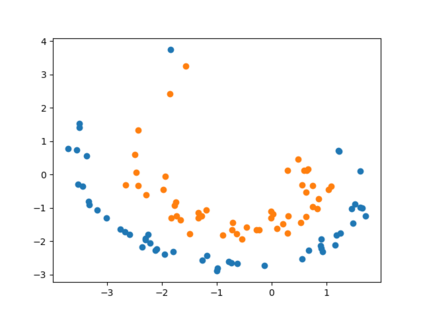
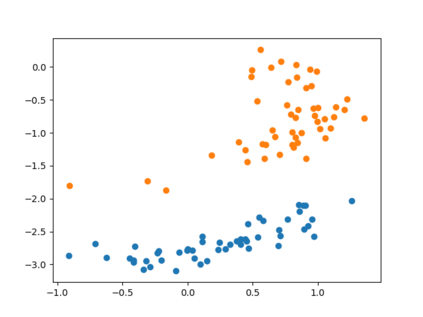
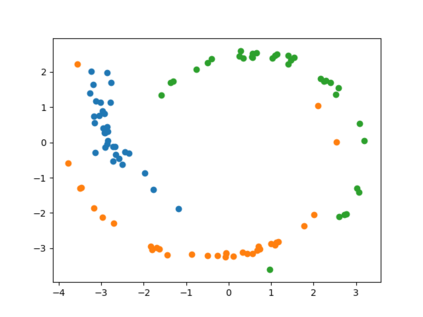
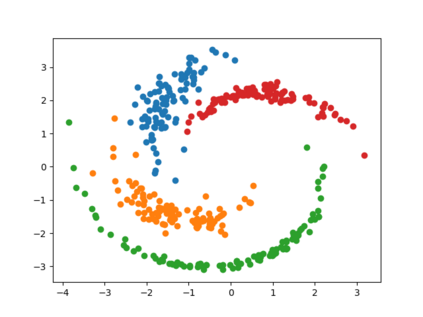
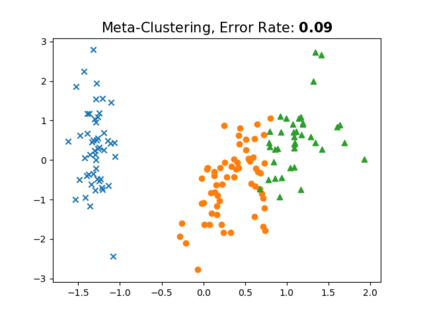
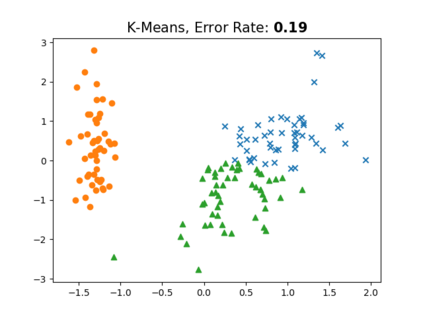
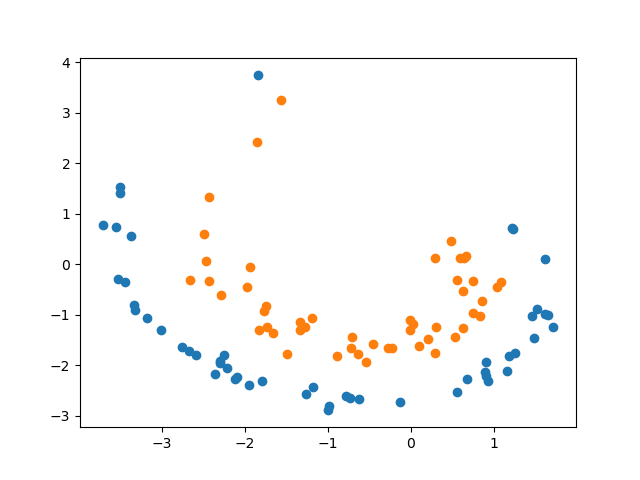
Clustering is one of the most fundamental and wide-spread techniques in exploratory data analysis. Yet, the basic approach to clustering has not really changed: a practitioner hand-picks a task-specific clustering loss to optimize and fit the given data to reveal the underlying cluster structure. Some types of losses---such as k-means, or its non-linear version: kernelized k-means (centroid based), and DBSCAN (density based)---are popular choices due to their good empirical performance on a range of applications. Although every so often the clustering output using these standard losses fails to reveal the underlying structure, and the practitioner has to custom-design their own variation. In this work we take an intrinsically different approach to clustering: rather than fitting a dataset to a specific clustering loss, we train a recurrent model that learns how to cluster. The model uses as training pairs examples of datasets (as input) and its corresponding cluster identities (as output). By providing multiple types of training datasets as inputs, our model has the ability to generalize well on unseen datasets (new clustering tasks). Our experiments reveal that by training on simple synthetically generated datasets or on existing real datasets, we can achieve better clustering performance on unseen real-world datasets when compared with standard benchmark clustering techniques. Our meta clustering model works well even for small datasets where the usual deep learning models tend to perform worse.
翻译:集群是探索性数据分析中最基础和最广泛的技术之一。然而,集群的基本方法并没有真正改变:从业者手工挑选了特定任务分组损失,以优化和适应特定数据以揭示基本组群结构。某些类型的损失类型,如K手段,或其非线性版本:内脏化的 k手段(基于中心机器人)和DBSCAN(基于密度),因其在一系列应用方面的良好经验性能而成为受欢迎的选择。尽管使用这些标准损失的分组产出往往无法揭示其基本结构,而从业者则不得不定制自己的变异。在这项工作中,我们采取了一种本质上不同的分组方法:而不是将数据集安装到具体的组群损失中,我们训练了一种经常性模型,学习数据集(作为投入)及其相应的群集模型(作为产出)。通过提供多种类型的培训数据集作为投入,我们的模型有能力在秘密数据集集(新组群)上进行概括化,在常规数据组群集中,我们通过对常规数据进行比较,我们用现有数据进行更精确的模型,我们用现有数据集群集来进行更精确的实验,我们用现有数据基数的模型来测量。