
题目 Geometry-aware Domain Adaptation for Unsupervised Alignment of Word Embeddings
摘要:
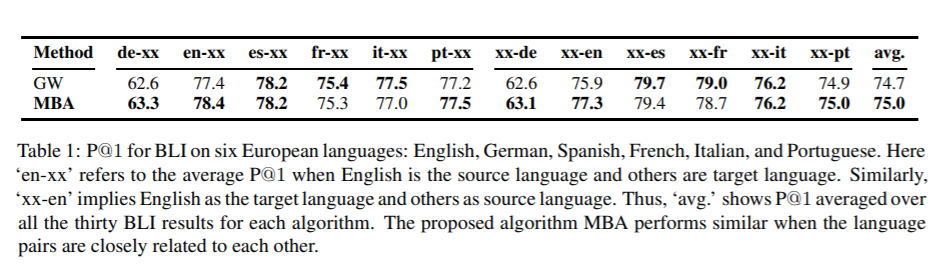
本文提出了一种新的基于流形的几何学习方法来学习源语言和目标语言之间的无监督词嵌入对齐。该方法将对列学习问题归结为双随机矩阵流形上的域适应问题。这一观点的提出是为了对齐两个语言空间的二阶信息。利用双随机流形的丰富几何性质,提出了一种高效的黎曼流形的共轭梯度算法。从经验上看,该方法在跨语言对的双语词汇归纳任务中表现优于基于最优迁移的方法。远程语言对性能的提高更为显著。
成为VIP会员查看完整内容
相关内容

专知会员服务
99+阅读 · 2020年7月6日
专知会员服务
41+阅读 · 2020年4月11日
专知会员服务
13+阅读 · 2020年3月12日
专知会员服务
32+阅读 · 2020年2月26日

相关VIP内容
专知会员服务
99+阅读 · 2020年7月6日
专知会员服务
41+阅读 · 2020年4月11日
专知会员服务
13+阅读 · 2020年3月12日
专知会员服务
32+阅读 · 2020年2月26日
相关资讯
相关论文