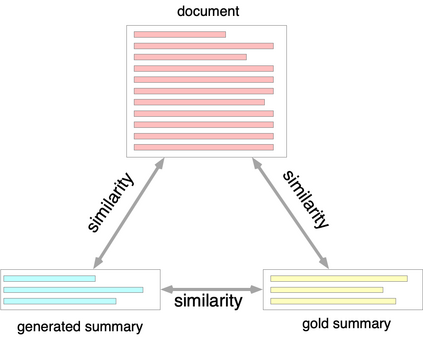
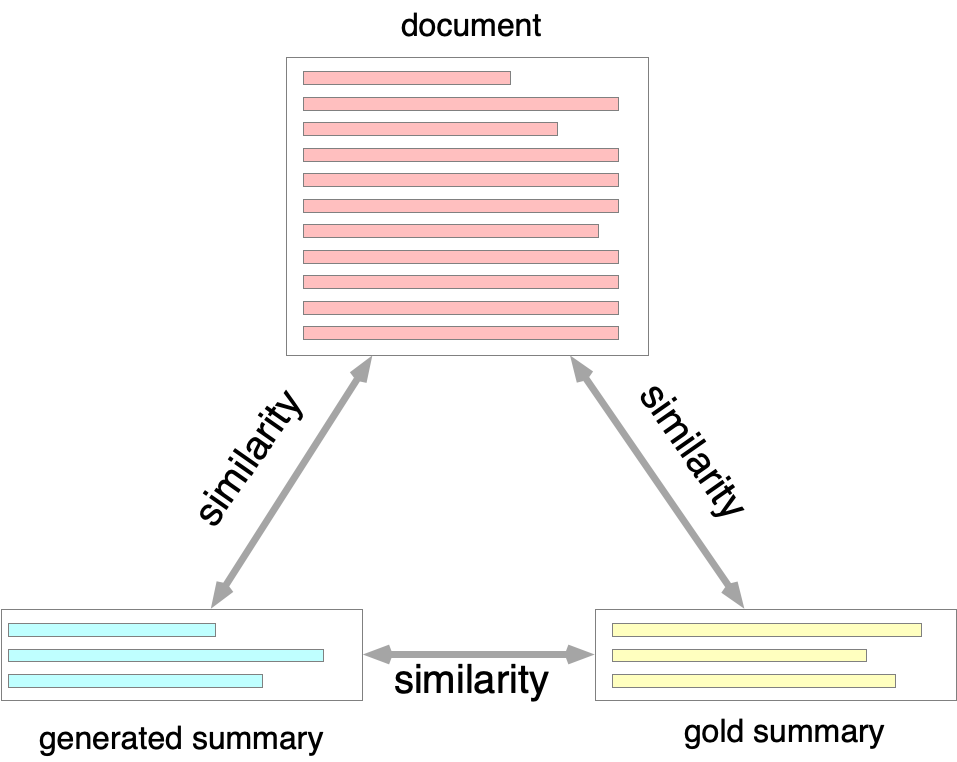
Contrastive learning models have achieved great success in unsupervised visual representation learning, which maximize the similarities between feature representations of different views of the same image, while minimize the similarities between feature representations of views of different images. In text summarization, the output summary is a shorter form of the input document and they have similar meanings. In this paper, we propose a contrastive learning model for supervised abstractive text summarization, where we view a document, its gold summary and its model generated summaries as different views of the same mean representation and maximize the similarities between them during training. We improve over a strong sequence-to-sequence text generation model (i.e., BART) on three different summarization datasets. Human evaluation also shows that our model achieves better faithfulness ratings compared to its counterpart without contrastive objectives.
翻译:对比式学习模式在未经监督的视觉演示学习中取得了巨大成功,这种学习模式最大限度地扩大了同一图像不同观点特征的相似性,同时尽量减少不同图像不同观点不同特征特征的相似性。在文本摘要中,产出摘要是投入文件的一种较短的形式,其含义相似。在本文中,我们提出了一个监督抽象文本总结的对比式学习模式,我们把文件、其黄金摘要及其生成的模型摘要视为对相同平均值的不同观点,并在培训期间尽量扩大它们之间的相似性。我们改进了三种不同组合数据集的强有力的顺序到顺序的文本生成模型(即BART)。人类评价还表明,我们的模型与没有对比目标的对应模型相比,更加忠实。