
背景:现有的大部分深度聚类(Deep Clustering)算法需要迭代进行表示学习和聚类这两个过程,利用聚类结果来优化表示,再对更优的表示进行聚类,此类方法主要存在以下两个缺陷,一是迭代优化的过程中容易出现误差累计,二是聚类过程通常采用k-means等需要全局相似性信息的算法,使得需要数据全部准备好后才能进行聚类,故面临不能处理在线数据的局限性。针对上述问题,本文提出了一种基于对比学习的聚类算法,其同时进行表示学习和聚类分析,且能实现流式数据的聚类。
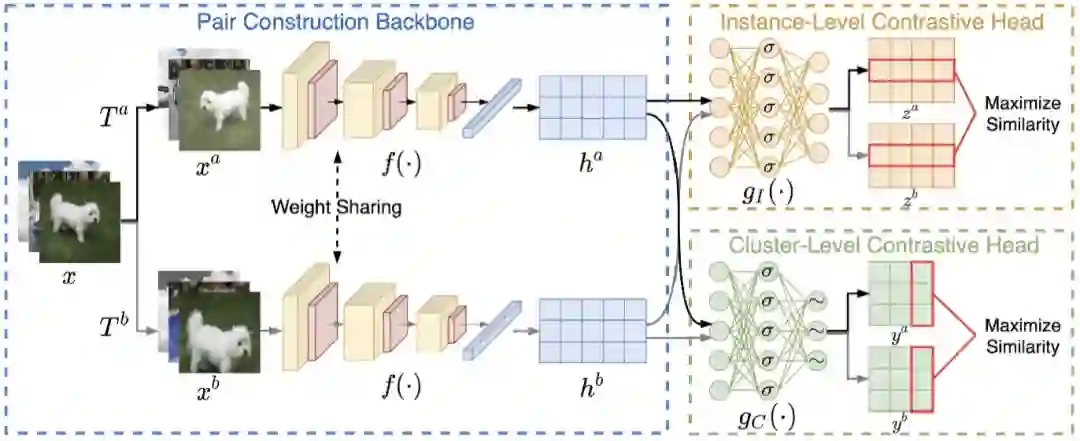
方法:本文基于“标签即表示”的思想[2],将聚类任务统一到表示学习框架下,对每个样本学习其聚类软标签作为特征表示。具体地,我们在国际上首次揭示数据特征矩阵的行和列事实上分别对应实例和类别的表示(图1)。也即,特征矩阵的列是一种特殊的类别表示,其对应某一实例属于某一类别的概率。基于该洞见,本文提出同时在特征矩阵的行空间与列空间,即实例级别和类别级别,进行对比学习即可进行聚类。
成为VIP会员查看完整内容
相关内容
相关VIP内容
相关资讯
相关论文