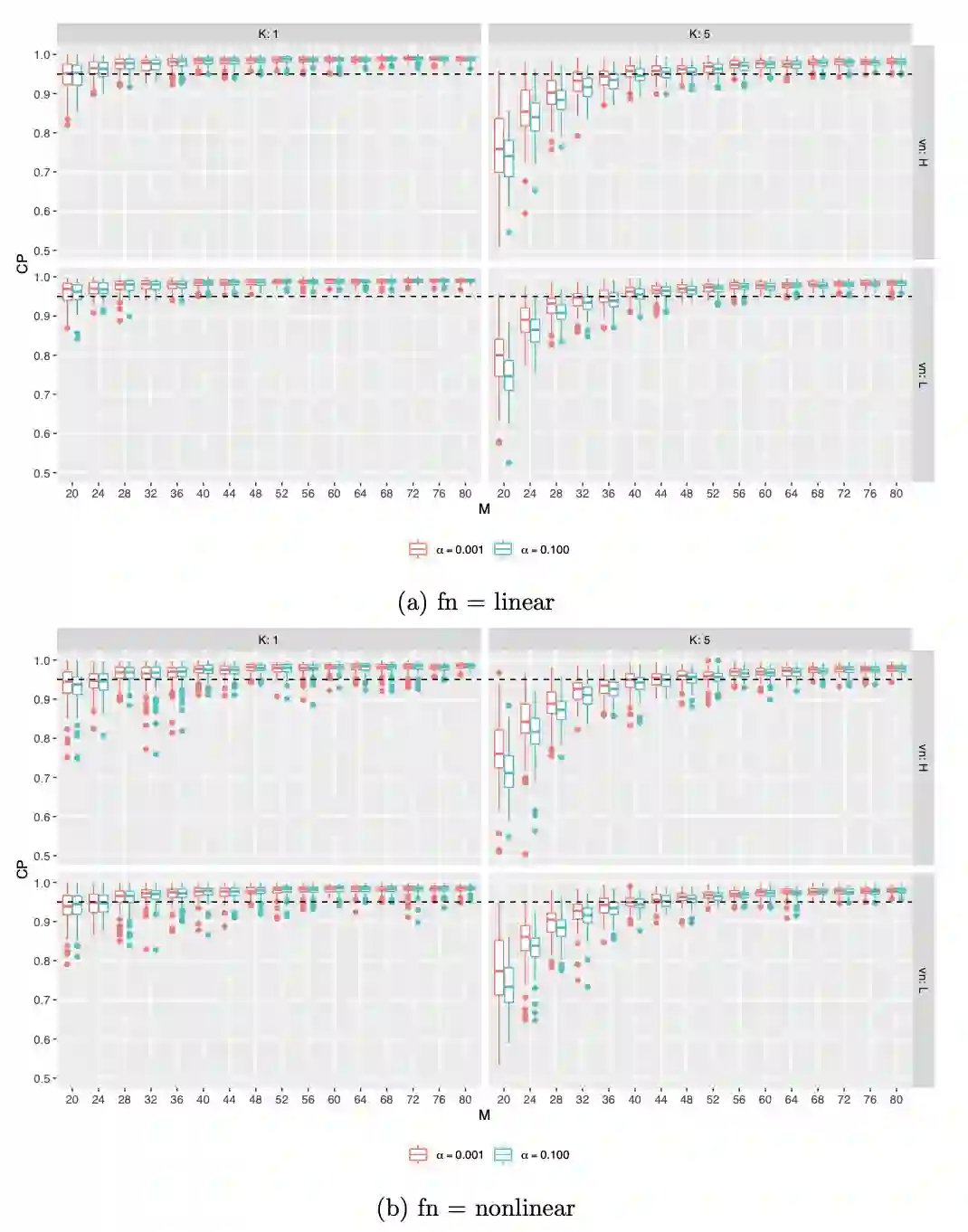
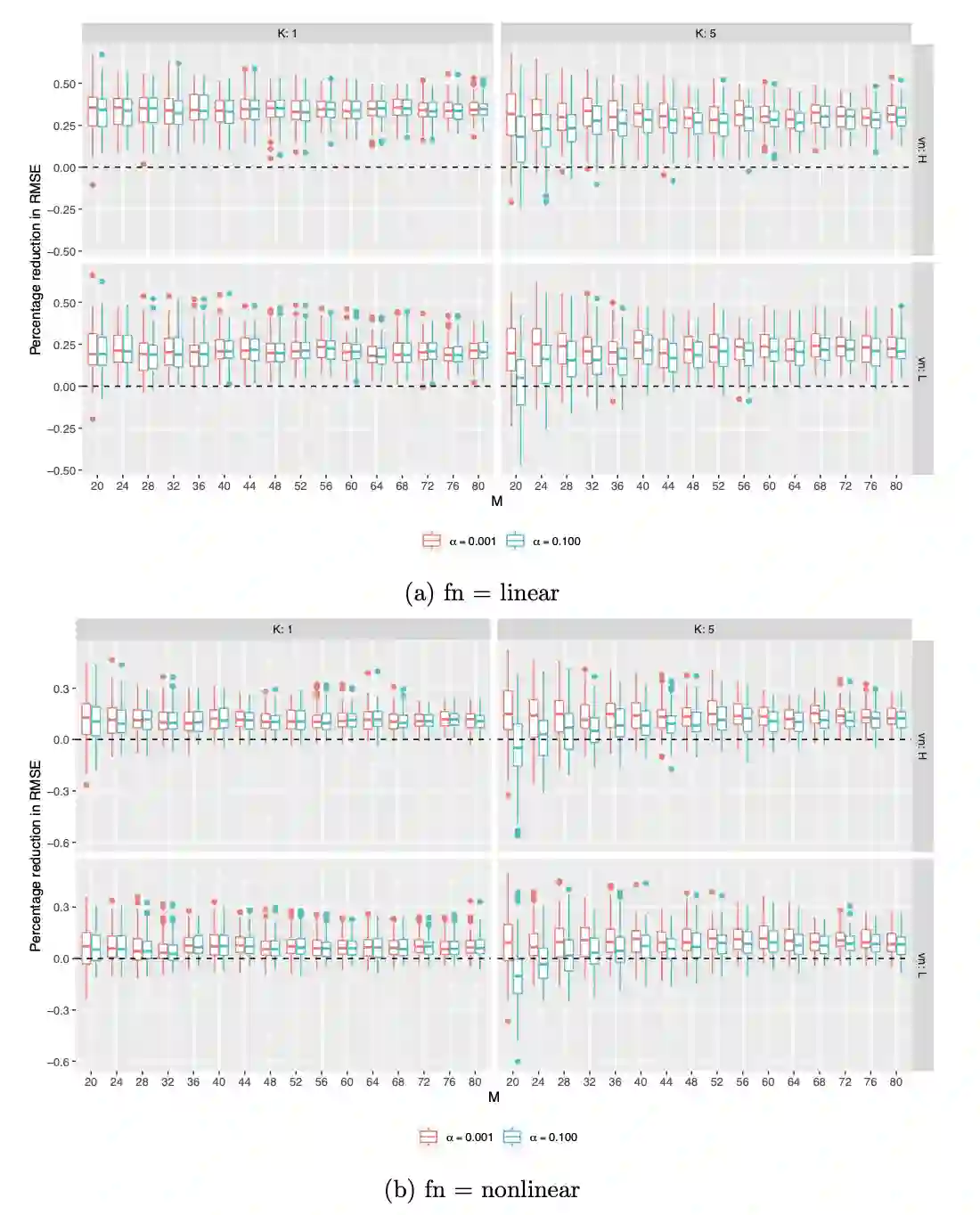
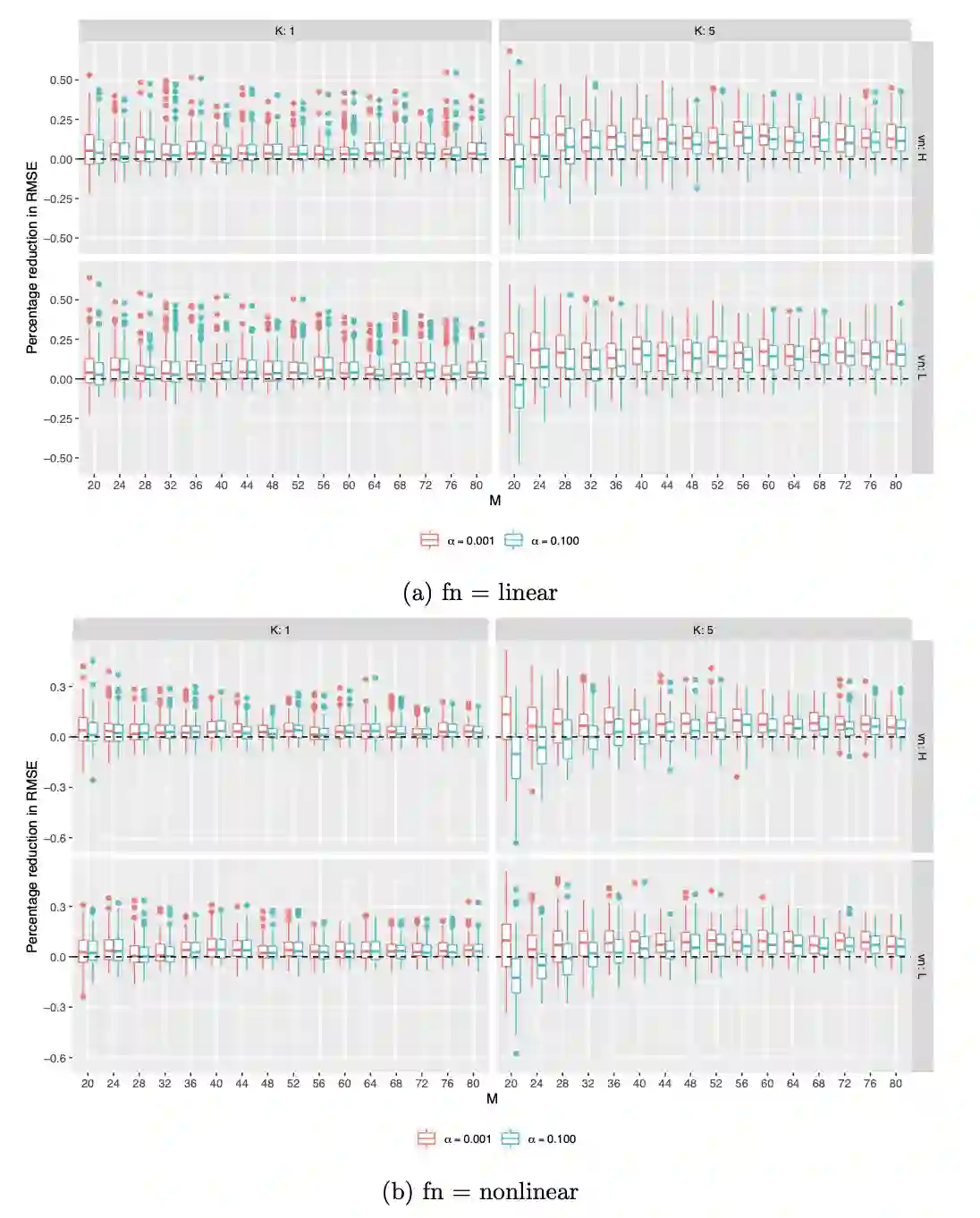
Complete randomization balances covariates on average, but covariate imbalance often exists in finite samples. Rerandomization can ensure covariate balance in the realized experiment by discarding the undesired treatment assignments. Many field experiments in public health and social sciences assign the treatment at the cluster level due to logistical constraints or policy considerations. Moreover, they are frequently combined with rerandomization in the design stage. We refer to cluster rerandomization as a cluster-randomized experiment compounded with rerandomization to balance covariates at the individual or cluster level. Existing asymptotic theory can only deal with rerandomization with treatments assigned at the individual level, leaving that for cluster rerandomization an open problem. To fill the gap, we provide a design-based theory for cluster rerandomization. Moreover, we compare two cluster rerandomization schemes that use prior information on the importance of the covariates: one based on the weighted Euclidean distance and the other based on the Mahalanobis distance with tiers of covariates. We demonstrate that the former dominates the latter with optimal weights and orthogonalized covariates. Last but not least, we discuss the role of covariate adjustment in the analysis stage and recommend covariate-adjusted procedures that can be conveniently implemented by least squares with the associated robust standard errors.
翻译:平均而言,完全随机平衡是完全随机的,但在有限的样本中往往存在共变的不平衡。重新随机化可以通过放弃不理想的治疗任务,确保实际实验的共变平衡。许多公共卫生和社会科学的实地实验由于后勤限制或政策考虑,指定了集群一级的治疗。此外,这些实验往往与设计阶段的重新随机化相结合。我们把集成重新随机化称为群集重新随机化实验,再加上重新随机化,以平衡个体或集群一级的共变。现有的零食理论只能处理个人一级指定的治疗的重新随机化问题,使组群重新随机化成为未决问题。为了填补这一空白,我们为集群集再适应提供了一个基于设计理论的理论。此外,我们比较了使用关于共变式重要性的先前信息的两个群集重整计划:一个基于加权 Eucloidean 距离的实验,另一个基于与不同层次变异的马哈拉诺比距离的试验。我们证明,前一个最小的变异化阶段与最差的变异化阶段没有最佳权重的重的调整,而最差级的变整程序可以用来推导。