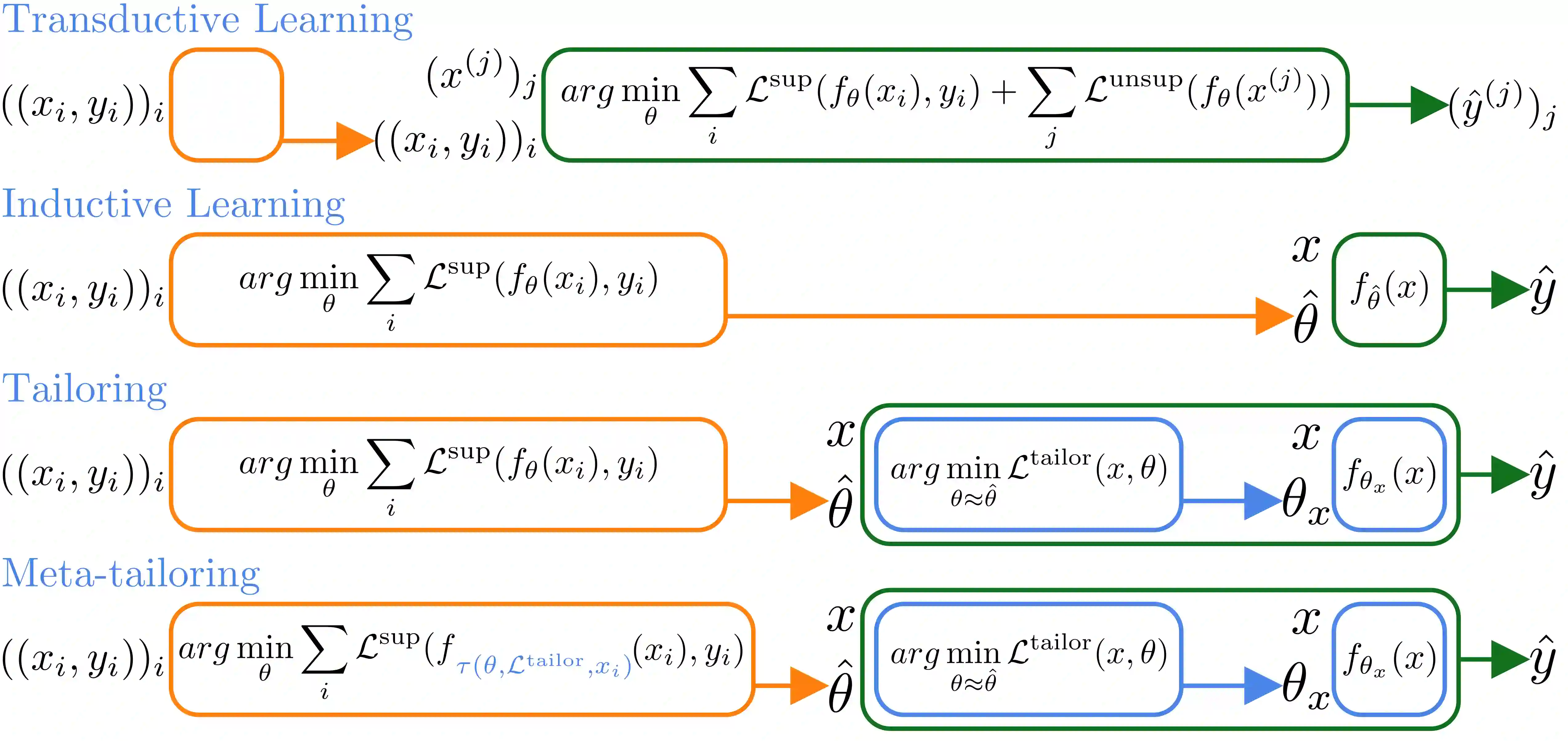
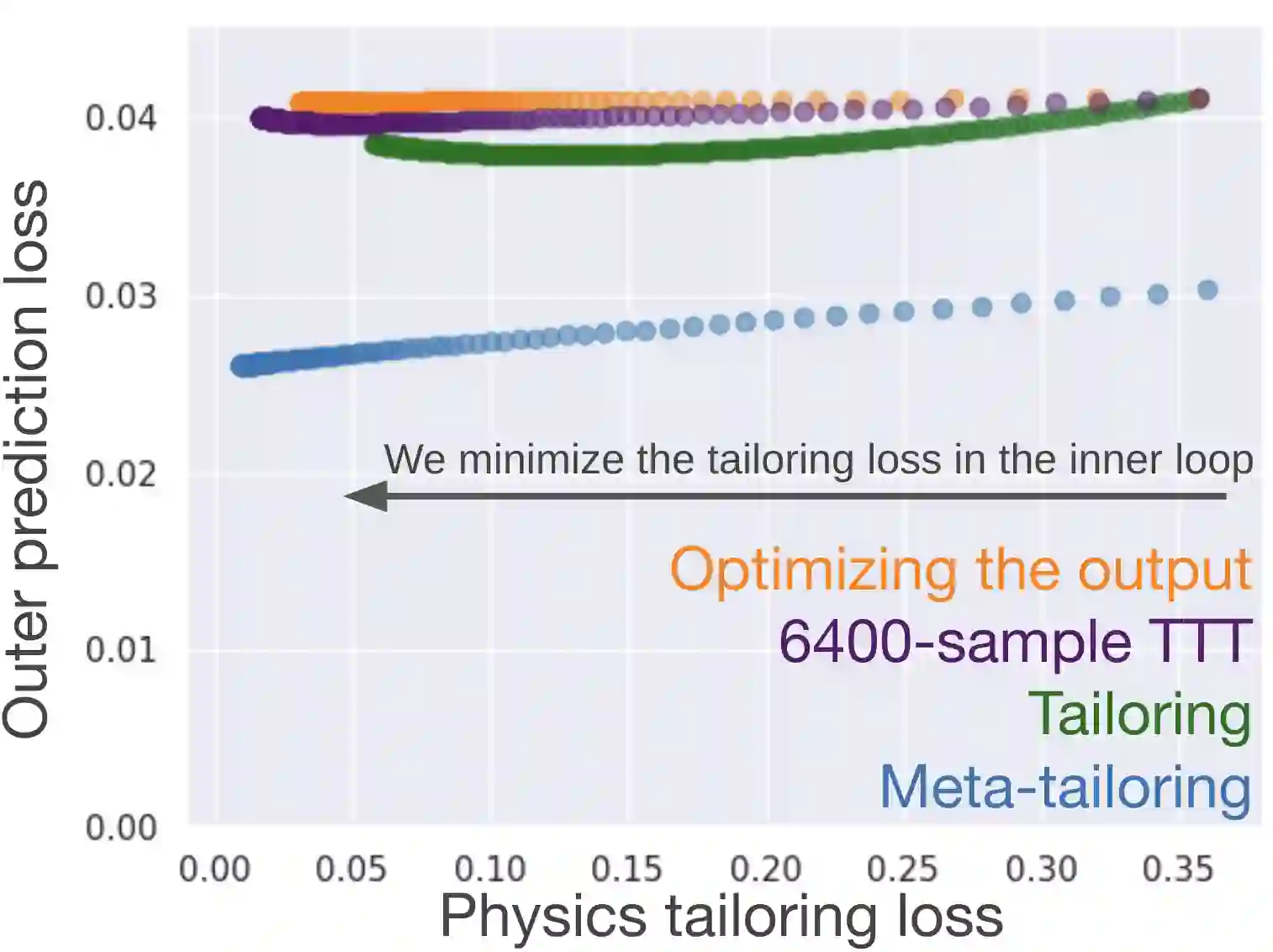
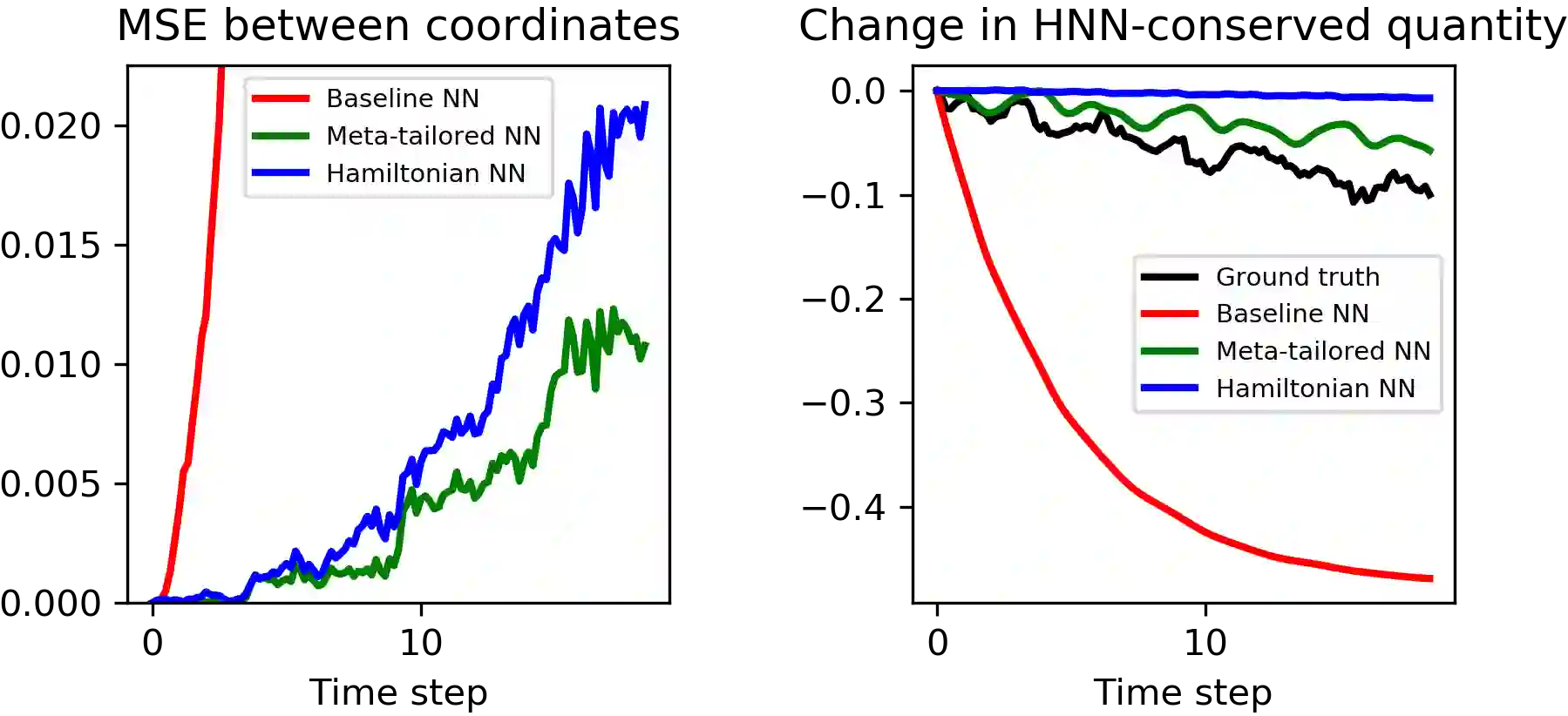
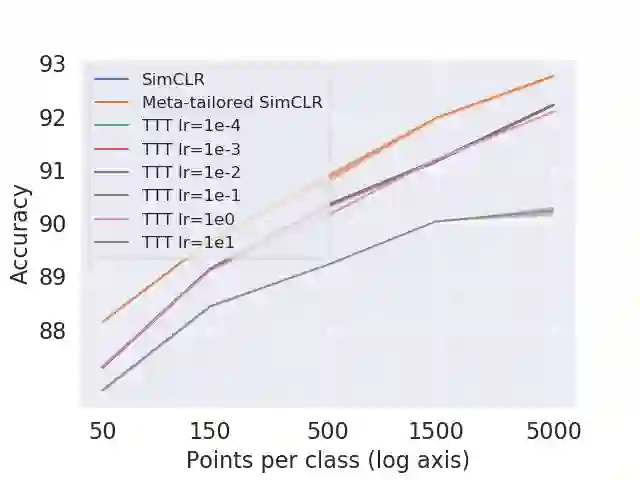
From CNNs to attention mechanisms, encoding inductive biases into neural networks has been a fruitful source of improvement in machine learning. Adding auxiliary losses to the main objective function is a general way of encoding biases that can help networks learn better representations. However, since auxiliary losses are minimized only on training data, they suffer from the same generalization gap as regular task losses. Moreover, by adding a term to the loss function, the model optimizes a different objective than the one we care about. In this work we address both problems: first, we take inspiration from \textit{transductive learning} and note that after receiving an input but before making a prediction, we can fine-tune our networks on any unsupervised loss. We call this process {\em tailoring}, because we customize the model to each input to ensure our prediction satisfies the inductive bias. Second, we formulate {\em meta-tailoring}, a nested optimization similar to that in meta-learning, and train our models to perform well on the task objective after adapting them using an unsupervised loss. The advantages of tailoring and meta-tailoring are discussed theoretically and demonstrated empirically on a diverse set of examples.
翻译:从CNN到关注机制,将情感偏向编码到神经网络,是改进机器学习的一个富有成果的来源。将辅助性损失加到主要目标功能中,是编码偏差的一般方法,可以帮助网络学习更好的表现。然而,由于辅助性损失仅通过培训数据最小化,它们与日常任务损失一样,具有相同的概括性差距。此外,通过在损失函数中增加一个术语,模型优化了与我们所关心的目标不同的目标。在这个工作中,我们处理这两个问题:首先,我们从\ textit{传输性学习}中汲取灵感,并且注意到,在接受输入后,但在作出预测之前,我们可以对网络进行微调,以弥补任何未监督的损失。我们称之为这个过程 {em裁剪},因为我们将每个输入的模型定制成符合我们预测的感应偏差。第二,我们制定与元学习相似的嵌套式优化,在利用未控制的损失调整后,我们模型能够很好地完成任务目标。关于裁缝合和元裁缝合的优点,在理论上和实验上展示了多样化的例子。