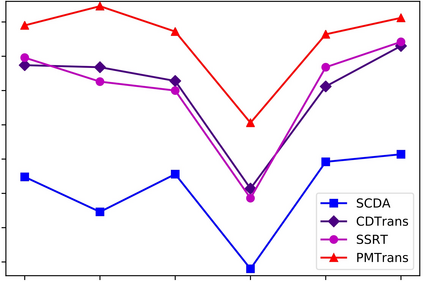
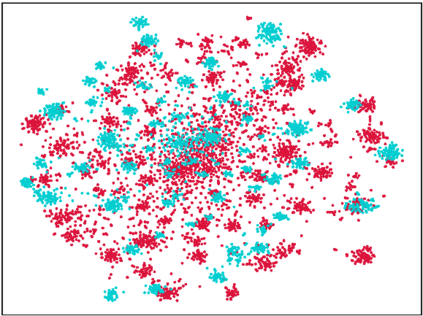
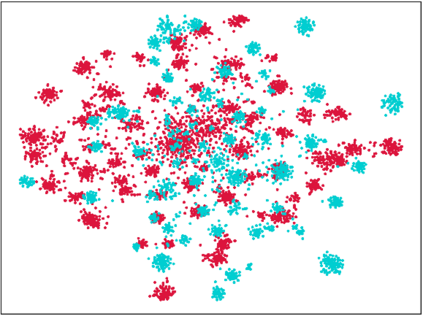
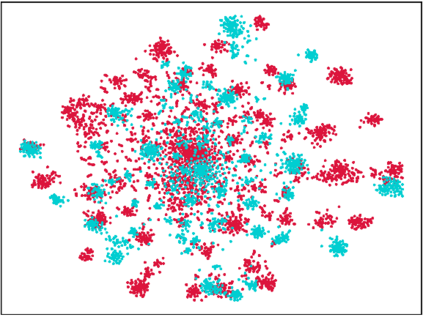
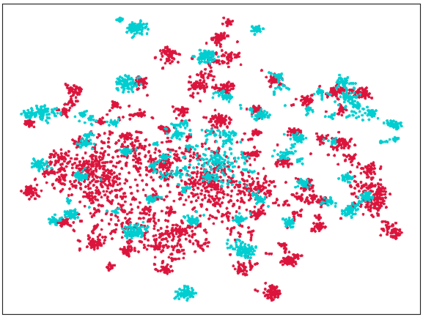
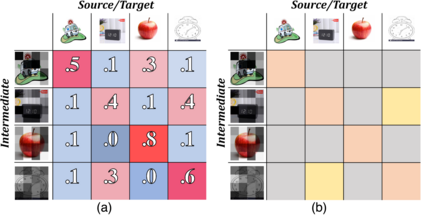
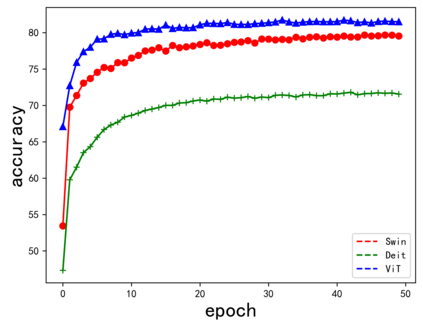
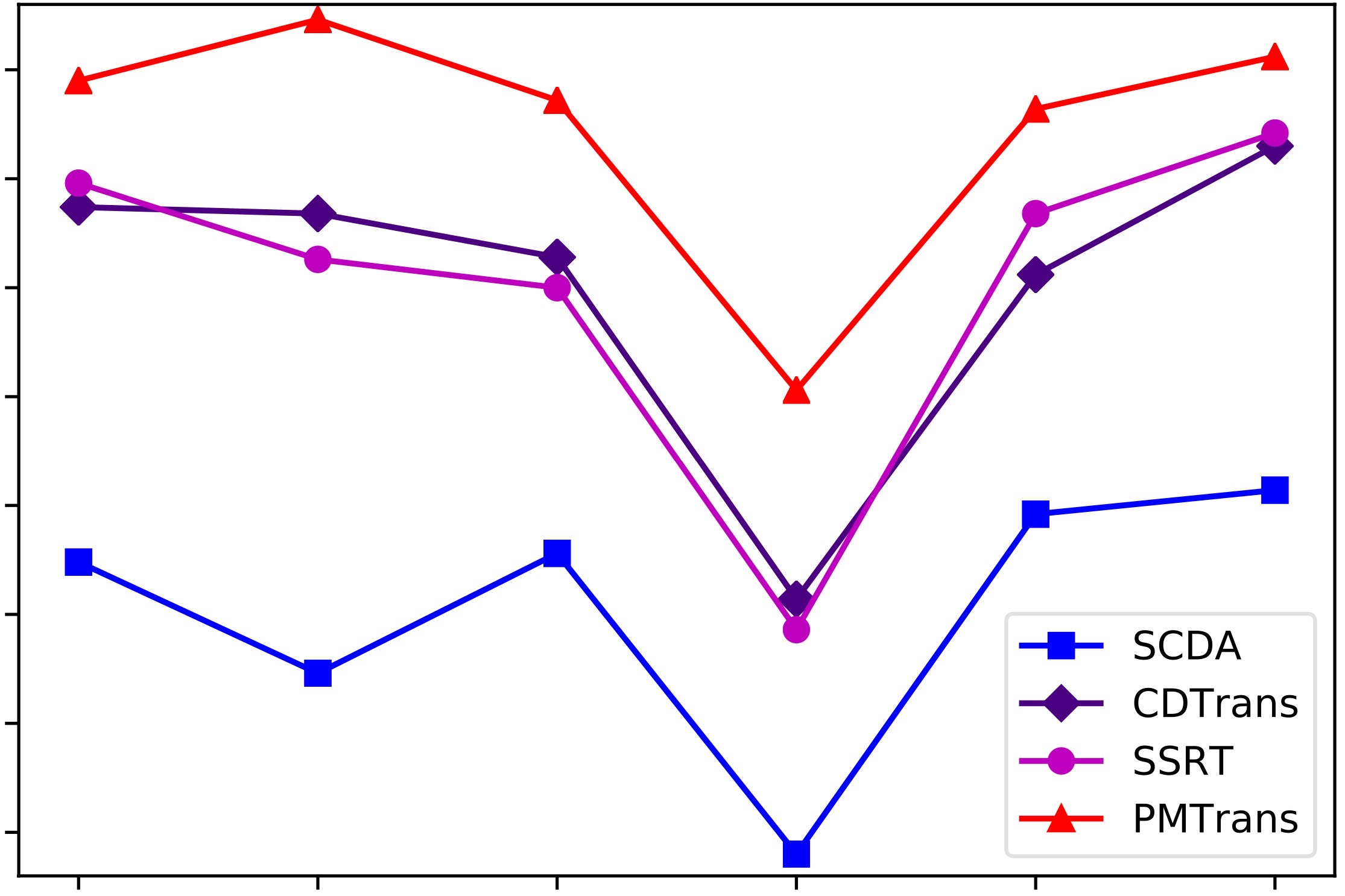
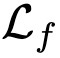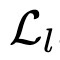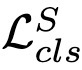Endeavors have been recently made to leverage the vision transformer (ViT) for the challenging unsupervised domain adaptation (UDA) task. They typically adopt the cross-attention in ViT for direct domain alignment. However, as the performance of cross-attention highly relies on the quality of pseudo labels for targeted samples, it becomes less effective when the domain gap becomes large. We solve this problem from a game theory's perspective with the proposed model dubbed as PMTrans, which bridges source and target domains with an intermediate domain. Specifically, we propose a novel ViT-based module called PatchMix that effectively builds up the intermediate domain, i.e., probability distribution, by learning to sample patches from both domains based on the game-theoretical models. This way, it learns to mix the patches from the source and target domains to maximize the cross entropy (CE), while exploiting two semi-supervised mixup losses in the feature and label spaces to minimize it. As such, we interpret the process of UDA as a min-max CE game with three players, including the feature extractor, classifier, and PatchMix, to find the Nash Equilibria. Moreover, we leverage attention maps from ViT to re-weight the label of each patch by its importance, making it possible to obtain more domain-discriminative feature representations. We conduct extensive experiments on four benchmark datasets, and the results show that PMTrans significantly surpasses the ViT-based and CNN-based SoTA methods by +3.6% on Office-Home, +1.4% on Office-31, and +17.7% on DomainNet, respectively.
翻译:最近,人们开始利用视觉Transformer(ViT)来解决具有挑战性的无监督领域适应(UDA)任务。这些方法通常在ViT中采用交叉注意力以进行直接的域对齐。然而,由于交叉注意力的性能高度依赖于针对样本的伪标签的质量,因此当域差距变大时,它变得不太有效。我们从博弈论的角度解决了这个问题,提出了一种名为PMTrans的模型,将源域和目标域与中间域联系起来。具体而言,我们提出了一种基于ViT的新型模块PatchMix,通过学习基于博弈论模型从两个领域中采样补丁,有效地建立了中间域,即概率分布。这样,它学习将源域和目标域的补丁混合以最大化交叉熵(CE),同时利用特征空间和标签空间中的两种半监督mixup损失来最小化它们。因此,我们认为通过将UDA过程解释为具有三名玩家(特征提取器、分类器和PatchMix)的最小最大CE博弈来寻找纳什均衡。此外,我们利用ViT的注意力图重新加权每个补丁的标签,以其重要性为标准,从而使其可能获得更具区分性的特征表示。我们在四个基准数据集上进行了大量实验,结果表明,PMTrans在Office-Home、Office-31和DomainNet上分别比基于ViT和基于CNN的SoTA方法高出+3.6%、+1.4%和+17.7%。