vae 相关论文 表示学习 1
互信息 DIM https://github.com/rdevon/DIM
gqn 多传感器 位置信息+视觉信息的互相学习。
beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework Irina Higgins, Loic Matthey, Arka Pal, Christopher Burgess, Xavier Glorot, Matthew Botvinick, Shakir Mohamed, Alexander Lerchner
05 Nov 2016 (modified: 18 Apr 2017)ICLR 2017 conference submissionReaders: EveryoneRevisions
Abstract: Learning an interpretable factorised representation of the independent data generative factors of the world without supervision is an important precursor for the development of artificial intelligence that is able to learn and reason in the same way that humans do. We introduce beta-VAE, a new state-of-the-art framework for automated discovery of interpretable factorised latent representations from raw image data in a completely unsupervised manner. Our approach is a modification of the variational autoencoder (VAE) framework. We introduce an adjustable hyperparameter beta that balances latent channel capacity and independence constraints with reconstruction accuracy. We demonstrate that beta-VAE with appropriately tuned beta > 1 qualitatively outperforms VAE (beta = 1), as well as state of the art unsupervised (InfoGAN) and semi-supervised (DC-IGN) approaches to disentangled factor learning on a variety of datasets (celebA, faces and chairs). Furthermore, we devise a protocol to quantitatively compare the degree of disentanglement learnt by different models, and show that our approach also significantly outperforms all baselines quantitatively. Unlike InfoGAN, beta-VAE is stable to train, makes few assumptions about the data and relies on tuning a single hyperparameter, which can be directly optimised through a hyper parameter search using weakly labelled data or through heuristic visual inspection for purely unsupervised data.
Deep Variational Information Bottleneck
Alexander A. Alemi, Ian Fischer, Joshua V. Dillon, Kevin Murphy
(Submitted on 1 Dec 2016 (v1), last revised 17 Jul 2017 (this version, v5))
We present a variational approximation to the information bottleneck of Tishby et al. (1999). This variational approach allows us to parameterize the information bottleneck model using a neural network and leverage the reparameterization trick for efficient training. We call this method "Deep Variational Information Bottleneck", or Deep VIB. We show that models trained with the VIB objective outperform those that are trained with other forms of regularization, in terms of generalization performance and robustness to adversarial attack.
SCAN: Learning Hierarchical Compositional Visual Concepts
基于beta vae 抽象还不够,符号化的思路还不错
VAE with a VampPrior
Jakub M. Tomczak, Max Welling
(Submitted on 19 May 2017 (v1), last revised 26 Feb 2018 (this version, v5))
Many different methods to train deep generative models have been introduced in the past. In this paper, we propose to extend the variational auto-encoder (VAE) framework with a new type of prior which we call "Variational Mixture of Posteriors" prior, or VampPrior for short. The VampPrior consists of a mixture distribution (e.g., a mixture of Gaussians) with components given by variational posteriors conditioned on learnable pseudo-inputs. We further extend this prior to a two layer hierarchical model and show that this architecture with a coupled prior and posterior, learns significantly better models. The model also avoids the usual local optima issues related to useless latent dimensions that plague VAEs. We provide empirical studies on six datasets, namely, static and binary MNIST, OMNIGLOT, Caltech 101 Silhouettes, Frey Faces and Histopathology patches, and show that applying the hierarchical VampPrior delivers state-of-the-art results on all datasets in the unsupervised permutation invariant setting and the best results or comparable to SOTA methods for the approach with convolutional networks.
Hyperspherical Variational Auto-Encoders
Tim A. Davidson , Luca Falorsi , Nicola dog , Thomas Kipf , Jakub M. Tomczak
(Submitted on 3 Apr 2018)
The Variational Auto-Encoder (VAE) is one of the most used unsupervised machine learning models. But although the default choice of a Gaussian distribution for both the prior and posterior represents a mathematically convenient distribution often leading to competitive results, we show that this parameterization fails to model data with a latent hyperspherical structure. To address this issue we propose using a von Mises-Fisher (vMF) distribution instead, leading to a hyperspherical latent space. Through a series of experiments we show how such a hyperspherical VAE, or-VAE, is more suitable for capturing data with a hyperspherical latent structure, while outperforming a normal, -VAE, in low dimensions on other data types.
https://github.com/nicola-decao/s-vae-tf




Understanding disentangling in
Christopher P. Burgess, Irina Higgins, Arka Pal, Loic Matthey, Nick Watters, Guillaume Desjardins, Alexander Lerchner
(Submitted on 10 Apr 2018)
We present new intuitions and theoretical assessments of the emergence of disentangled representation in variational autoencoders. Taking a rate-distortion theory perspective, we show the circumstances under which representations aligned with the underlying generative factors of variation of data emerge when optimising the modified ELBO bound inβ-VAE, as training progresses. From these insights, we propose a modification to the training regime of β-VAE, that progressively increases the information capacity of the latent code during training. This modification facilitates the robust learning of disentangled representations in β-VAE, without the previous trade-off in reconstruction accuracy.


Isolating Sources of Disentanglement in Variational Autoencoders
Chen Qi tian , Xuechen Li , Roger Grosse , David Duvenaud
(Submitted on 14 Feb 2018 (v1), last revised 16 Apr 2018 (this version, v2))
We decompose the evidence lower bound to show the existence of a term measuring the total correlation between latent variables. We use this to motivate ourβ-TCVAE (Total Correlation Variational Autoencoder), a refinement of the state-of-the-art β-VAE objective for learning disentangled representations, requiring no additional hyperparameters during training. We further propose a principled classifier-free measure of disentanglement called the mutual information gap (MIG). We perform extensive quantitative and qualitative experiments, in both restricted and non-restricted settings, and show a strong relation between total correlation and disentanglement, when the latent variables model is trained using our framework.
Structured Disentangled Representations
Babak Esmaeili , Hao Wu , Sarthak Jain , Alican Bozkurt , N. Siddharth , Brooks Paige , Dana H. Brooks , Jennifer Dy , Jan-Willem van de Meent
(Submitted on 6 Apr 2018 (v1), last revised 29 May 2018 (this version, v3))
Deep latent-variable models learn representations of high-dimensional data in an unsupervised manner. A number of recent efforts have focused on learning representations that disentangle statistically independent axes of variation by introducing modifications to the standard objective function. These approaches generally assume a simple diagonal Gaussian prior and as a result are not able to reliably disentangle discrete factors of variation. We propose a two-level hierarchical objective to control relative degree of statistical independence between blocks of variables and individual variables within blocks. We derive this objective as a generalization of the evidence lower bound, which allows us to explicitly represent the trade-offs between mutual information between data and representation, KL divergence between representation and prior, and coverage of the support of the empirical data distribution. Experiments on a variety of datasets demonstrate that our objective can not only disentangle discrete variables, but that doing so also improves disentanglement of other variables and, importantly, generalization even to unseen combinations of factors.


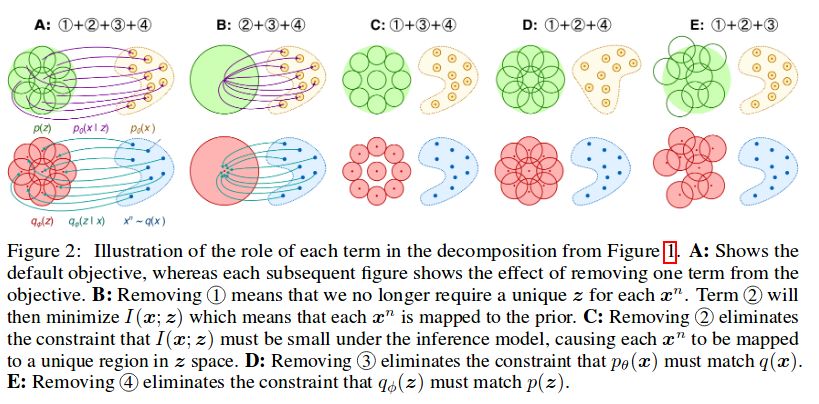
https://arxiv.org/pdf/1807.09245.pdf 两年前出的更新的 代码下面:
视频展示运动的VAE