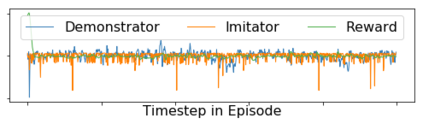
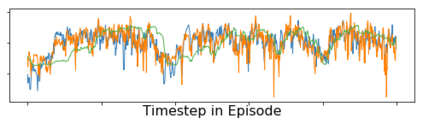
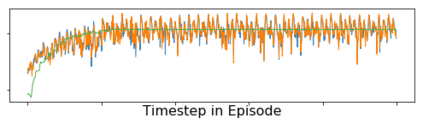
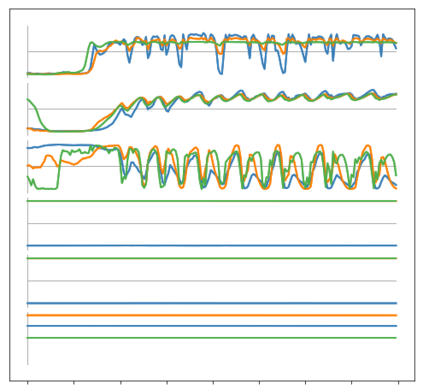
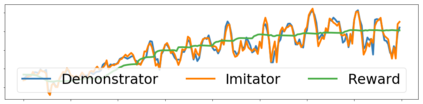
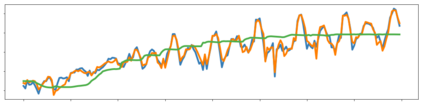
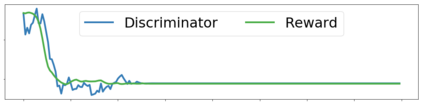
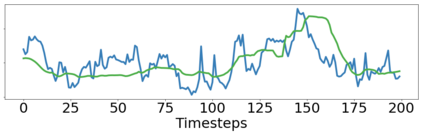
Imitation learning enables agents to reuse and adapt the hard-won expertise of others, offering a solution to several key challenges in learning behavior. Although it is easy to observe behavior in the real-world, the underlying actions may not be accessible. We present a new method for imitation solely from observations that achieves comparable performance to experts on challenging continuous control tasks while also exhibiting robustness in the presence of observations unrelated to the task. Our method, which we call FORM (for "Future Observation Reward Model") is derived from an inverse RL objective and imitates using a model of expert behavior learned by generative modelling of the expert's observations, without needing ground truth actions. We show that FORM performs comparably to a strong baseline IRL method (GAIL) on the DeepMind Control Suite benchmark, while outperforming GAIL in the presence of task-irrelevant features.
翻译:模拟学习使代理商能够重新利用和调整他人来之不易的专门知识,为学习行为中的若干关键挑战提供了解决办法。虽然在现实世界中观察行为是容易的,但基础行动可能无法获取。我们提出一种新的方法,仅从在挑战持续控制任务方面实现类似业绩的观察中模仿专家,同时在与任务无关的观察中表现出强健。我们称之为FORM(未来观测奖赏模型)的方法来自逆向RL目标和仿照,它使用专家观察的基因模型所学的专家行为模型,而不需要地面真相行动。我们表明,FORM在深海控制套件基准上比强的IRL(GAIL)方法(GAIL)具有可比性,同时在任务相关特征面前比GAIL(GAIL)高。