Multi-Task Learning的几篇综述文章
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要9分钟
跟随小博主,每天进步一丢丢


来自 | 知乎
地址 | https://zhuanlan.zhihu.com/p/145706170
作者 | 黄浴
编辑 | 机器学习算法与自然语言处理公众号
本文仅作学术分享,若侵权,请联系后台删文处理
下面分别介绍多任务学习(MTL)的三篇综述文章。
Ruder S, "An Overview of Multi-Task Learning in Deep Neural Networks", arXiv 1706.05098, June 2017

深度学习方面MTL总结:
按照隐层,MTL基本分两类:Hard sharing和Soft sharing
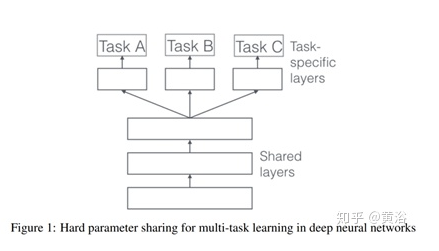
Hard sharing在多任务之间共享隐层,降低over fitting的风险。“The more tasks we are learning simultaneously, the more our model has to find a representation that captures all of the tasks and the less is our chance of overfitting on our original task”
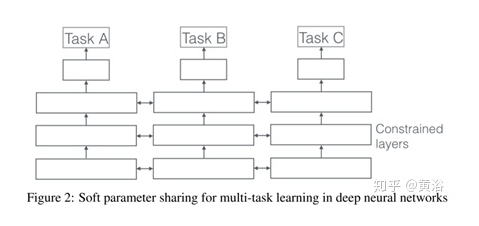
Soft sharing各任务之间有自己的模型和参数,主要靠regularization鼓励任务之间的模型参数相似。
MTL的机制有几点:
Implicit data augmentation 数据增强
Attention focusing 注意
Eavesdropping 窃听
Representation bias 表示偏向
Regularization 正则化
非神经网络模型中的MTL,主要有两种:
Block-sparse regularization:enforcing sparsity across tasks through norm regularization
Learning task relationships:modelling the relationships between tasks
深度学习模型中的MTL:
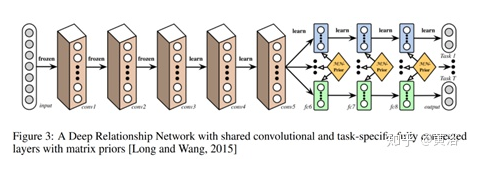
Deep Relationship Networks
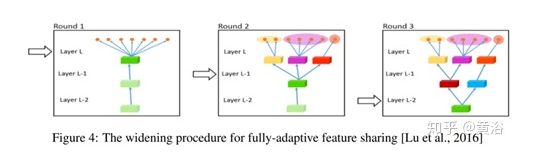
Fully-Adaptive Feature Sharing
Cross-stitch Networks
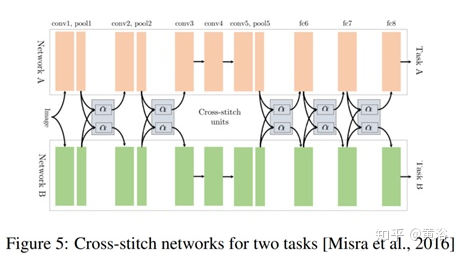
Low supervision
deep bi-directional RNNs [Søgaard and Goldberg, 2016]
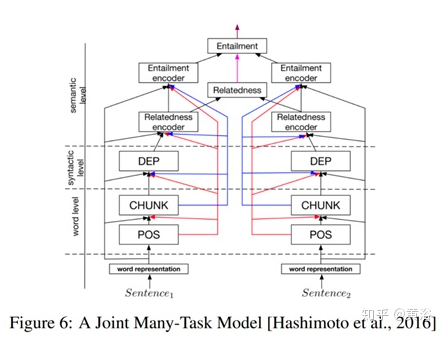
A Joint Many-Task Model
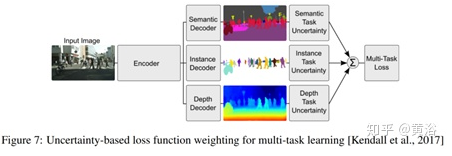
Weighting losses with uncertainty
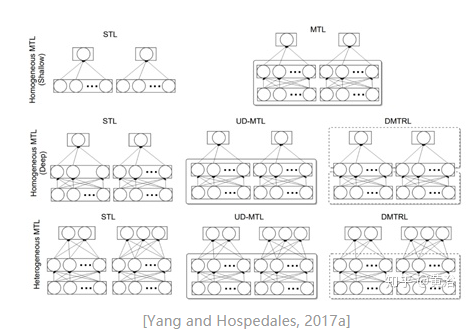
Tensor factorization for MTL (注:单任务学习STL)
Sluice Networks
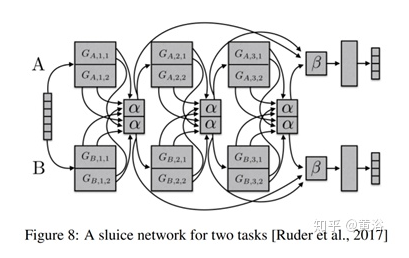
寻找辅助任务的方法:
Related task
Adversarial
Hints
Focusing attention
Quantization smoothing
Predicting inputs
Using the future to predict the present
Representation learning
Zhang Y, Yang Q, "An overview of multi-task learning", arXiv 1707.08114, July 2018

MTL方法分成几类:
feature learning approach 特征学习
low-rank approach 低秩 参数
task clustering approach 任务聚类 参数
task relation learning approach 任务关系学习 参数
decomposition approach 分解 参数
和其他机器学习方法结合:
semi-supervised learning
active learning
unsupervised learning
reinforcement learning
multi-view learning
graphical models
‘What to share’
feature:特征
instance:实例 (很少)
parameter:参数
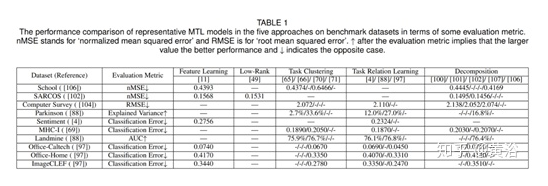
MTL方法比较:
· 特征学习方法学习通用特征,转移到所有现有任务甚至新任务。当存在与其他任务无关的异常任务时,会严重影响学习的功能,并且会导致性能下降,从而导致鲁棒性不强。
· 通过假设参数矩阵是低秩的,低秩方法可以显式学习参数矩阵的子空间,或者通过一些凸或非凸正则化器隐式实现该子空间。这种方法功能强大,但似乎仅适用于线性模型,非线性扩展的设计不容易。
· 任务聚类方法根据模型参数执行聚类,并且可以识别每个包含相似的任务的类。任务聚类方法的主要局限性是,捕获同一类任务之间的正相关,而忽略不同类之间的负相关。而且,即使该类某些方法可以自动确定聚类数,但大多数方法仍需要诸如交叉验证之类的模型选择方法来确定,带来更多的计算成本。
· 任务关系学习方法可以同时学习模型参数和任务对的关系。所学的任务关系可以对任务的关系有深刻了解,可以提高解释性。
· 通过多级参数,可以将分解方法视为其他参数方法的扩展,因此分解方法可以对更复杂的任务结构(即树结构)建模。分解方法的组件数对性能很重要。
正则化方法是MTL的主要方法。正则化MTL算法分为两类:特征协方差学习和任务关系学习。特征协方差学习可以看作是特征MTL的一种典型表述,而任务关系学习则是基于参数的MTL。
MTL扩展方法:(任务聚类方法和任务关系学习方法)
· 将每个任务的多类别分类问题转换为二进制分类问题。
· 利用学习的特征。
· 直接学习不同任务标签的对应关系。
· 所有任务的模型参数构成一个张量,其中每个任务的模型参数形成一个切片,然后采用正则化或者分解方法。
Thung K, Wee C, "A Brief Review on Multi-Task Learning", Multimedia Tools and Applications, August 2018.

Rich Caruana 给出的MTL定义:“MTL is an approach to inductive transfer that improves generalization by using the domain information contained in the training signals of related tasks as an inductive bias. It does this by learning tasks in parallel while using a shared low dimensional representation; what is learned for each task can help other tasks be learned better”.
基于输入/输出,MTL 分为三种类型:
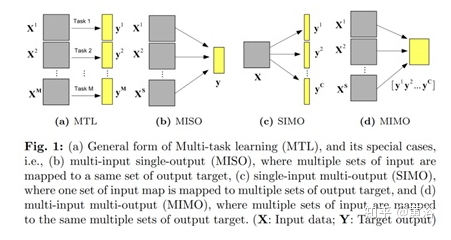
· multi-input single-output (MISO)
· single-input multioutput (SIMO)
· multi-input multi-output (MIMO)
按照正则化方法,MTL分类:
· LASSO
· group sparsity
· low rank
· task exclusiveness (unrelated tasks)
· graph Laplacian regularization
· decomposition
incomplete data MTL处理方法:
· use only samples with complete data for MTL study, with the cost of reduced statistical power of analysis due to smaller dataset;
· impute the missing data before performing the MTL study, where the imputation is very much prone to error for data missing in blocks
· design a MTL method that is applicable to incomplete data.
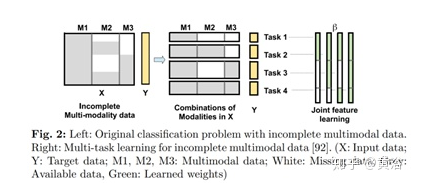
深度学习的MTL方法:
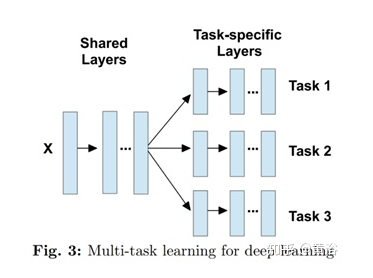
Vandenhende S et al., "Revisiting Multi-Task Learning in the Deep Learning Era", arXiv 2004.13379, 2020
很新的综述,刚刚看到。

深度学习的MTL主要是网络模型的设计能够从多任务监督信号中学会表征共享。MTL的优点主要是:1)由于层共享,减少了内存占用量。2)由于避免重复计算共享层特征,提高推理速度。3)如果相关任务共享补充信息或作为彼此的regularizer,则可以提高模型性能。比如计算机视觉中的检测和分类,检测和分割,分割和深度估计等等。
不过,如果任务字典里面包括不相干的任务,MTL的联合学习会带来negative transfer。为此不少方法是想寻找一个MTL的平衡点,比如Uncertainty Weighting、Gradient normalization、Dynamic Weight Averaging (DWA) 、Dynamic task prioritization、multiple gradient descent algorithm (MGDA) 和adversarial training等。另外一些最近的工作采用MTL得到一个初始预测,然后以此改进其特征得到更好的输出,比如PAD-NET、PAP-NET、JTRL和MTI-Net等。
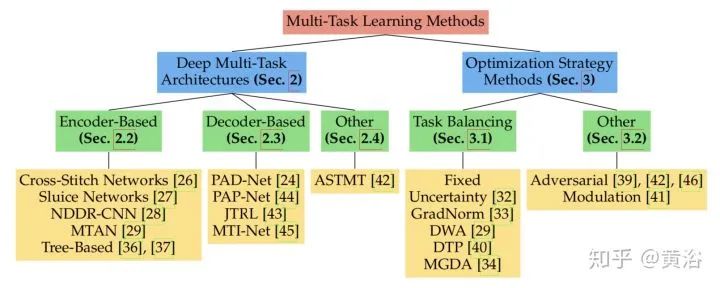
如图是文章对深度学习MTL的分类。MTL结构上分成编码器和解码器两种,优化策略上分成任务平衡或者其他。
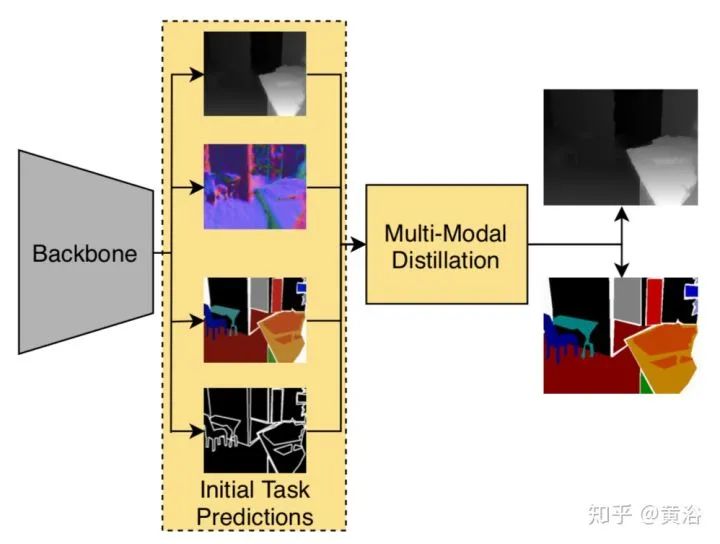
如图就是PAD-Net,解码器类的MTL。
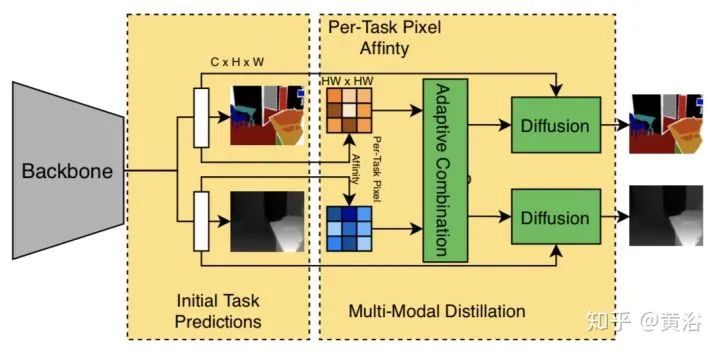
还有这个PAP-NET( Pattern-Affinitive Propagation Networks)。
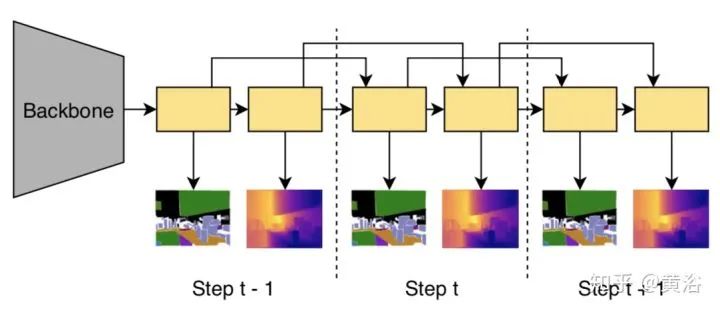
这是Joint Task-Recursive Learning (JTRL) 。
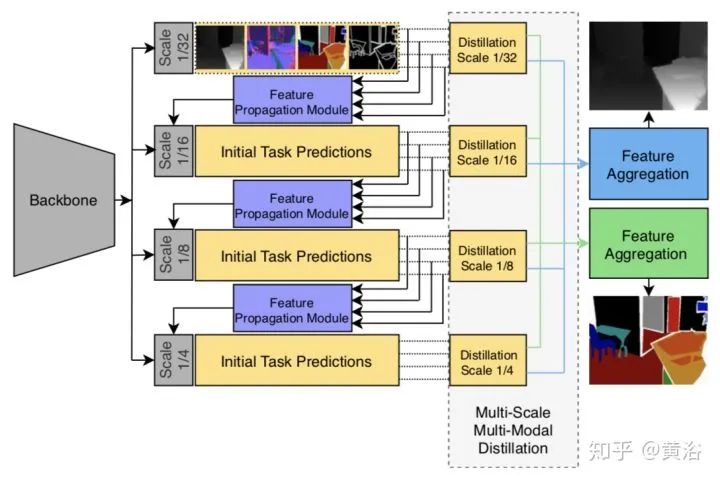
以及Multi-Scale Task Interaction Networks (MTI-Net) 。这些都是解码器类。

如表是任务平衡的方法比较:平衡幅度、平衡学习、梯度需要、非竞争梯度、非额外调节和动机等。
不同一般的是,该综述做了一些实验进行比较:
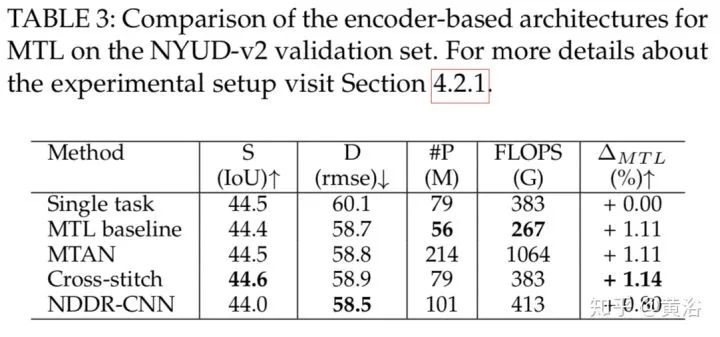
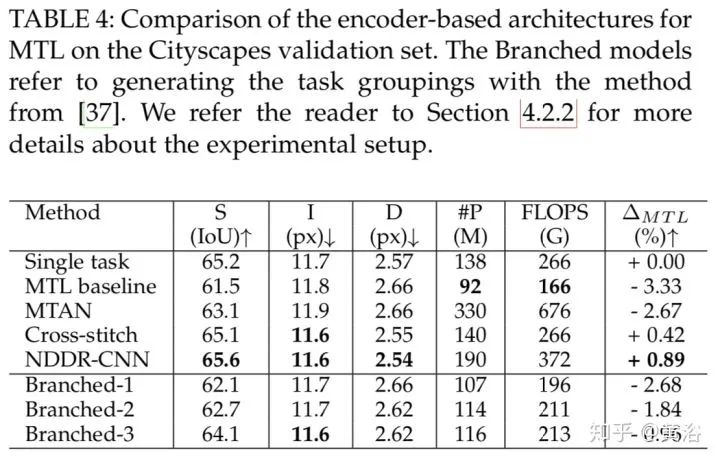
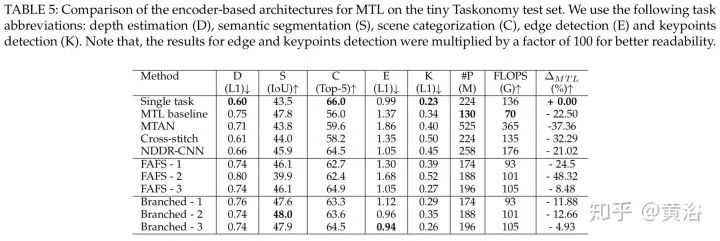
这三个表是编码器结构类。
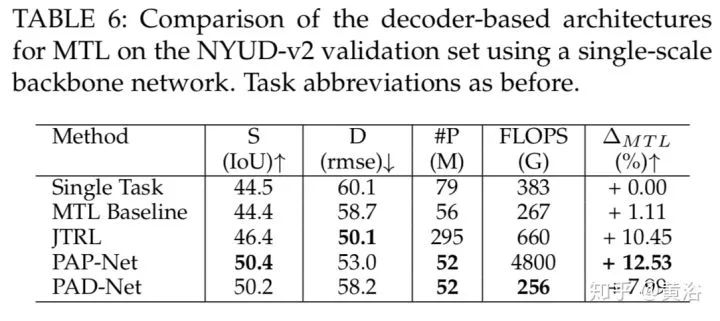
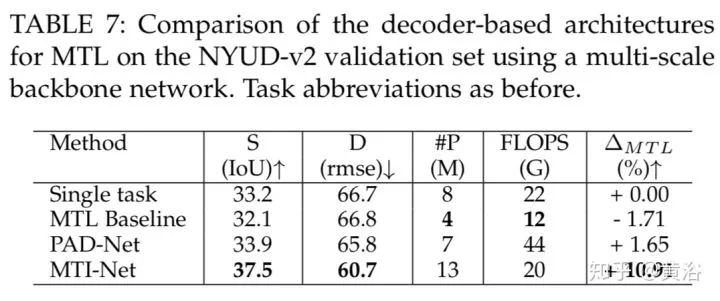


这四个表是解码器结构类。
结论是解码器类的MTL方法占优。当然,编码器对表征的贡献还是不能忽略的。
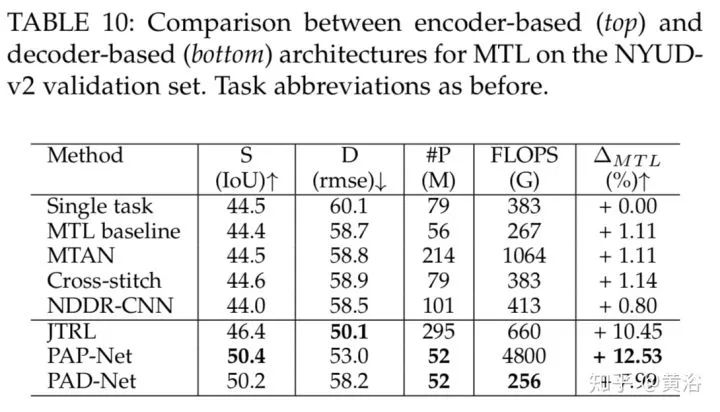
这是解码器和编码器的比较。
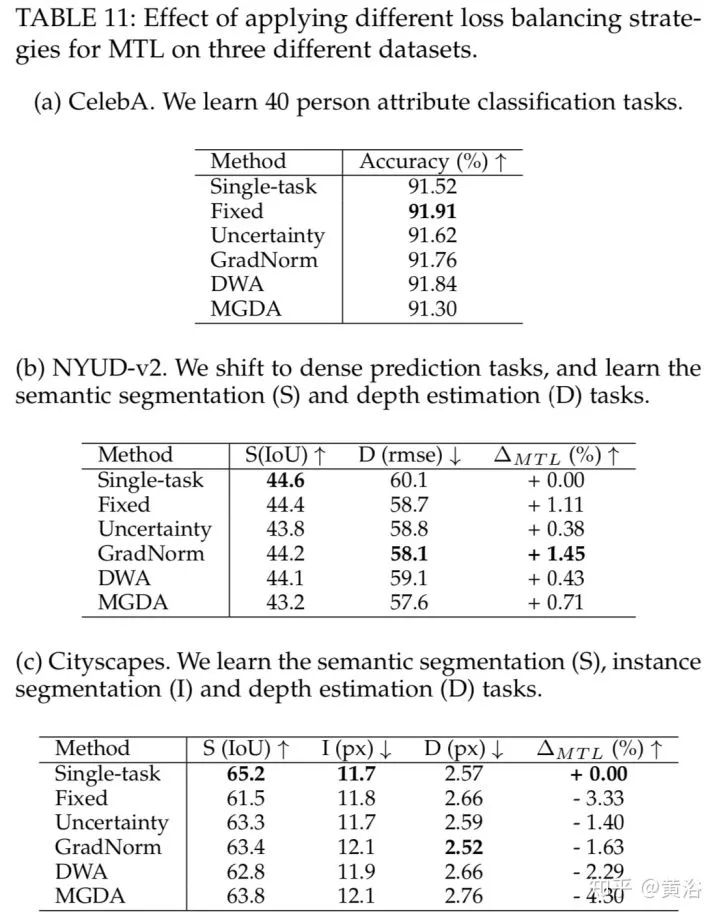
这是三个数据集上的损失平衡法结果比较。
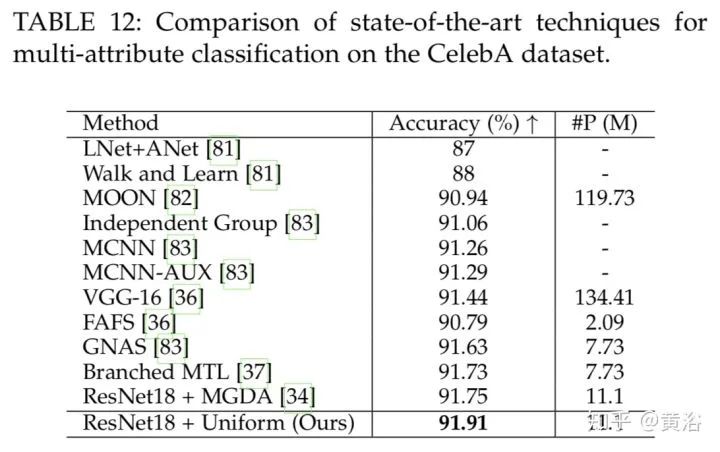
另外还给出了在数据集CelebA 上目前分类方法的比较,其中ResNet18加均匀权重的方法性能不错。
添加个人微信,备注:
昵称-学校(公司)-方向
,
即可获得
1. 快速学习深度学习五件套资料
2. 进入高手如云DL&NLP交流群
![]()
记得备注呦
![]()





