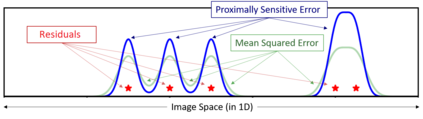
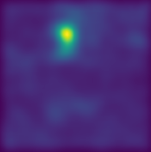
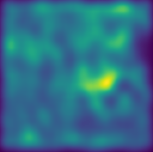
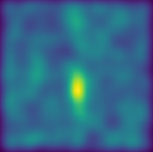
Mean squared error (MSE) is one of the most widely used metrics to expression differences between multi-dimensional entities, including images. However, MSE is not locally sensitive as it does not take into account the spatial arrangement of the (pixel) differences, which matters for structured data types like images. Such spatial arrangements carry information about the source of the differences; therefore, an error function that also incorporates the location of errors can lead to a more meaningful distance measure. We introduce Proximally Sensitive Error (PSE), through which we suggest that a regional emphasis in the error measure can 'highlight' semantic differences between images over syntactic/random deviations. We demonstrate that this emphasis can be leveraged upon for the task of anomaly/occlusion detection. We further explore its utility as a loss function to help a model focus on learning representations of semantic objects instead of minimizing syntactic reconstruction noise.
翻译:平均平方差(MSE)是用于表达包括图像在内的多维实体之间差异的最广泛使用的指标之一。 但是, MSE并不对当地敏感,因为它没有考虑到(像素)差异的空间安排,这些差异对于结构化数据类型如图像很重要。这种空间安排包含关于差异源的信息;因此,一个包含错误位置的错误函数也会导致更有意义的距离测量。 我们引入了近似敏感错误(PSE), 通过它我们建议错误测量中的区域强调可以“高光”图像在合成法/随机偏差之间的语义差异。 我们证明,这种强调可以用于反常/闭塞探测任务。 我们进一步探索其作为损失功能的效用,以帮助以学习语义对象的表达模式为重点,而不是将合成重建的噪音最小化。