
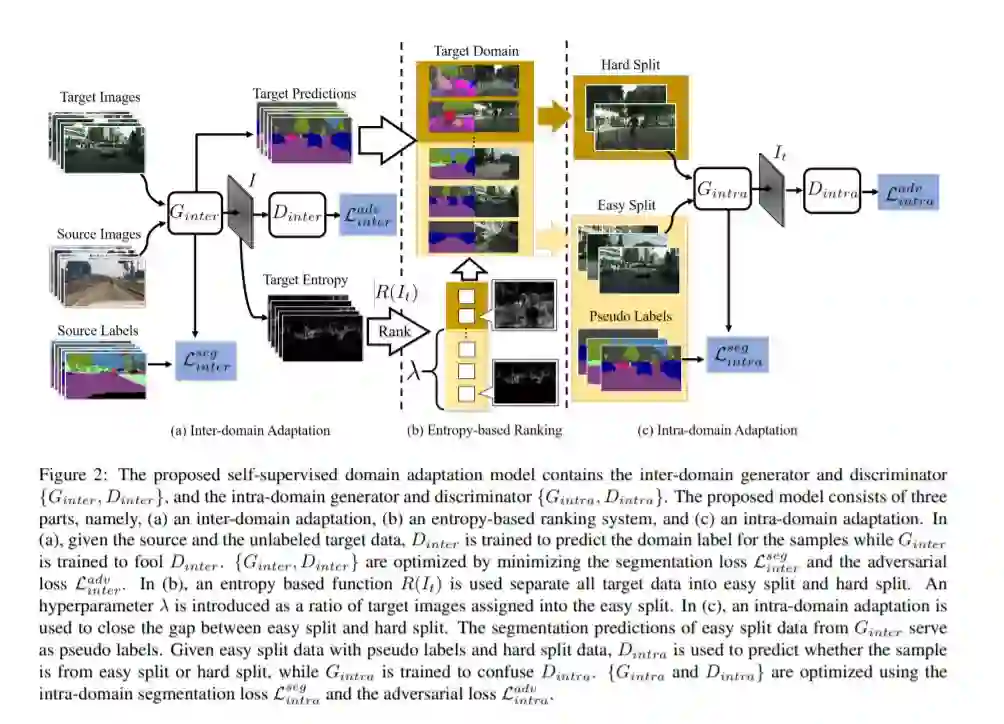
基于卷积神经网络的方法在语义分割方面取得了显著的进展。然而,这些方法严重依赖于注释数据,这是劳动密集型的。为了解决这一限制,使用从图引擎生成的自动注释数据来训练分割模型。然而,从合成数据训练出来的模型很难转换成真实的图像。为了解决这个问题,以前的工作已经考虑直接将模型从源数据调整到未标记的目标数据(以减少域间的差距)。尽管如此,这些技术并没有考虑到目标数据本身之间的巨大分布差异(域内差异)。在这项工作中,我们提出了一种两步自监督域适应方法来减少域间和域内的差距。首先,对模型进行域间自适应;在此基础上,我们使用基于熵的排序函数将目标域分成简单和困难的两部分。最后,为了减小域内间隙,我们提出了一种自监督自适应技术。在大量基准数据集上的实验结果突出了我们的方法相对于现有的最先进方法的有效性。
成为VIP会员查看完整内容
相关内容

CVPR is the premier annual computer vision event comprising the main conference and several co-located workshops and short courses. With its high quality and low cost, it provides an exceptional value for students, academics and industry researchers.
CVPR 2020 will take place at The Washington State Convention Center in Seattle, WA, from June 16 to June 20, 2020.
http://cvpr2020.thecvf.com/
专知会员服务
78+阅读 · 2020年2月25日
Arxiv
6+阅读 · 2018年3月30日

相关VIP内容
专知会员服务
78+阅读 · 2020年2月25日
相关资讯
相关论文
Arxiv
6+阅读 · 2018年3月30日