,它的效率和性能几乎与使用基于状态的特性的方法不相上下。 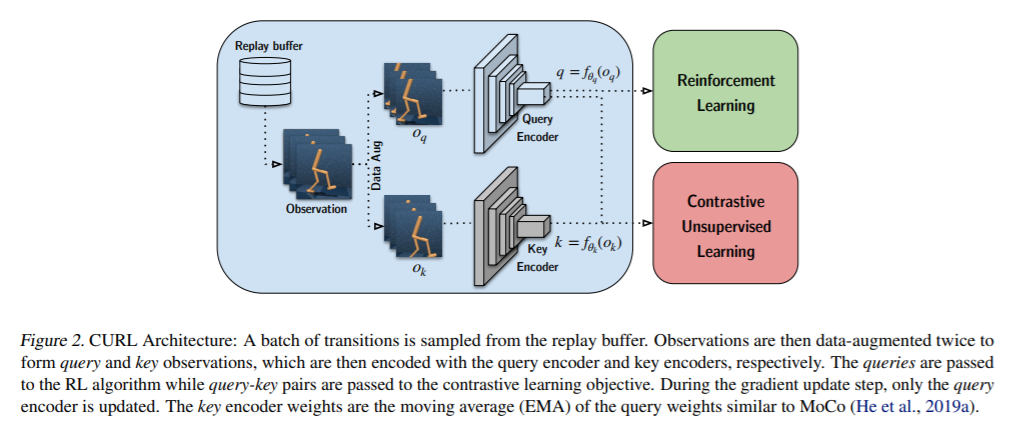
成为VIP会员查看完整内容
相关内容

强化学习(RL)是机器学习的一个领域,与软件代理应如何在环境中采取行动以最大化累积奖励的概念有关。除了监督学习和非监督学习外,强化学习是三种基本的机器学习范式之一。
强化学习与监督学习的不同之处在于,不需要呈现带标签的输入/输出对,也不需要显式纠正次优动作。相反,重点是在探索(未知领域)和利用(当前知识)之间找到平衡。
该环境通常以马尔可夫决策过程(MDP)的形式陈述,因为针对这种情况的许多强化学习算法都使用动态编程技术。经典动态规划方法和强化学习算法之间的主要区别在于,后者不假设MDP的确切数学模型,并且针对无法采用精确方法的大型MDP。
专知会员服务
69+阅读 · 2020年6月19日
专知会员服务
27+阅读 · 2020年4月5日
专知会员服务
48+阅读 · 2019年12月24日
专知会员服务
24+阅读 · 2019年11月11日
Arxiv
5+阅读 · 2020年6月10日

相关VIP内容
专知会员服务
69+阅读 · 2020年6月19日
专知会员服务
27+阅读 · 2020年4月5日
专知会员服务
48+阅读 · 2019年12月24日
专知会员服务
24+阅读 · 2019年11月11日
相关资讯
相关论文
Arxiv
5+阅读 · 2020年6月10日