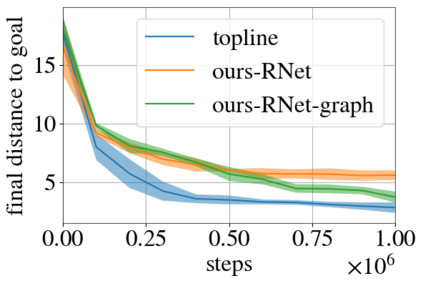
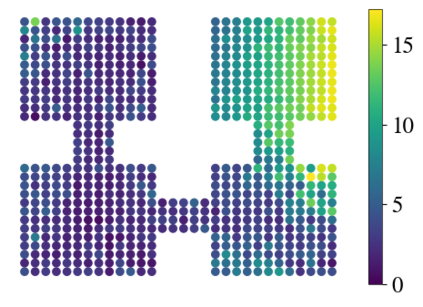
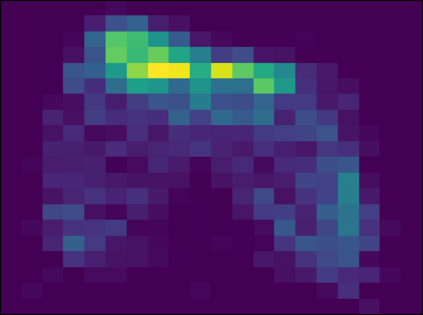
Learning a diverse set of skills by interacting with an environment without any external supervision is an important challenge. In particular, obtaining a goal-conditioned agent that can reach any given state is useful in many applications. We propose a novel method for training such a goal-conditioned agent without any external rewards or any domain knowledge. We use random walk to train a reachability network that predicts the similarity between two states. This reachability network is then used in building goal memory containing past observations that are diverse and well-balanced. Finally, we train a goal-conditioned policy network with goals sampled from the goal memory and reward it by the reachability network and the goal memory. All the components are kept updated throughout training as the agent discovers and learns new goals. We apply our method to a continuous control navigation and robotic manipulation tasks.
翻译:通过在没有任何外部监督的情况下与环境互动来学习多种技能,是一项重要挑战。特别是,获得一个能够达到任何特定状态的、有目标条件的代理人,在许多应用中都是有用的。我们提出了一种新颖的方法,用于培训这样一个没有外部奖励或任何领域知识的、有目标条件的代理人。我们用随机步行来训练一个可达性网络,预测两个州之间的相似性。然后,利用这个可达性网络来建立目标记忆,包含过去不同和平衡的观察结果。最后,我们训练一个有目标条件的政策网络,其目标指标来自目标记忆样本,并通过可达性网络和目标记忆来奖励它。在培训过程中,所有组成部分都不断更新,因为代理人发现并学习新的目标。我们用我们的方法来持续控制导航和机器人操纵任务。