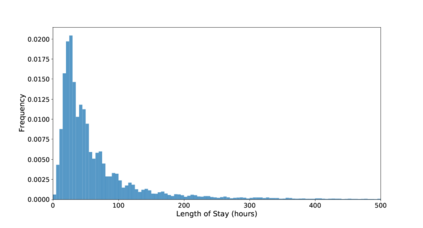
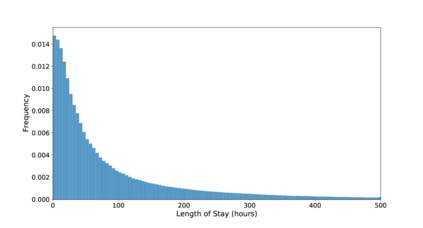
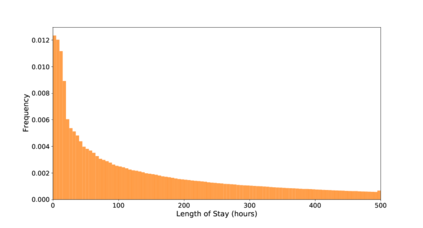
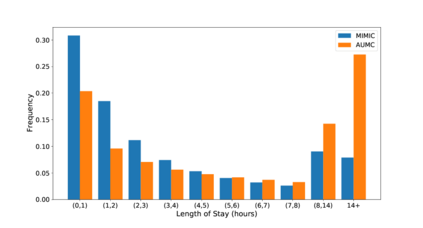
Unsupervised domain adaptation (UDA) aims at learning a machine learning model using a labeled source domain that performs well on a similar yet different, unlabeled target domain. UDA is important in many applications such as medicine, where it is used to adapt risk scores across different patient cohorts. In this paper, we develop a novel framework for UDA of time series data, called CLUDA. Specifically, we propose a contrastive learning framework to learn domain-invariant semantics in multivariate time series, so that these preserve label information for the prediction task. In our framework, we further capture semantic variation between source and target domain via nearest-neighbor contrastive learning. To the best of our knowledge, ours is the first framework to learn domain-invariant semantic information for UDA of time series data. We evaluate our framework using large-scale, real-world datasets with medical time series (i.e., MIMIC-IV and AmsterdamUMCdb) to demonstrate its effectiveness and show that it achieves state-of-the-art performance for time series UDA.
翻译:无人监督的域适应(UDA)旨在学习一个机器学习模型,它使用一个标签的源域,在一个相似但又不同的、没有标签的目标域上运行良好。UDA在许多应用中非常重要,例如医学,它用来调整不同病人组群的风险分数。在本文中,我们为时间序列数据UDA开发了一个新颖的框架,称为CLUDA。具体地说,我们提议了一个对比式学习框架,以学习多变时间序列中的域异性语义学,以便保存用于预测任务的标签信息。在我们的框架内,我们通过近邻对比学习进一步捕捉到源和目标域之间的语义变异。根据我们的知识,我们的第一个框架是学习时间序列UDA的域变异性语义信息。我们用医疗时间序列(即MIM-IV和阿姆斯特穆德)来评估我们的框架,以展示其有效性并显示它达到时间序列的状态性能。