【论文推荐】最新七篇图像分割相关论文—域适应深度表示学习、循环残差卷积、二值分割、图像合成、无监督跨模态
【导读】专知内容组在昨天推出七篇图像分割(Image Segmentation)相关文章,又推出近期七篇图像分割相关文章,为大家进行介绍,欢迎查看!
8.Deep Representation Learning for Domain Adaptation of Semantic Image Segmentation(语义图像分割的域适应深度表示学习)
作者:Assia Benbihi,Matthieu Geist,Cédric Pradalier
机构:Université de Lorraine
摘要:Deep Convolutional Neural Networks have pushed the state-of-the art for semantic segmentation provided that a large amount of images together with pixel-wise annotations is available. Data collection is expensive and a solution to alleviate it is to use transfer learning. This reduces the amount of annotated data required for the network training but it does not get rid of this heavy processing step. We propose a method of transfer learning without annotations on the target task for datasets with redundant content and distinct pixel distributions. Our method takes advantage of the approximate content alignment of the images between two datasets when the approximation error prevents the reuse of annotation from one dataset to another. Given the annotations for only one dataset, we train a first network in a supervised manner. This network autonomously learns to generate deep data representations relevant to the semantic segmentation. Then the images in the new dataset, we train a new network to generate a deep data representation that matches the one from the first network on the previous dataset. The training consists in a regression between feature maps and does not require any annotations on the new dataset. We show that this method reaches performances similar to a classic transfer learning on the PASCAL VOC dataset with synthetic transformations.
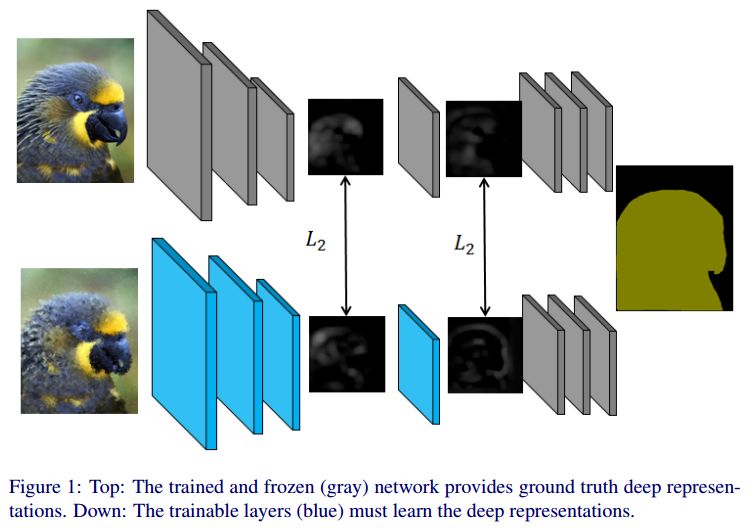
期刊:arXiv, 2018年5月11日
网址:
http://www.zhuanzhi.ai/document/9c7ca20251bbc2e160407c7476f0cbfd
9.Recurrent Residual Convolutional Neural Network based on U-Net (R2U-Net) for Medical Image Segmentation(基于U-Net (R2U-Net)的循环残差卷积神经网络的医学图像分割)
作者:Md Zahangir Alom,Mahmudul Hasan,Chris Yakopcic,Tarek M. Taha,Vijayan K. Asari
摘要:Deep learning (DL) based semantic segmentation methods have been providing state-of-the-art performance in the last few years. More specifically, these techniques have been successfully applied to medical image classification, segmentation, and detection tasks. One deep learning technique, U-Net, has become one of the most popular for these applications. In this paper, we propose a Recurrent Convolutional Neural Network (RCNN) based on U-Net as well as a Recurrent Residual Convolutional Neural Network (RRCNN) based on U-Net models, which are named RU-Net and R2U-Net respectively. The proposed models utilize the power of U-Net, Residual Network, as well as RCNN. There are several advantages of these proposed architectures for segmentation tasks. First, a residual unit helps when training deep architecture. Second, feature accumulation with recurrent residual convolutional layers ensures better feature representation for segmentation tasks. Third, it allows us to design better U-Net architecture with same number of network parameters with better performance for medical image segmentation. The proposed models are tested on three benchmark datasets such as blood vessel segmentation in retina images, skin cancer segmentation, and lung lesion segmentation. The experimental results show superior performance on segmentation tasks compared to equivalent models including U-Net and residual U-Net (ResU-Net).
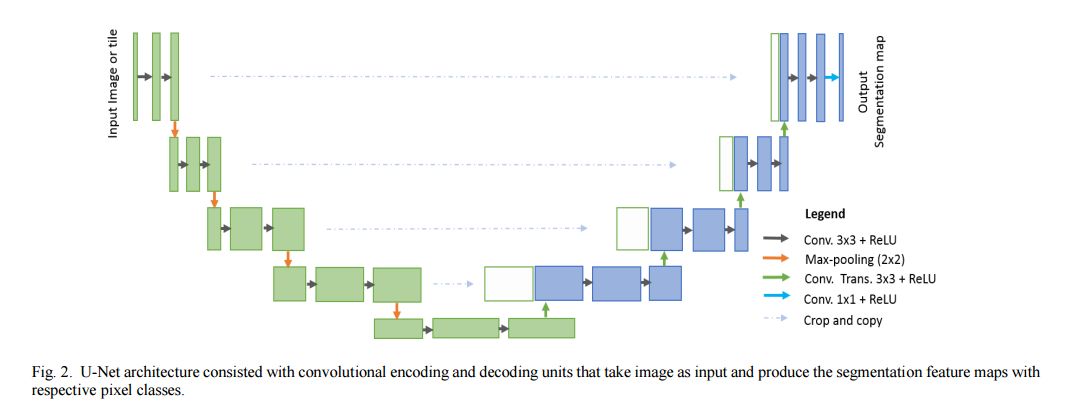
期刊:arXiv, 2018年5月10日
网址:
http://www.zhuanzhi.ai/document/5838379d6cd5c384636ccf5348fe5801
10.Semantic Binary Segmentation using Convolutional Networks without Decoders(使用无解码器的卷积网络的语义二值分割)
作者:Shubhra Aich,William van der Kamp,Ian Stavness
Under review (DeepGlobe CVPR Workshop 2018)
机构:University of Saskatchewan
摘要:In this paper, we propose an efficient architecture for semantic image segmentation using the depth-to-space (D2S) operation. Our D2S model is comprised of a standard CNN encoder followed by a depth-to-space reordering of the final convolutional feature maps; thus eliminating the decoder portion of traditional encoder-decoder segmentation models and reducing computation time almost by half. As a participant of the DeepGlobe Road Extraction competition, we evaluate our models on the corresponding road segmentation dataset. Our highly efficient D2S models exhibit comparable performance to standard segmentation models with much less computational cost.
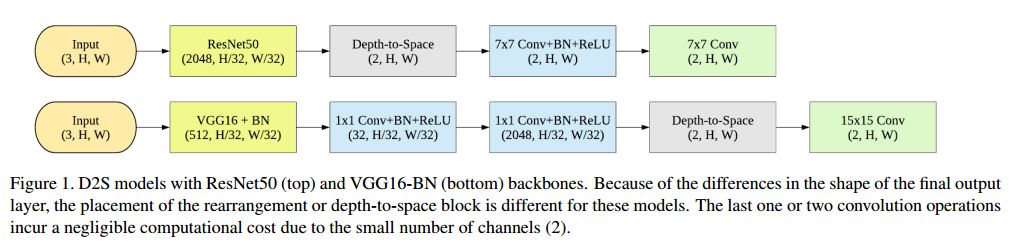
期刊:arXiv, 2018年5月1日
网址:
http://www.zhuanzhi.ai/document/eb7f68461f18d343f9079ddf7a9123cb
11.On the iterative refinement of densely connected representation levels for semantic segmentation(对于语义分割密集连接表示层次的迭代细化)
作者:Arantxa Casanova,Guillem Cucurull,Michal Drozdzal,Adriana Romero,Yoshua Bengio
摘要:State-of-the-art semantic segmentation approaches increase the receptive field of their models by using either a downsampling path composed of poolings/strided convolutions or successive dilated convolutions. However, it is not clear which operation leads to best results. In this paper, we systematically study the differences introduced by distinct receptive field enlargement methods and their impact on the performance of a novel architecture, called Fully Convolutional DenseResNet (FC-DRN). FC-DRN has a densely connected backbone composed of residual networks. Following standard image segmentation architectures, receptive field enlargement operations that change the representation level are interleaved among residual networks. This allows the model to exploit the benefits of both residual and dense connectivity patterns, namely: gradient flow, iterative refinement of representations, multi-scale feature combination and deep supervision. In order to highlight the potential of our model, we test it on the challenging CamVid urban scene understanding benchmark and make the following observations: 1) downsampling operations outperform dilations when the model is trained from scratch, 2) dilations are useful during the finetuning step of the model, 3) coarser representations require less refinement steps, and 4) ResNets (by model construction) are good regularizers, since they can reduce the model capacity when needed. Finally, we compare our architecture to alternative methods and report state-of-the-art result on the Camvid dataset, with at least twice fewer parameters.

期刊:arXiv, 2018年5月1日
网址:
http://www.zhuanzhi.ai/document/db6a6b1624f9db8852d7e01a0b32000d
12.Semi-parametric Image Synthesis(Semi-parametric图像合成)
作者:Xiaojuan Qi,Qifeng Chen,Jiaya Jia,Vladlen Koltun
Published at the Conference on Computer Vision and Pattern Recognition (CVPR 2018)
摘要:We present a semi-parametric approach to photographic image synthesis from semantic layouts. The approach combines the complementary strengths of parametric and nonparametric techniques. The nonparametric component is a memory bank of image segments constructed from a training set of images. Given a novel semantic layout at test time, the memory bank is used to retrieve photographic references that are provided as source material to a deep network. The synthesis is performed by a deep network that draws on the provided photographic material. Experiments on multiple semantic segmentation datasets show that the presented approach yields considerably more realistic images than recent purely parametric techniques. The results are shown in the supplementary video at https://youtu.be/U4Q98lenGLQ

期刊:arXiv, 2018年4月30日
网址:
http://www.zhuanzhi.ai/document/284acdfd21c22e9dbc543b14724ba895
13.Unsupervised Cross-Modality Domain Adaptation of ConvNets for Biomedical Image Segmentations with Adversarial Loss(基于ConvNets无监督跨模态域适应的生物医学图像分割与对抗损失)
作者:Qi Dou,Cheng Ouyang,Cheng Chen,Hao Chen,Pheng-Ann Heng
Accepted to IJCAI 2018
机构:University of Michigan,The Chinese University of Hong Kong
摘要:Convolutional networks (ConvNets) have achieved great successes in various challenging vision tasks. However, the performance of ConvNets would degrade when encountering the domain shift. The domain adaptation is more significant while challenging in the field of biomedical image analysis, where cross-modality data have largely different distributions. Given that annotating the medical data is especially expensive, the supervised transfer learning approaches are not quite optimal. In this paper, we propose an unsupervised domain adaptation framework with adversarial learning for cross-modality biomedical image segmentations. Specifically, our model is based on a dilated fully convolutional network for pixel-wise prediction. Moreover, we build a plug-and-play domain adaptation module (DAM) to map the target input to features which are aligned with source domain feature space. A domain critic module (DCM) is set up for discriminating the feature space of both domains. We optimize the DAM and DCM via an adversarial loss without using any target domain label. Our proposed method is validated by adapting a ConvNet trained with MRI images to unpaired CT data for cardiac structures segmentations, and achieved very promising results.
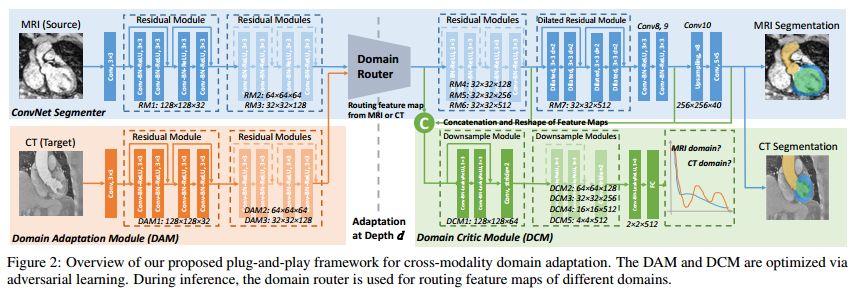
期刊:arXiv, 2018年4月29日
网址:
http://www.zhuanzhi.ai/document/7ad52b9a8325538eaef62a3b577c0d40
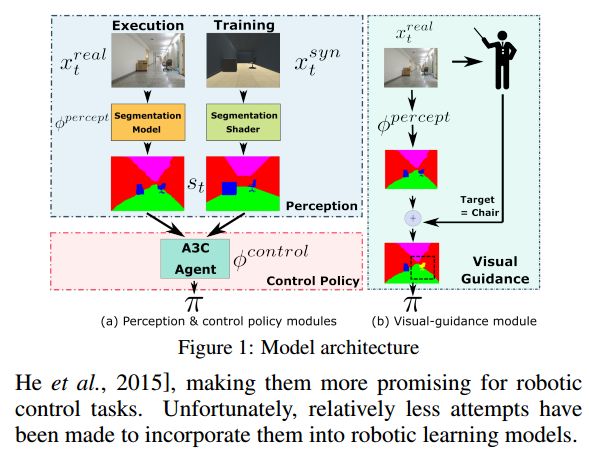
14.Virtual-to-Real: Learning to Control in Visual Semantic Segmentation(虚拟到现实:学习控制视觉语义的分割)
作者:Zhang-Wei Hong,Chen Yu-Ming,Shih-Yang Su,Tzu-Yun Shann,Yi-Hsiang Chang,Hsuan-Kung Yang,Brian Hsi-Lin Ho,Chih-Chieh Tu,Yueh-Chuan Chang,Tsu-Ching Hsiao,Hsin-Wei Hsiao,Sih-Pin Lai,Chun-Yi Lee
accepted by IJCAI-18
机构:National Tsing Hua University,National Chiao Tong University
摘要:Collecting training data from the physical world is usually time-consuming and even dangerous for fragile robots, and thus, recent advances in robot learning advocate the use of simulators as the training platform. Unfortunately, the reality gap between synthetic and real visual data prohibits direct migration of the models trained in virtual worlds to the real world. This paper proposes a modular architecture for tackling the virtual-to-real problem. The proposed architecture separates the learning model into a perception module and a control policy module, and uses semantic image segmentation as the meta representation for relating these two modules. The perception module translates the perceived RGB image to semantic image segmentation. The control policy module is implemented as a deep reinforcement learning agent, which performs actions based on the translated image segmentation. Our architecture is evaluated in an obstacle avoidance task and a target following task. Experimental results show that our architecture significantly outperforms all of the baseline methods in both virtual and real environments, and demonstrates a faster learning curve than them. We also present a detailed analysis for a variety of variant configurations, and validate the transferability of our modular architecture.
期刊:arXiv, 2018年4月29日
网址:
http://www.zhuanzhi.ai/document/82fa0282ad22f9d9fe4dd271fe63397f
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知



