STRCF for Visual Object Tracking
Learning Spatial-Temporal Regularized Correlation Filters for Visual Tracking
原文:https://arxiv.org/abs/1803.08679
CVPR2018
一、概述及贡献
通过加入temporal regularizer(时间正则化),将基于多张训练样本进行的SRDCF改进为基于单张训练样本的STRCF。改进了原SRDCF不实时、效率低的问题。比原SRDCF方法性能也有了提升。
作为online PA学习方法的一种扩展,STRCF在新的实例来时,更新滤波器不敏感;对新的实例正确分类敏感。使得STRCF的表观模型在目标表观发生剧烈变化时更加鲁棒。
利用ADMM算法解决优化问题。迭代次数少速度快、有闭式解。
使用深度特征的STRCF方法效果能与state-of-the-art方法抗衡。
二、DCF -- SRDCF
(1)、判别式相关滤波跟踪方法因为边界效应问题,效果受到限制。
所谓边界效应,是指在相关滤波方法中样本循环移位后(图b),这样左右连接上下连接的图像边界进行周期性的傅里叶变换后会产生一个噪声。

对这样的样本加余弦窗处理(图像乘上一个余弦窗口将是靠近图像边缘的像素值接近于零。这同样有利于突出靠近中心的目标。)可以减轻噪声影响。但加入余弦窗会产生几个问题
增加计算量
影响滤波器对背景的学习
当目标即将移出框外时,余弦窗抵消了一部分目标有效像素。当目标部 分移出框外时,余弦窗使得能学习的有效像素更少,影响滤波器学习。
(2)、通过强制空间惩罚,SRDCF减轻了边界效应的影响,提高了DCF的性 能,但计算量更大速度下降,判别式目标跟踪的优势无法体现。
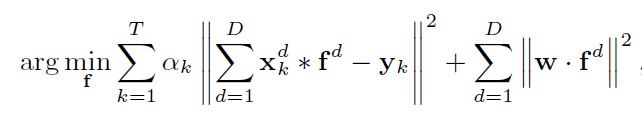
式中w即空间正则化矩阵,f为滤波器,
是每帧目标特征的权重系数,离当前帧越近,系数越大。SRDCF速度慢有两点因素,破坏了循环矩阵结构和选择的优化算法(Gauss-Seidel)不够高效。
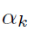 是每帧目标特征的权重系数,离当前帧越近,系数越大。SRDCF速度慢有两点因素,破坏了循环矩阵结构和选择的优化算法(Gauss-Seidel)不够高效。
是每帧目标特征的权重系数,离当前帧越近,系数越大。SRDCF速度慢有两点因素,破坏了循环矩阵结构和选择的优化算法(Gauss-Seidel)不够高效。三、STRCF
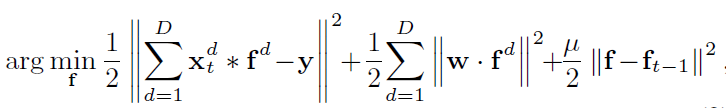
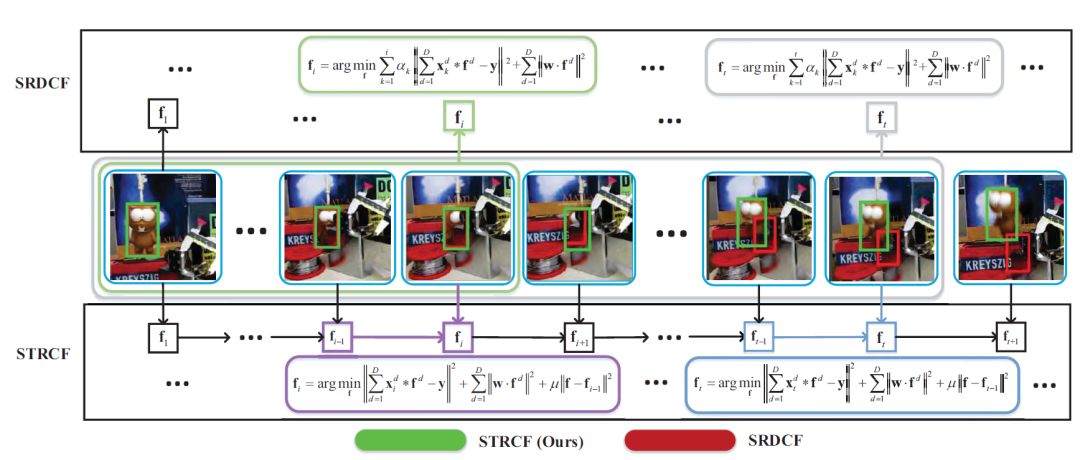
受PA算法启发,加入了时间正则化项
,实验证明μ为16效果最好
occlusion时,SRDCF会因为最近几帧corrupted samples权重系数过大而严重过拟合,而STRCF因为时间正则化项,对模型变化不敏感,缓和了这个问题
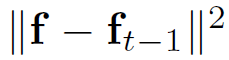 ,实验证明μ为16效果最好
,实验证明μ为16效果最好
ADMM优化方法
假设优化问题:
min f(x)+g(z) s.t. Ax+Bz=c
它的增广拉格朗日形式为:
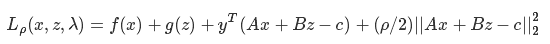
迭代方式为:
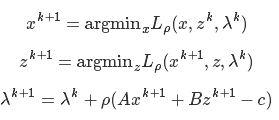
对应到STRCF上
STRCF损失函数的增广拉格朗日形式为:
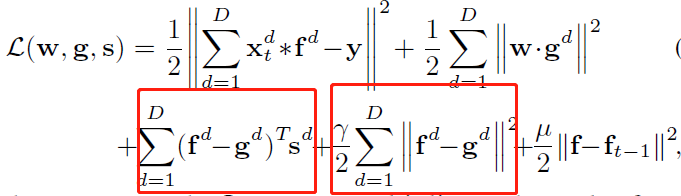
( s.t. f = g )
令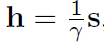
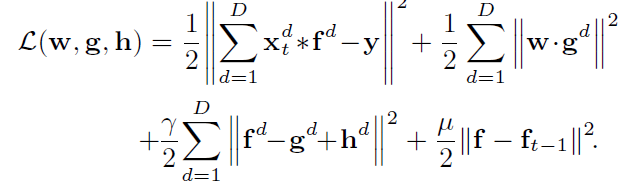
迭代求解:
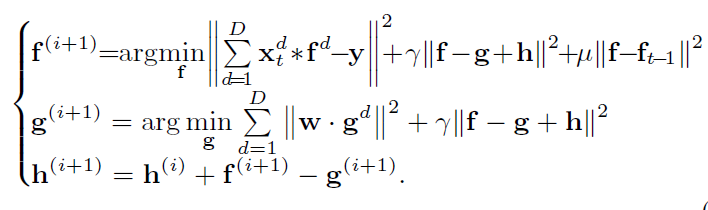
三个子问题都有闭式解,且作者在原文中说明,由经验知迭代次数一般为2次。
子问题f:先将原式转换到傅里叶域,因为某j标签只与所有D个通道上j-th特征和滤波器相关,所以按通道划分滤波器和特征。表示成
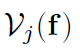
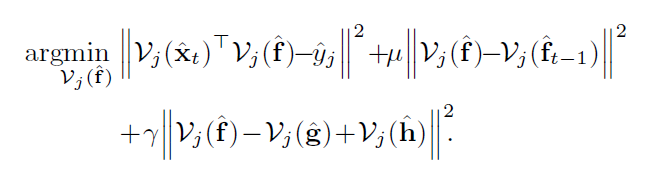
对上式求导为零,得到解:
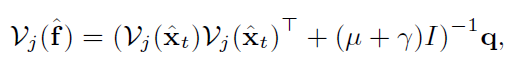
其中:
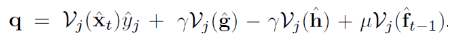
因为
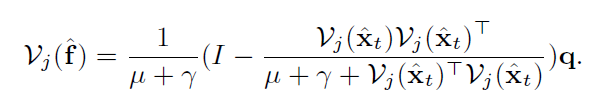
子问题g:有闭式解
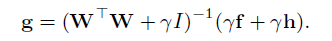
惩罚因子γ的更新:
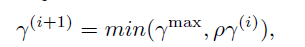
四、实验
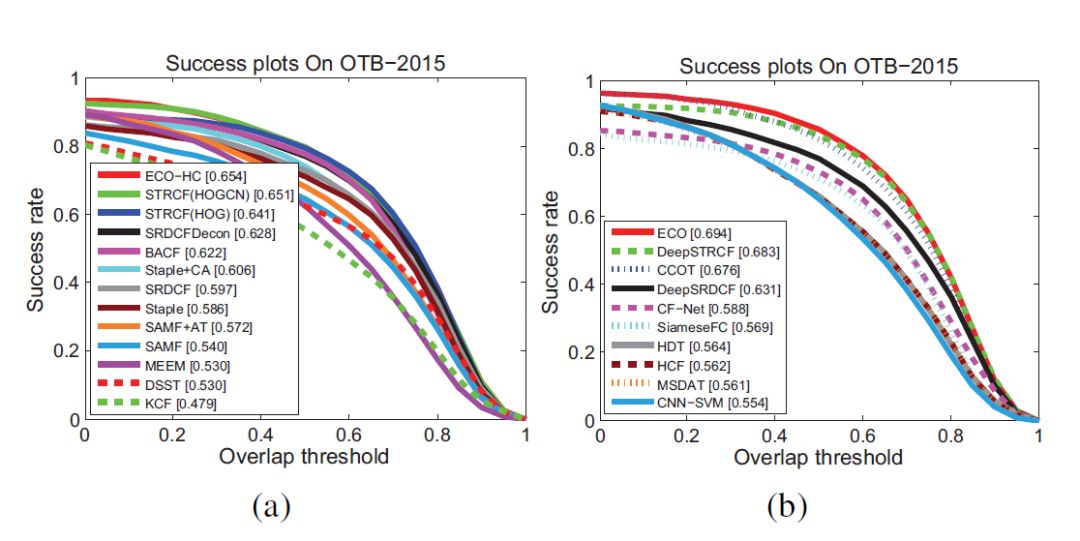
(1)、OTB2015
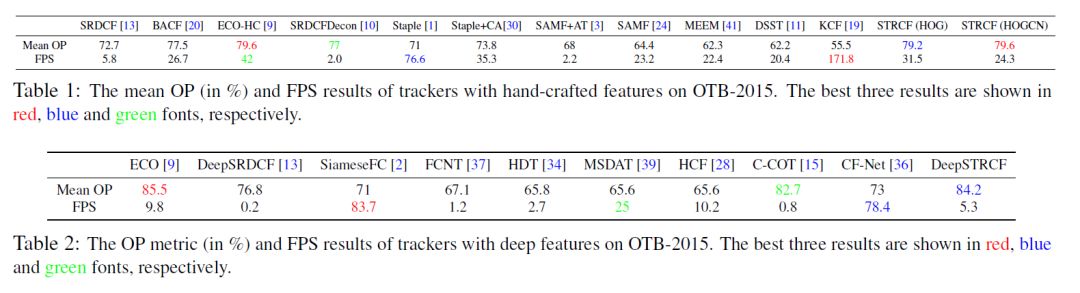
深度特征使用VGG-M的cov3
(2)、hand-crafted特征和深度特征方法比较
(3)、视频分属性实验
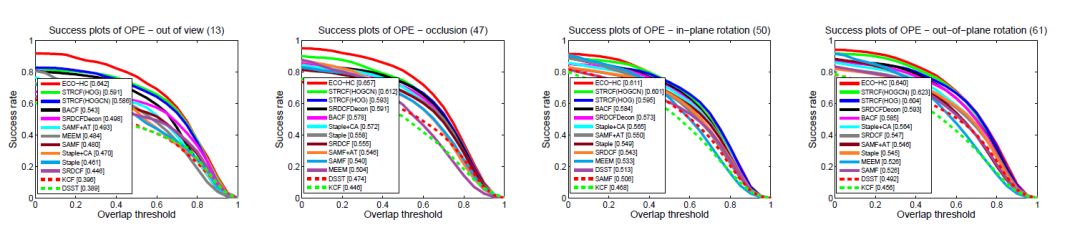
(4)、 VOT2016




