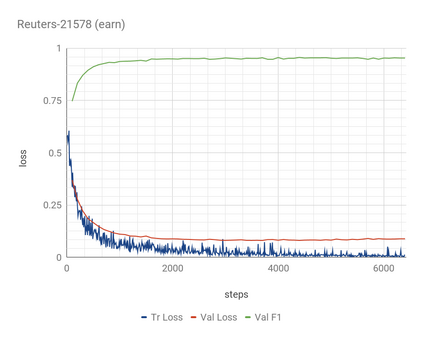
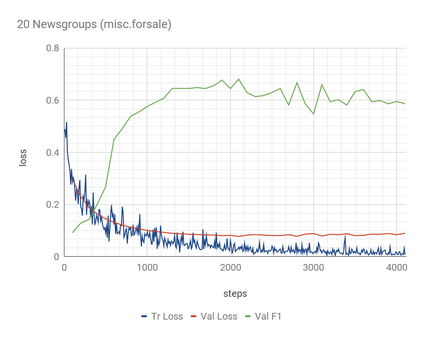
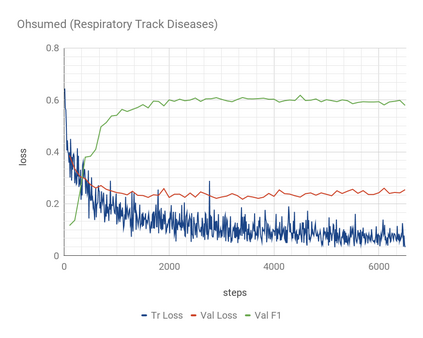
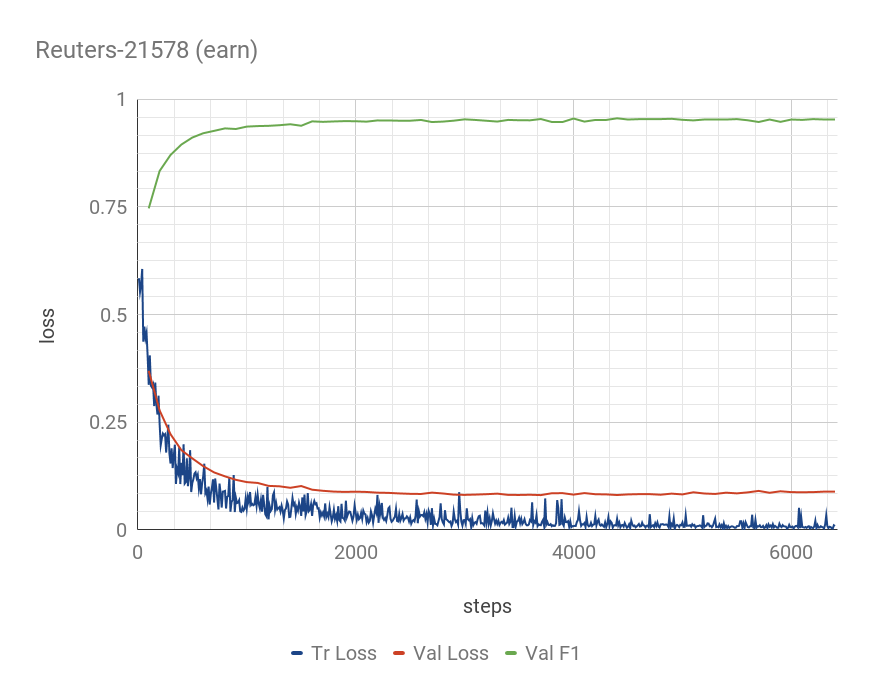
In information retrieval (IR) and related tasks, term weighting approaches typically consider the frequency of the term in the document and in the collection in order to compute a score reflecting the importance of the term for the document. In tasks characterized by the presence of training data (such as text classification) it seems logical that the term weighting function should take into account the distribution (as estimated from training data) of the term across the classes of interest. Although `supervised term weighting' approaches that use this intuition have been described before, they have failed to show consistent improvements. In this article we analyse the possible reasons for this failure, and call consolidated assumptions into question. Following this criticism we propose a novel supervised term weighting approach that, instead of relying on any predefined formula, learns a term weighting function optimised on the training set of interest; we dub this approach \emph{Learning to Weight} (LTW). The experiments that we run on several well-known benchmarks, and using different learning methods, show that our method outperforms previous term weighting approaches in text classification.
翻译:在信息检索(IR)和相关任务中,术语加权方法通常考虑该术语在文档和收集中的频率,以便计算反映该术语对文件重要性的得分。在以培训数据(如文本分类)为特征的任务中,似乎合乎逻辑的是,该术语加权功能应考虑到该术语在各利益类别之间的分布(根据培训数据估算)。虽然以前曾描述过使用这一直觉的“受监督术语加权”方法,但它们未能显示一致的改进。在本条中,我们分析了失败的可能原因,并提出了综合假设。在提出这一批评之后,我们提出了一个新的有监督的术语加权方法,即不依赖任何预先界定的公式,而是学习一个在培训利益类别上优化的术语加权功能;我们把这一方法置于几个众所周知的基准上,使用不同的学习方法,显示我们的方法比文字分类中以前的术语加权方法要好。