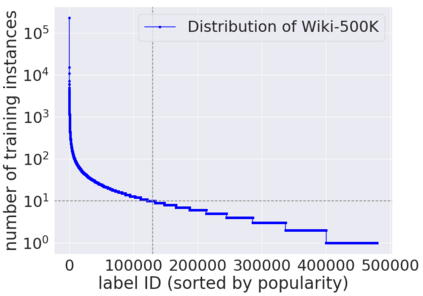
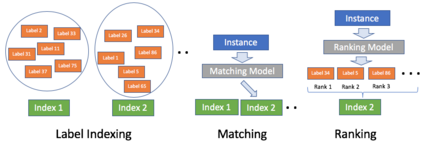
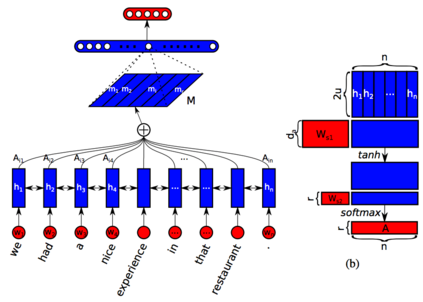
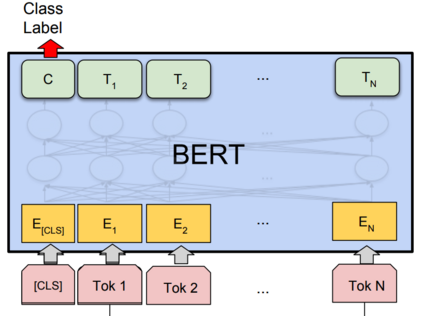
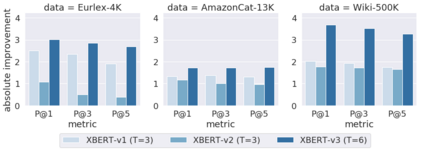
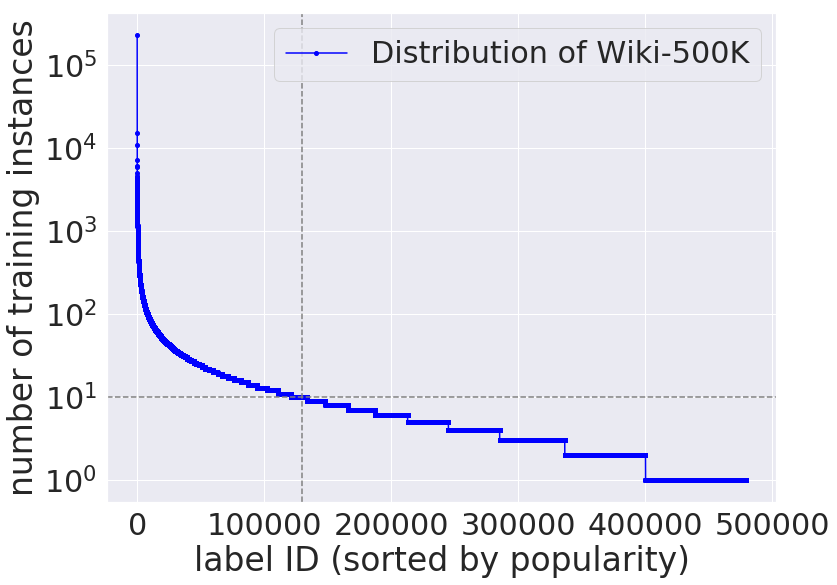
Extreme multi-label text classification (XMC) aims to tag each input text with the most relevant labels from an extremely large label set, such as those that arise in product categorization and e-commerce recommendation. Recently, pretrained language representation models such as BERT achieve remarkable state-of-the-art performance across a wide range of NLP tasks including sentence classification among small label sets (typically fewer than thousands). Indeed, there are several challenges in applying BERT to the XMC problem. The main challenges are: (i) the difficulty of capturing dependencies and correlations among labels, whose features may come from heterogeneous sources, and (ii) the tractability to scale to the extreme label setting as the model size can be very large and scale linearly with the size of the output space. To overcome these challenges, we propose X-BERT, the first feasible attempt to finetune BERT models for a scalable solution to the XMC problem. Specifically, X-BERT leverages both the label and document text to build label representations, which induces semantic label clusters in order to better model label dependencies. At the heart of X-BERT is finetuning BERT models to capture the contextual relations between input text and the induced label clusters. Finally, an ensemble of the different BERT models trained on heterogeneous label clusters leads to our best final model. Empirically, on a Wiki dataset with around 0.5 million labels, X-BERT achieves new state-of-the-art results where the precision@1 reaches 67:80%, a substantial improvement over 32.58%/60.91% of deep learning baseline fastText and competing XMC approach Parabel, respectively. This amounts to a 11.31% relative improvement over Parabel, which is indeed significant since the recent approach SLICE only has 5.53% relative improvement.
翻译:极端多标签文本分类 (XMC) 旨在将每个输入文本标记为来自极大标签组的最相关标签,例如产品分类和电子商务建议中出现的标签。最近,诸如BERT等预先培训的语言代表模型在一系列广泛的NLP任务中取得了显著的最新性能,包括小标签组(通常少于千人)的判刑分类。事实上,在应用BERT到 XMC 问题上存在若干挑战。主要的挑战有:(一) 很难从一个极大标签组中获取最相关的标签的可靠性和相关性,例如产品分类和电子商务建议。最近,BERT等预先培训的语言代表模型的大小可能非常大和范围。为了克服这些挑战,我们提出了X-BERT模型的首次可能的微调模型,用于对 XMC 问题进行扩缩的解决方案。具体地,X-BERT 将标签和文档文本的改进用于构建标签的升级,这会使标签群集的改进达到更精确的等级,以便更精确的标签组别具有更精确的可靠性。在模型上, 5-BER 数据库的内,最后的内, 正在将一个较精确的顺序关系中,而BERBILILIL 。