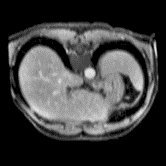
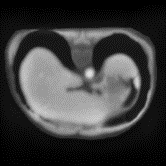
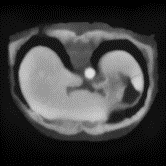
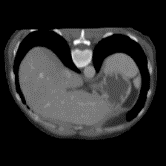
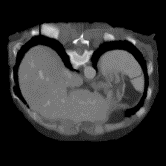
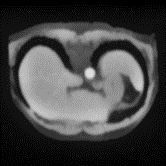
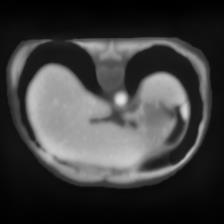
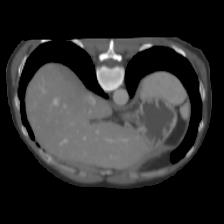
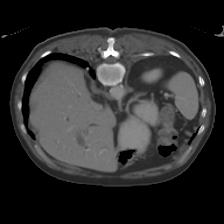
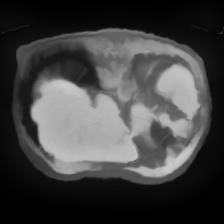
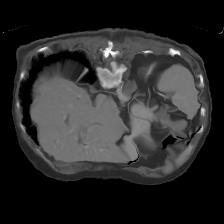
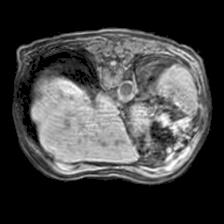
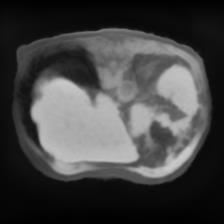
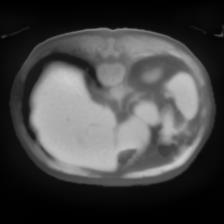
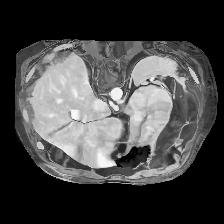
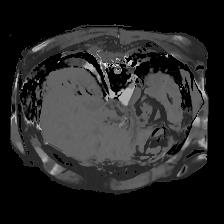
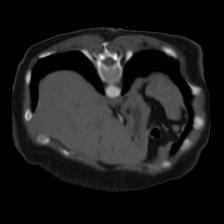
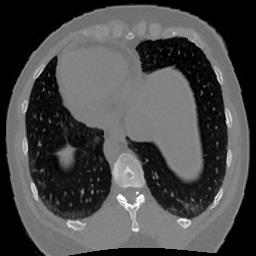
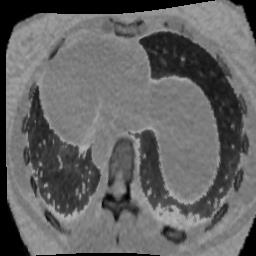
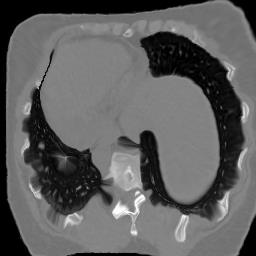
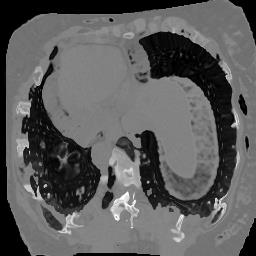
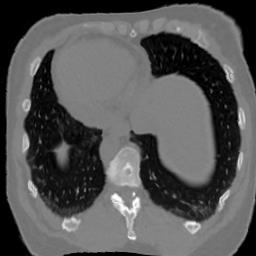
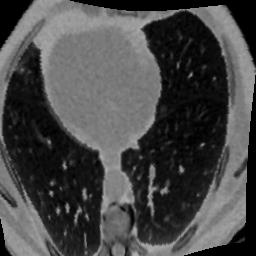
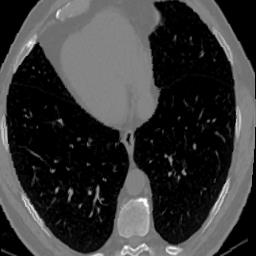
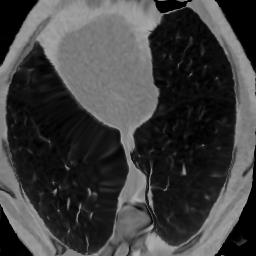
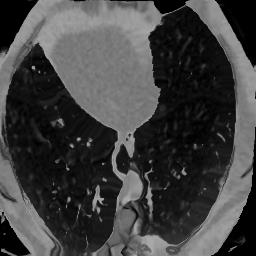
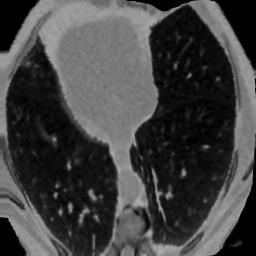
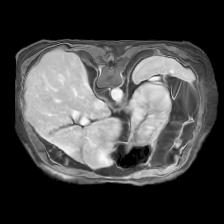
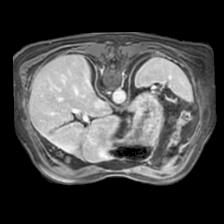
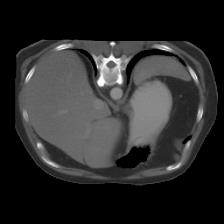
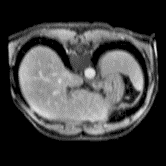
In clinical practice, well-aligned multi-modal images, such as Magnetic Resonance (MR) and Computed Tomography (CT), together can provide complementary information for image-guided therapies. Multi-modal image registration is essential for the accurate alignment of these multi-modal images. However, it remains a very challenging task due to complicated and unknown spatial correspondence between different modalities. In this paper, we propose a novel translation-based unsupervised deformable image registration approach to convert the multi-modal registration problem to a mono-modal one. Specifically, our approach incorporates a discriminator-free translation network to facilitate the training of the registration network and a patchwise contrastive loss to encourage the translation network to preserve object shapes. Furthermore, we propose to replace an adversarial loss, that is widely used in previous multi-modal image registration methods, with a pixel loss in order to integrate the output of translation into the target modality. This leads to an unsupervised method requiring no ground-truth deformation or pairs of aligned images for training. We evaluate four variants of our approach on the public Learn2Reg 2021 datasets \cite{hering2021learn2reg}. The experimental results demonstrate that the proposed architecture achieves state-of-the-art performance. Our code is available at https://github.com/heyblackC/DFMIR.
翻译:在临床实践中,如磁共振(MR)和光谱成像(CT)等非常相近的多模式图像可以一起为图像制导疗法提供补充信息。多模式图像登记对于这些多模式图像的准确匹配至关重要。然而,由于不同模式之间复杂的和未知的空间通信,这仍然是一项非常艰巨的任务。在本文中,我们提议采用新的、基于翻译的、不受监督的变形图像登记方法,将多模式登记问题转换成单一模式。具体地说,我们的方法包括一个无歧视翻译网络,以便利对登记网络的培训,以及一种有偏差的对比性损失,以鼓励翻译网络保存对象形状。此外,我们提议取代在以往多模式图像登记方法中广泛使用的一种对抗性损失,目的是将翻译的输出纳入目标模式。这导致一种不统一的方法,不需要地面图解或对齐图像来进行培训。我们评估了公共学习2MReg20的四种变式方法,我们在公共实验2Regmal-ress productions 2021我们提议的实验性结构中实现了2021号的运行结果。