【论文推荐】最新6篇机器翻译相关论文—词性和语义标注任务、变分递归神经机器翻译、文学语料、神经后缀预测、重构模型
【导读】专知内容组整理了最近六篇机器翻译(Machine Translation)相关文章,为大家进行介绍,欢迎查看!
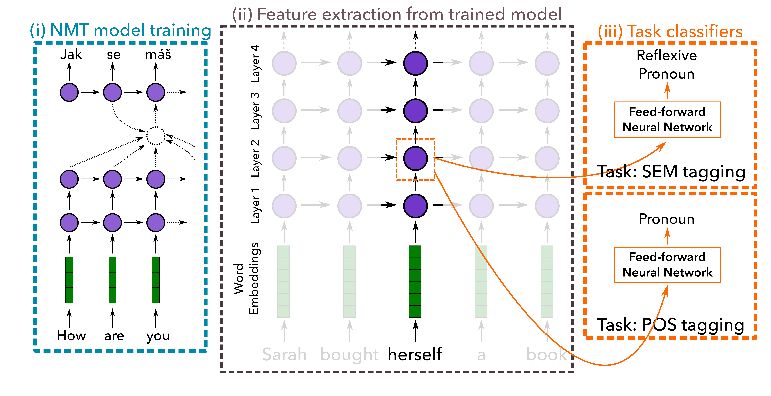
1. Evaluating Layers of Representation in Neural Machine Translation on Part-of-Speech and Semantic Tagging Tasks(评估神经机器翻译的表示层在词性和语义标注任务下能力)
作者:Yonatan Belinkov,Lluís Màrquez,Hassan Sajjad,Nadir Durrani,Fahim Dalvi,James Glass
摘要:While neural machine translation (NMT) models provide improved translation quality in an elegant, end-to-end framework, it is less clear what they learn about language. Recent work has started evaluating the quality of vector representations learned by NMT models on morphological and syntactic tasks. In this paper, we investigate the representations learned at different layers of NMT encoders. We train NMT systems on parallel data and use the trained models to extract features for training a classifier on two tasks: part-of-speech and semantic tagging. We then measure the performance of the classifier as a proxy to the quality of the original NMT model for the given task. Our quantitative analysis yields interesting insights regarding representation learning in NMT models. For instance, we find that higher layers are better at learning semantics while lower layers tend to be better for part-of-speech tagging. We also observe little effect of the target language on source-side representations, especially with higher quality NMT models.
期刊:arXiv, 2018年1月24日
网址:
http://www.zhuanzhi.ai/document/b9b8847279bdeffdd79e705d8924fb4a
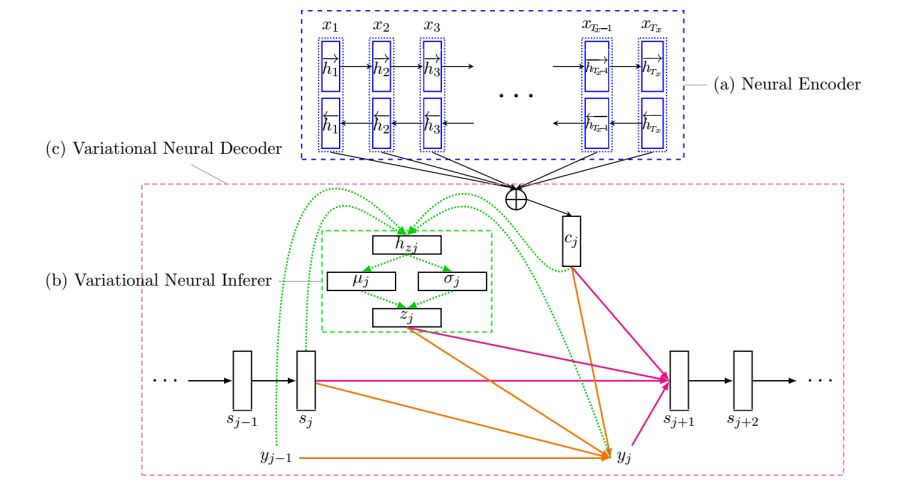
2. Variational Recurrent Neural Machine Translation(变分递归神经机器翻译)
作者:Jinsong Su,Shan Wu,Deyi Xiong,Yaojie Lu,Xianpei Han,Biao Zhang
摘要:Partially inspired by successful applications of variational recurrent neural networks, we propose a novel variational recurrent neural machine translation (VRNMT) model in this paper. Different from the variational NMT, VRNMT introduces a series of latent random variables to model the translation procedure of a sentence in a generative way, instead of a single latent variable. Specifically, the latent random variables are included into the hidden states of the NMT decoder with elements from the variational autoencoder. In this way, these variables are recurrently generated, which enables them to further capture strong and complex dependencies among the output translations at different timesteps. In order to deal with the challenges in performing efficient posterior inference and large-scale training during the incorporation of latent variables, we build a neural posterior approximator, and equip it with a reparameterization technique to estimate the variational lower bound. Experiments on Chinese-English and English-German translation tasks demonstrate that the proposed model achieves significant improvements over both the conventional and variational NMT models.
期刊:arXiv, 2018年1月16日
网址:
http://www.zhuanzhi.ai/document/134ec3e6bca0ee744054d5a7c3f3b01f
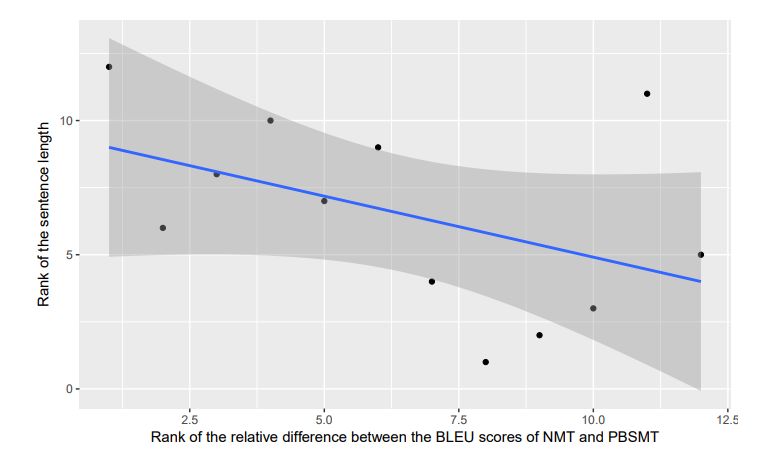
3. What Level of Quality can Neural Machine Translation Attain on Literary Text?(神经机器翻译能在文学语料上表现出什么样的水平?)
作者:Antonio Toral,Andy Way
摘要:Given the rise of a new approach to MT, Neural MT (NMT), and its promising performance on different text types, we assess the translation quality it can attain on what is perceived to be the greatest challenge for MT: literary text. Specifically, we target novels, arguably the most popular type of literary text. We build a literary-adapted NMT system for the English-to-Catalan translation direction and evaluate it against a system pertaining to the previous dominant paradigm in MT: statistical phrase-based MT (PBSMT). To this end, for the first time we train MT systems, both NMT and PBSMT, on large amounts of literary text (over 100 million words) and evaluate them on a set of twelve widely known novels spanning from the the 1920s to the present day. According to the BLEU automatic evaluation metric, NMT is significantly better than PBSMT (p < 0.01) on all the novels considered. Overall, NMT results in a 11% relative improvement (3 points absolute) over PBSMT. A complementary human evaluation on three of the books shows that between 17% and 34% of the translations, depending on the book, produced by NMT (versus 8% and 20% with PBSMT) are perceived by native speakers of the target language to be of equivalent quality to translations produced by a professional human translator.
期刊:arXiv, 2018年1月16日
网址:
http://www.zhuanzhi.ai/document/20a7227320b44ac162c6ec60dac869db
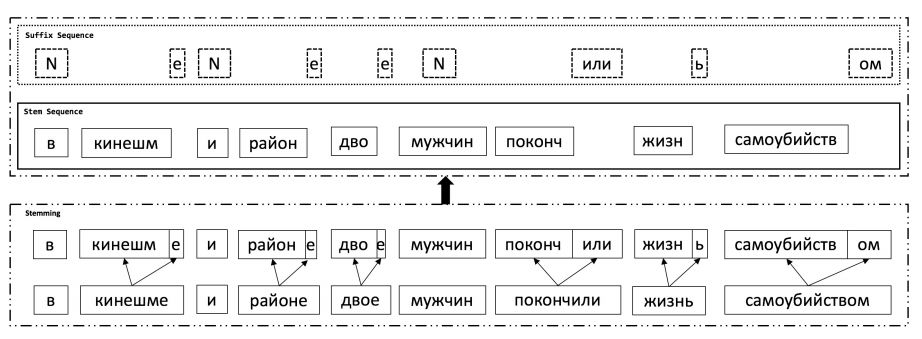
4. Improved English to Russian Translation by Neural Suffix Prediction(利用神经后缀预测来增强英语向俄语的翻译)
作者:Kai Song,Yue Zhang,Min Zhang,Weihua Luo
摘要:Neural machine translation (NMT) suffers a performance deficiency when a limited vocabulary fails to cover the source or target side adequately, which happens frequently when dealing with morphologically rich languages. To address this problem, previous work focused on adjusting translation granularity or expanding the vocabulary size. However, morphological information is relatively under-considered in NMT architectures, which may further improve translation quality. We propose a novel method, which can not only reduce data sparsity but also model morphology through a simple but effective mechanism. By predicting the stem and suffix separately during decoding, our system achieves an improvement of up to 1.98 BLEU compared with previous work on English to Russian translation. Our method is orthogonal to different NMT architectures and stably gains improvements on various domains.
期刊:arXiv, 2018年1月11日
网址:
http://www.zhuanzhi.ai/document/0a7eb9fede3215e57d9c25764d4ec440
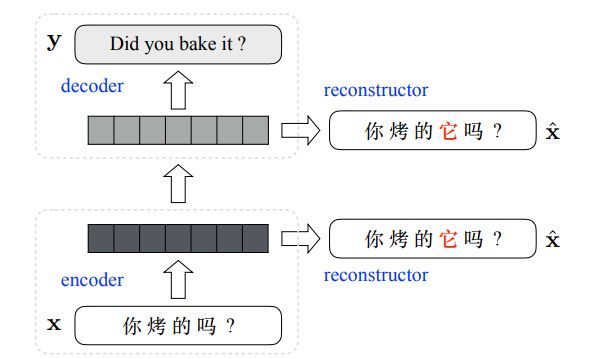
5. Translating Pro-Drop Languages with Reconstruction Models(用重构模型来翻译Pro-Drop类型的语言)
作者:Longyue Wang,Zhaopeng Tu,Shuming Shi,Tong Zhang,Yvette Graham,Qun Liu
摘要:Pronouns are frequently omitted in pro-drop languages, such as Chinese, generally leading to significant challenges with respect to the production of complete translations. To date, very little attention has been paid to the dropped pronoun (DP) problem within neural machine translation (NMT). In this work, we propose a novel reconstruction-based approach to alleviating DP translation problems for NMT models. Firstly, DPs within all source sentences are automatically annotated with parallel information extracted from the bilingual training corpus. Next, the annotated source sentence is reconstructed from hidden representations in the NMT model. With auxiliary training objectives, in terms of reconstruction scores, the parameters associated with the NMT model are guided to produce enhanced hidden representations that are encouraged as much as possible to embed annotated DP information. Experimental results on both Chinese-English and Japanese-English dialogue translation tasks show that the proposed approach significantly and consistently improves translation performance over a strong NMT baseline, which is directly built on the training data annotated with DPs.
期刊:arXiv, 2018年1月10日
网址:
http://www.zhuanzhi.ai/document/b7a486c97594594dc2f8a85de6de6fd7
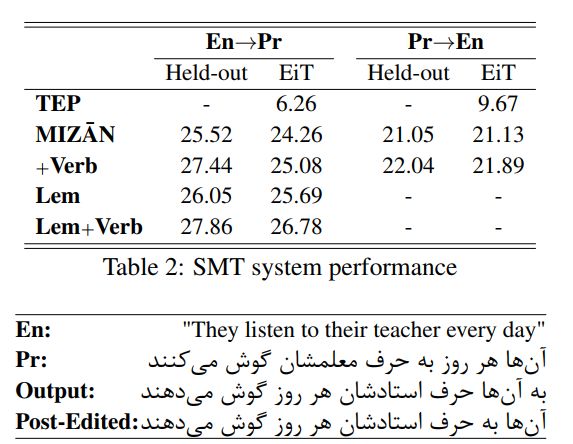
6. MIZAN: A Large Persian-English Parallel Corpus(MIZAN:一个大型的波斯英语平行语料库)
作者:Omid Kashefi
摘要:One of the most major and essential tasks in natural language processing is machine translation that is now highly dependent upon multilingual parallel corpora. Through this paper, we introduce the biggest Persian-English parallel corpus with more than one million sentence pairs collected from masterpieces of literature. We also present acquisition process and statistics of the corpus, and experiment a base-line statistical machine translation system using the corpus.
期刊:arXiv, 2018年1月7日
网址:
http://www.zhuanzhi.ai/document/d96d21e6ef0306adbdcc6b8b6282b87d
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!




