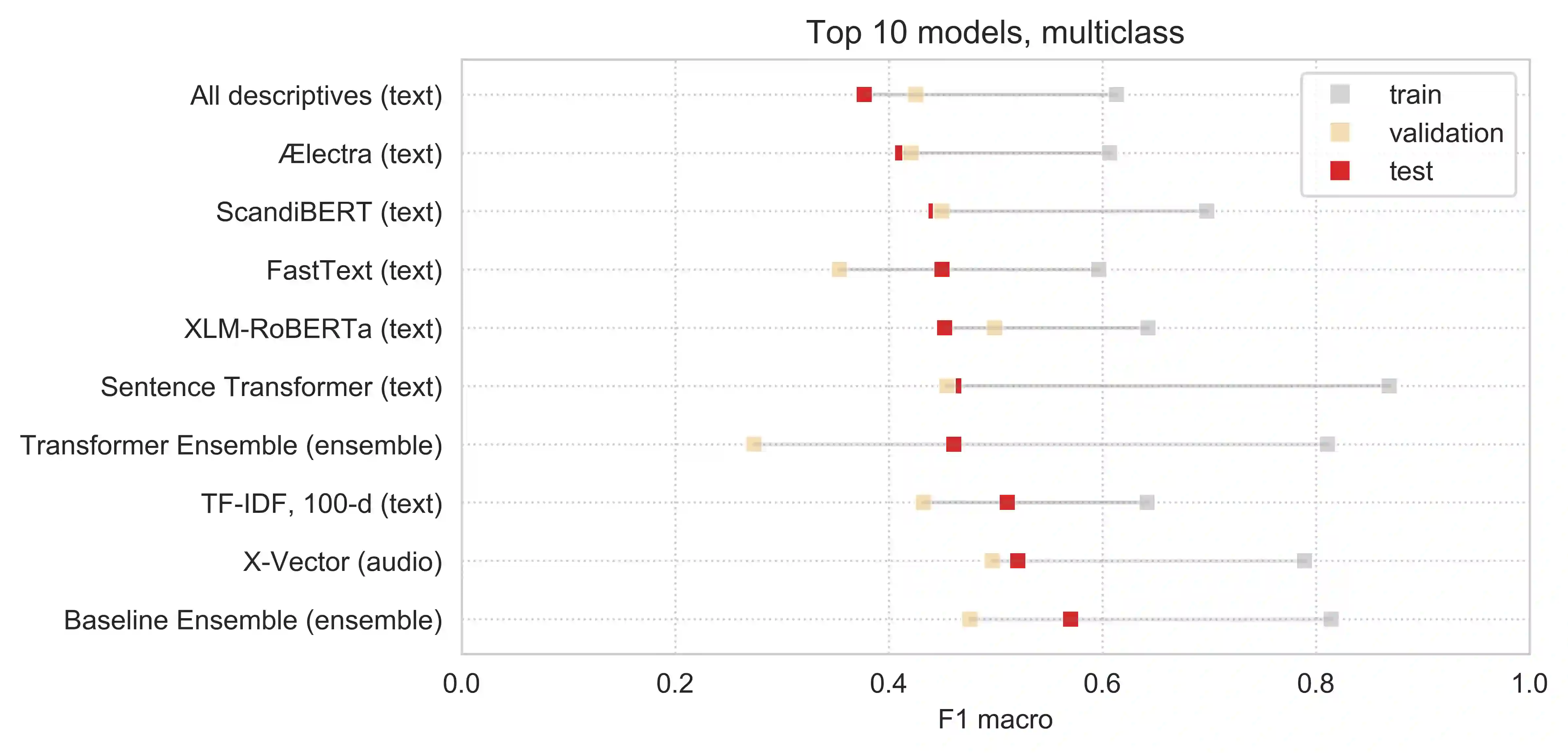
Speech patterns have been identified as potential diagnostic markers for neuropsychiatric conditions. However, most studies only compare a single clinical group to healthy controls, whereas clinical practice often requires differentiating between multiple potential diagnoses (multiclass settings). To address this, we assembled a dataset of repeated recordings from 420 participants (67 with major depressive disorder, 106 with schizophrenia and 46 with autism, as well as matched controls), and tested the performance of a range of conventional machine learning models and advanced Transformer models on both binary and multiclass classification, based on voice and text features. While binary models performed comparably to previous research (F1 scores between 0.54-0.75 for autism spectrum disorder, ASD; 0.67-0.92 for major depressive disorder, MDD; and 0.71-0.83 for schizophrenia); when differentiating between multiple diagnostic groups performance decreased markedly (F1 scores between 0.35-0.44 for ASD, 0.57-0.75 for MDD, 0.15-0.66 for schizophrenia, and 0.38-0.52 macro F1). Combining voice and text-based models yielded increased performance, suggesting that they capture complementary diagnostic information. Our results indicate that models trained on binary classification may learn to rely on markers of generic differences between clinical and non-clinical populations, or markers of clinical features that overlap across conditions, rather than identifying markers specific to individual conditions. We provide recommendations for future research in the field, suggesting increased focus on developing larger transdiagnostic datasets that include more fine-grained clinical features, and that can support the development of models that better capture the complexity of neuropsychiatric conditions and naturalistic diagnostic assessment.
翻译:然而,大多数研究只是将单一临床组与健康控制进行比较,而临床实践往往需要区分多种潜在诊断(多级设置),为此,我们从420名参与者(67名患有严重抑郁症者,106名患有精神分裂症者,46名患有自闭症者,以及相应的控制)收集了一组重复记录的数据集。 当对多个诊断组的性能进行明显下降时,根据声音和文字特征,测试了一系列常规机器学习模型和先进的二进制和多级变异模型在二进制和多级分类方面的性能。虽然二进制模型与以往的研究比较(自闭症谱系特征的F1分在0.54-0.75之间,ASD;主要抑郁症、MDDD和0.77-0.92之间;精神分裂症的0.71-0.83之间;当多种诊断组的性能差异明显下降(ASDASSD在0.35-0.44之间,0.57-075至0.75之间,MDDD,0.76至0.66之间,精神分裂型模型与0.38-052 宏观F1之间), 将语音诊断特征分分分分分分分数; 将语音诊断模型结合分析模型,用于测量分析分析,以分析分析分析,以分析为基础分析为基础分析,以分析为基础分析为基础分析为基础分析,以分析为基础分析基础分析基础分析基础分析基础分析,以分析为基础分析,以分析为基础,以分析基础,以分析为基础,以分析结果分析,以分析,以分析基础分析为基础分析为基础,以分析为基础的模型为基础的模型为基础的模型为基础的模型,以分析为基础的模型为基础的模型为基础的模型为基础的模型为基础的模型为基础,用于为基础的模型,以分析,以分析,以分析,以分析,以分析,以分析,以分析基础,以分析为基础,以分析为基础,以分析基础,以分析基础,以分析基础,以分析基础,以分析基础分析基础分析基础分析基础,以分析基础分析为基础分析为基础,以分析基础的模型为基础,以分析为基础分析为基础分析为基础分析基础分析为基础分析为基础分析基础分析为基础分析为基础分析为基础分析为基础分析为基础的模型,