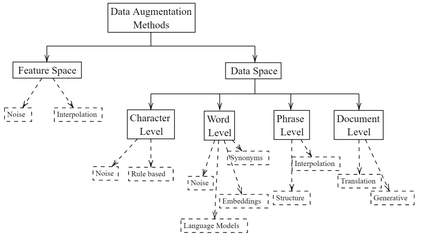
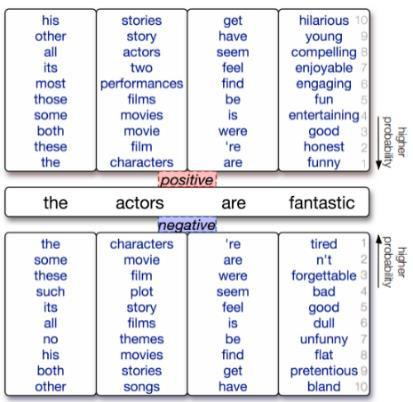
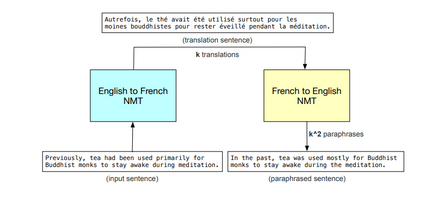
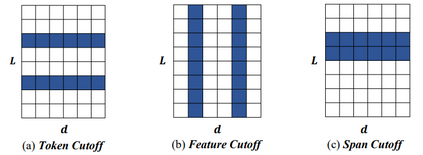
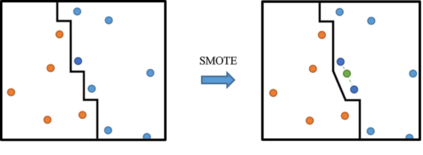
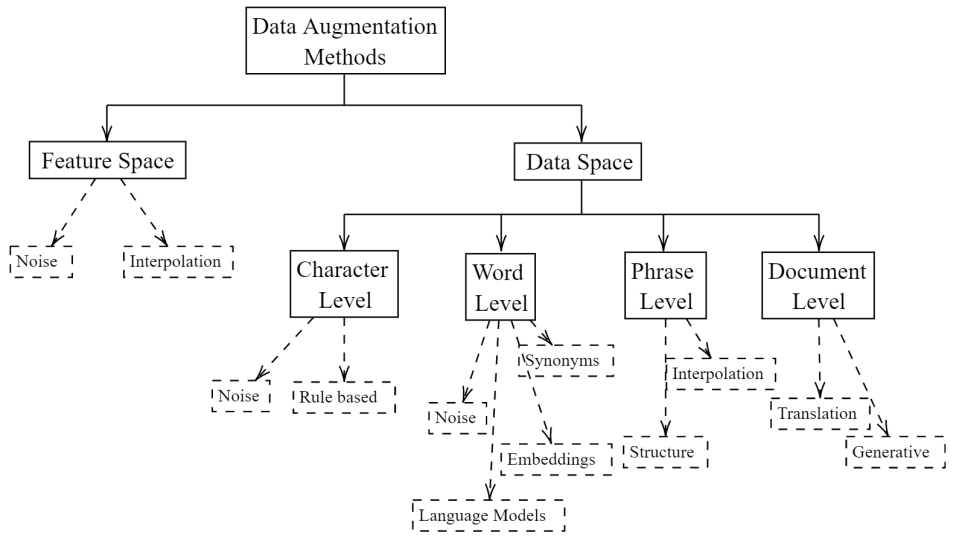
Data augmentation, the artificial creation of training data for machine learning by transformations, is a widely studied research field across machine learning disciplines. While it is useful for increasing the generalization capabilities of a model, it can also address many other challenges and problems, from overcoming a limited amount of training data over regularizing the objective to limiting the amount data used to protect privacy. Based on a precise description of the goals and applications of data augmentation (C1) and a taxonomy for existing works (C2), this survey is concerned with data augmentation methods for textual classification and aims to achieve a concise and comprehensive overview for researchers and practitioners (C3). Derived from the taxonomy, we divided more than 100 methods into 12 different groupings and provide state-of-the-art references expounding which methods are highly promising (C4). Finally, research perspectives that may constitute a building block for future work are given (C5).
翻译:数据增强,即人为地为转换后的机器学习创造培训数据,是一个跨机器学习学科的研究领域,是一个广泛研究的研究领域,虽然对于提高模型的普及能力有用,但也可以解决许多其他挑战和问题,从克服有限数量的培训数据,将目标标准化到限制保护隐私的数据数量,从克服有限数量的培训数据到限制保护隐私的数据数量,根据对数据增强(C1)的目标和应用以及现有工程分类(C2)的准确描述,本调查涉及文字分类的数据增强方法,目的是为研究人员和从业人员提供简明和全面的概览(C3)。 从分类学中,我们将100多种方法分为12个不同的组别,并提供最先进的参考资料,说明哪些方法非常有希望(C4)。 最后,提供了研究观点,这些观点可能构成今后工作的基础(C5)。