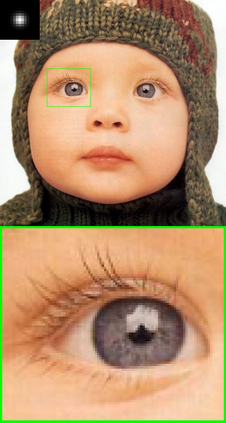
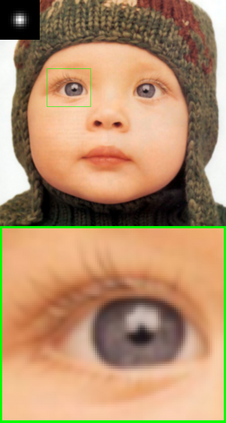
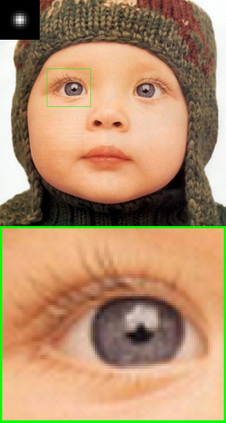
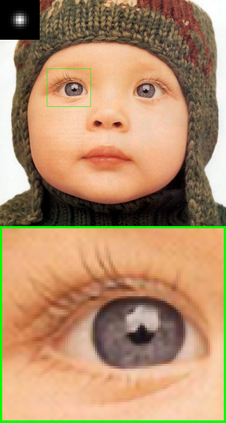
Convolutional neural networks (CNNs) have shown dramatic improvements in single image super-resolution (SISR) by using large-scale external samples. Despite their remarkable performance based on the external dataset, they cannot exploit internal information within a specific image. Another problem is that they are applicable only to the specific condition of data that they are supervised. For instance, the low-resolution (LR) image should be a "bicubic" downsampled noise-free image from a high-resolution (HR) one. To address both issues, zero-shot super-resolution (ZSSR) has been proposed for flexible internal learning. However, they require thousands of gradient updates, i.e., long inference time. In this paper, we present Meta-Transfer Learning for Zero-Shot Super-Resolution (MZSR), which leverages ZSSR. Precisely, it is based on finding a generic initial parameter that is suitable for internal learning. Thus, we can exploit both external and internal information, where one single gradient update can yield quite considerable results. (See Figure 1). With our method, the network can quickly adapt to a given image condition. In this respect, our method can be applied to a large spectrum of image conditions within a fast adaptation process.
翻译:大型外部样本显示,通过使用大型外部样本,单一图像超分辨率(SISSR)的单一图像超分辨率(SISR)有了显著的改善。尽管它们以外部数据集为基础表现显著,但它们无法在特定图像中利用内部信息。另一个问题是,它们只适用于它们所监督的数据的具体条件。例如,低分辨率(LR)图像应该是高分辨率(HR)中“bibibic”下标的无噪音图像。因此,为了解决这两个问题,建议进行灵活的内部学习。但是,它们需要数千个梯度更新,即长期的推断时间。在本文中,我们介绍的是用于ZSSR(MZSR)的Met-Transfer学习系统(MZZSR)。 确切地说,它是基于找到一个适合内部学习的通用初始参数。因此,我们可以利用外部和内部信息,其中一个单一的梯度更新(ZSSRR)可以产生相当可观的结果。(见图1),因此,网络可以快速调整一个图像的频度,从而可以快速调整一个图像状态。