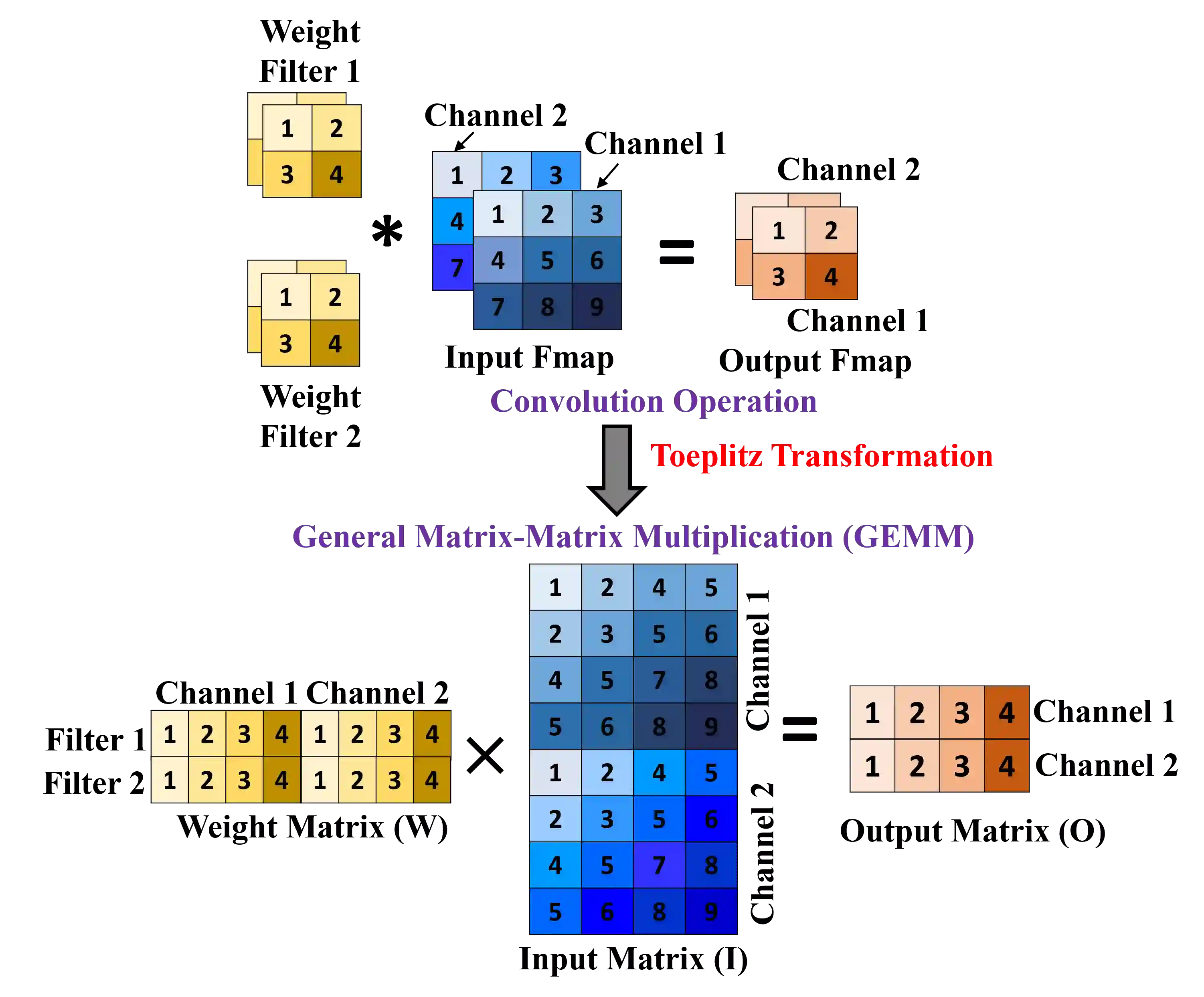
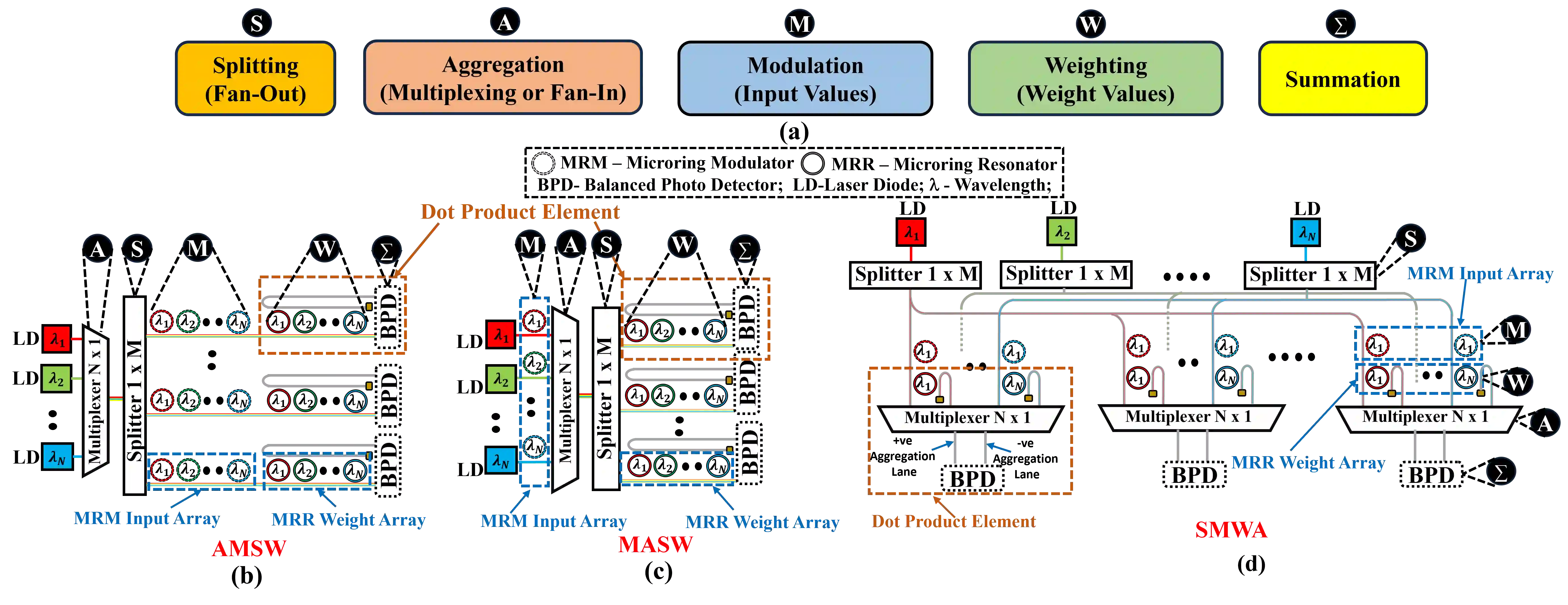
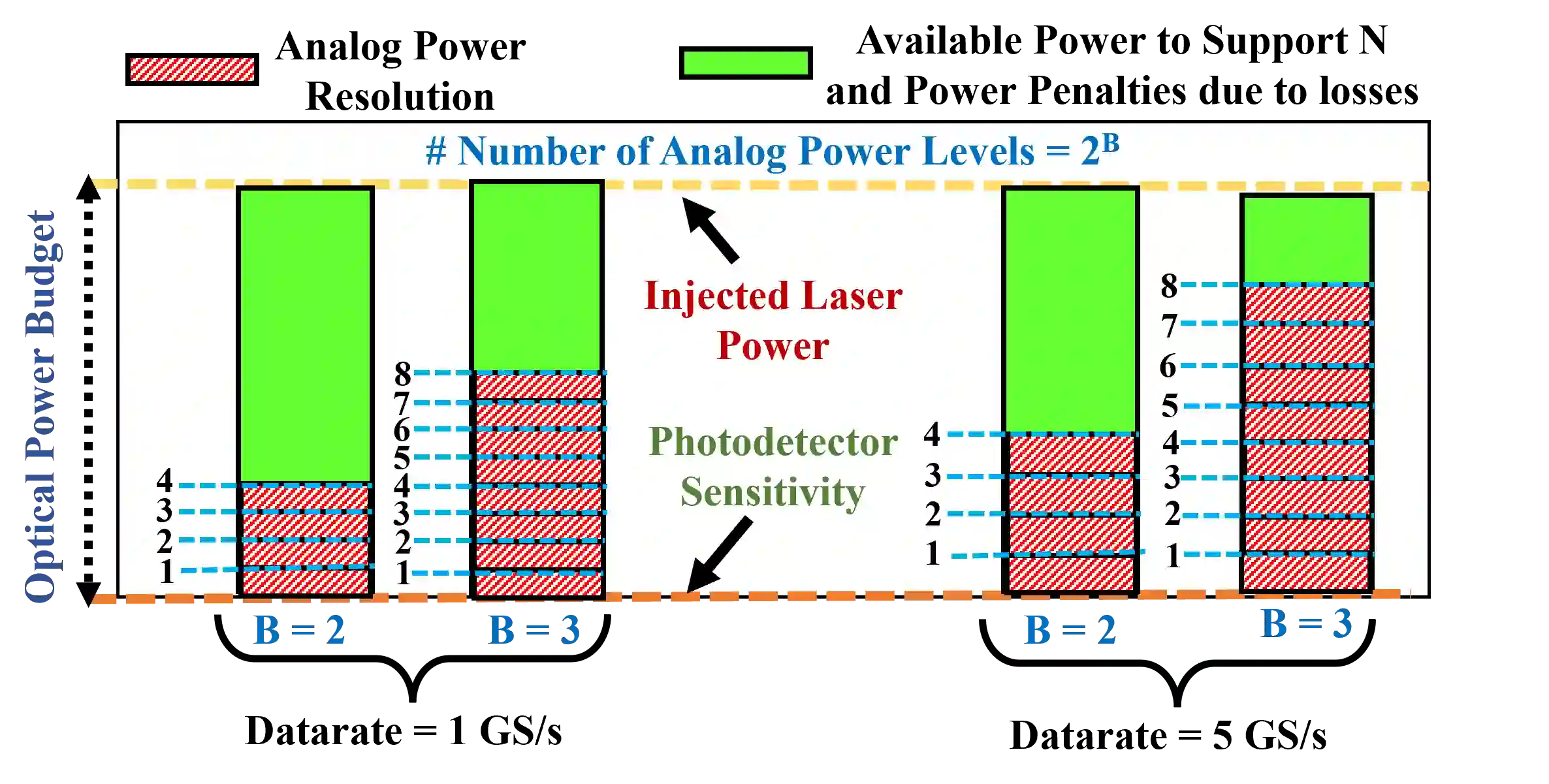
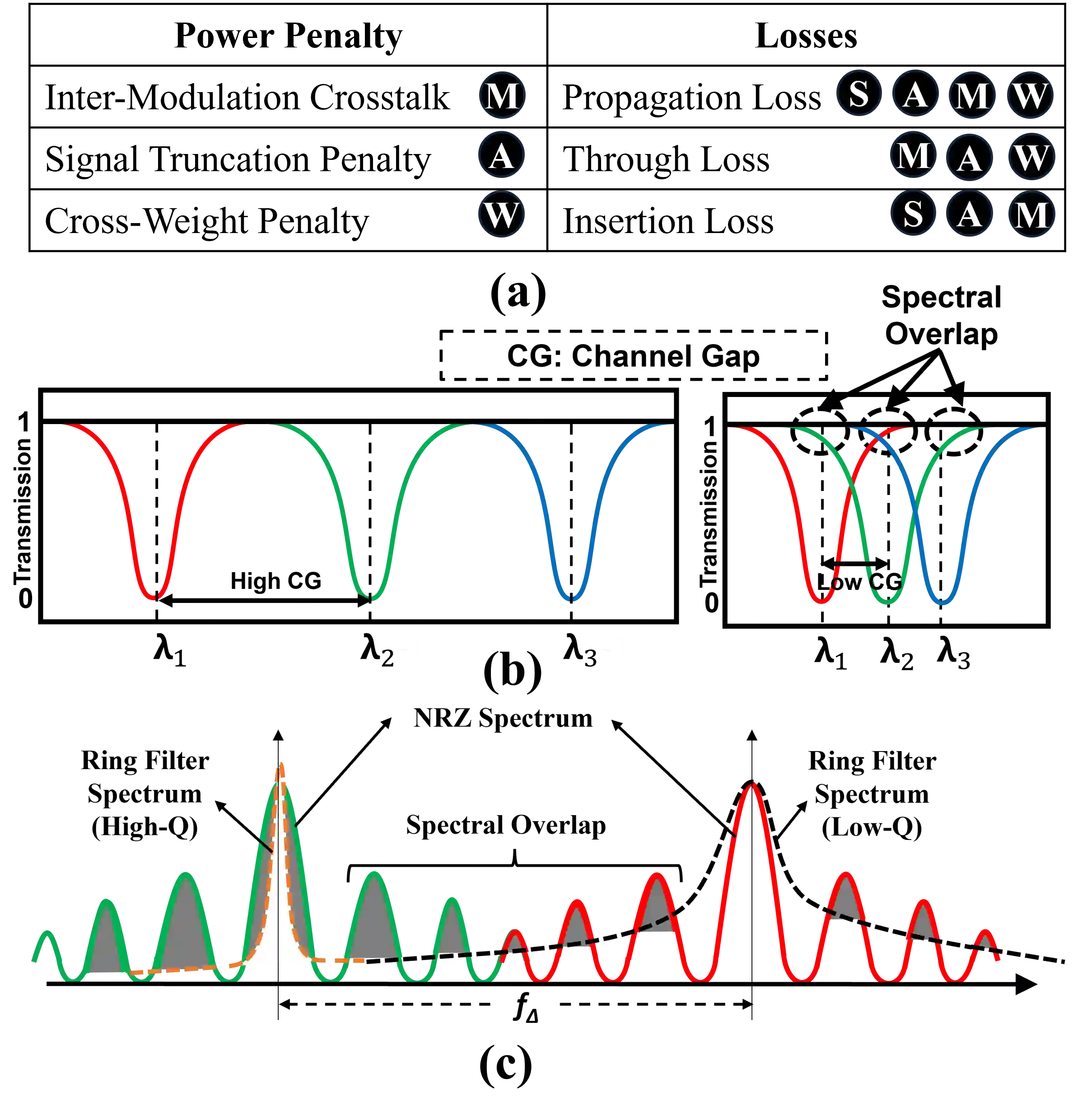
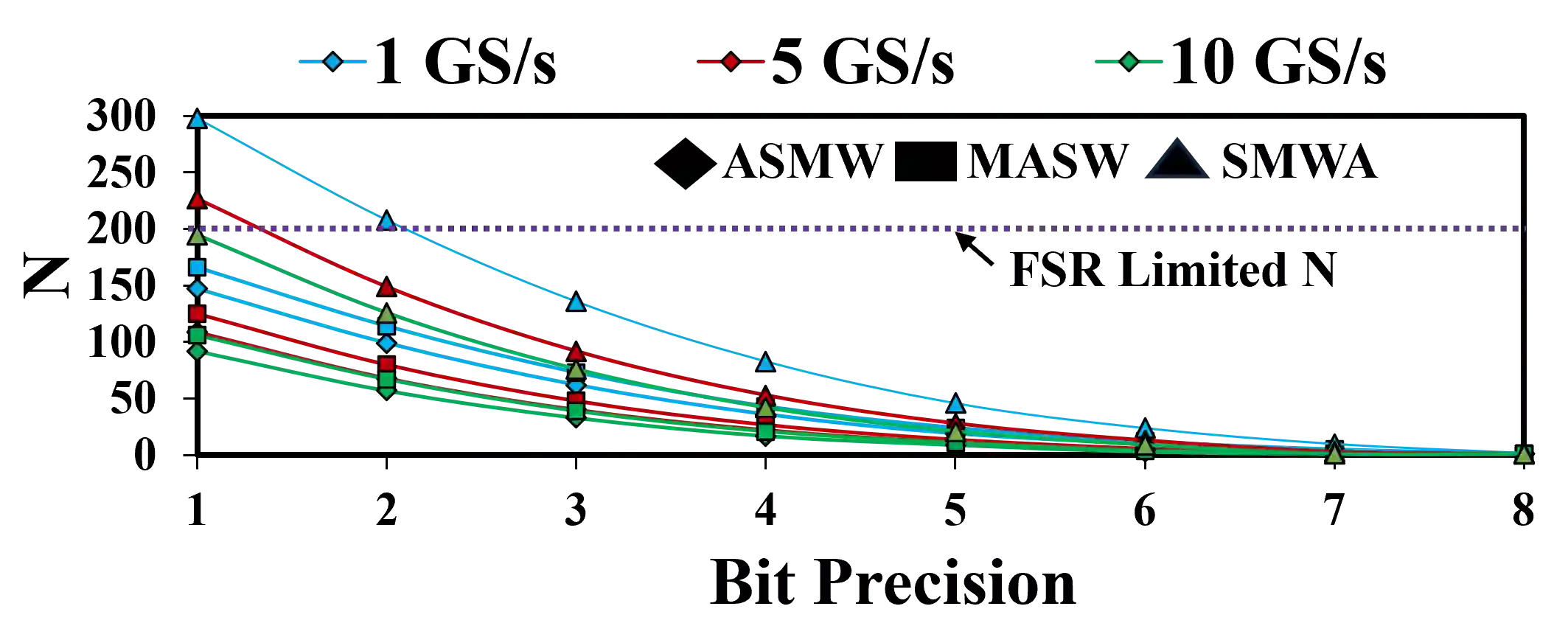
Several microring resonator (MRR) based analog photonic architectures have been proposed to accelerate general matrix-matrix multiplications (GEMMs) in deep neural networks with exceptional throughput and energy efficiency. To implement GEMM functions, these MRR-based architectures, in general, manipulate optical signals in five different ways: (i) Splitting (copying) of multiple optical signals to achieve a certain fan-out, (ii) Aggregation (multiplexing) of multiple optical signals to achieve a certain fan-in, (iii) Modulation of optical signals to imprint input values onto analog signal amplitude, (iv) Weighting of modulated optical signals to achieve analog input-weight multiplication, (v) Summation of optical signals. The MRR-based GEMM accelerators undertake the first four ways of signal manipulation in an arbitrary order ignoring the possible impact of the order of these manipulations on their performance. In this paper, we conduct a detailed analysis of accelerator organizations with three different orders of these manipulations: (1) Modulation-Aggregation-Splitting-Weighting (MASW), (2) Aggregation-Splitting-Modulation-Weighting (ASMW), and (3) Splitting-Modulation-Weighting-Aggregation (SMWA). We show that these organizations affect the crosstalk noise and optical signal losses in different magnitudes, which renders these organizations with different levels of processing parallelism at the circuit level, and different magnitudes of throughput and energy-area efficiency at the system level. Our evaluation results for four CNN models show that SMWA organization achieves up to 4.4$\times$, 5$\times$, and 5.2$\times$ better throughput, energy efficiency, and area-energy efficiency, respectively, compared to ASMW and MASW organizations on average.
翻译:暂无翻译