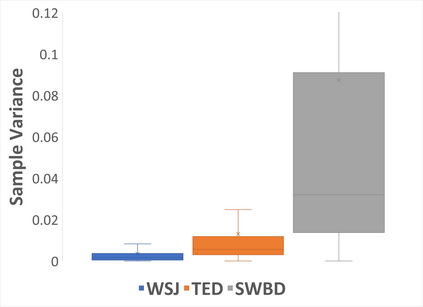
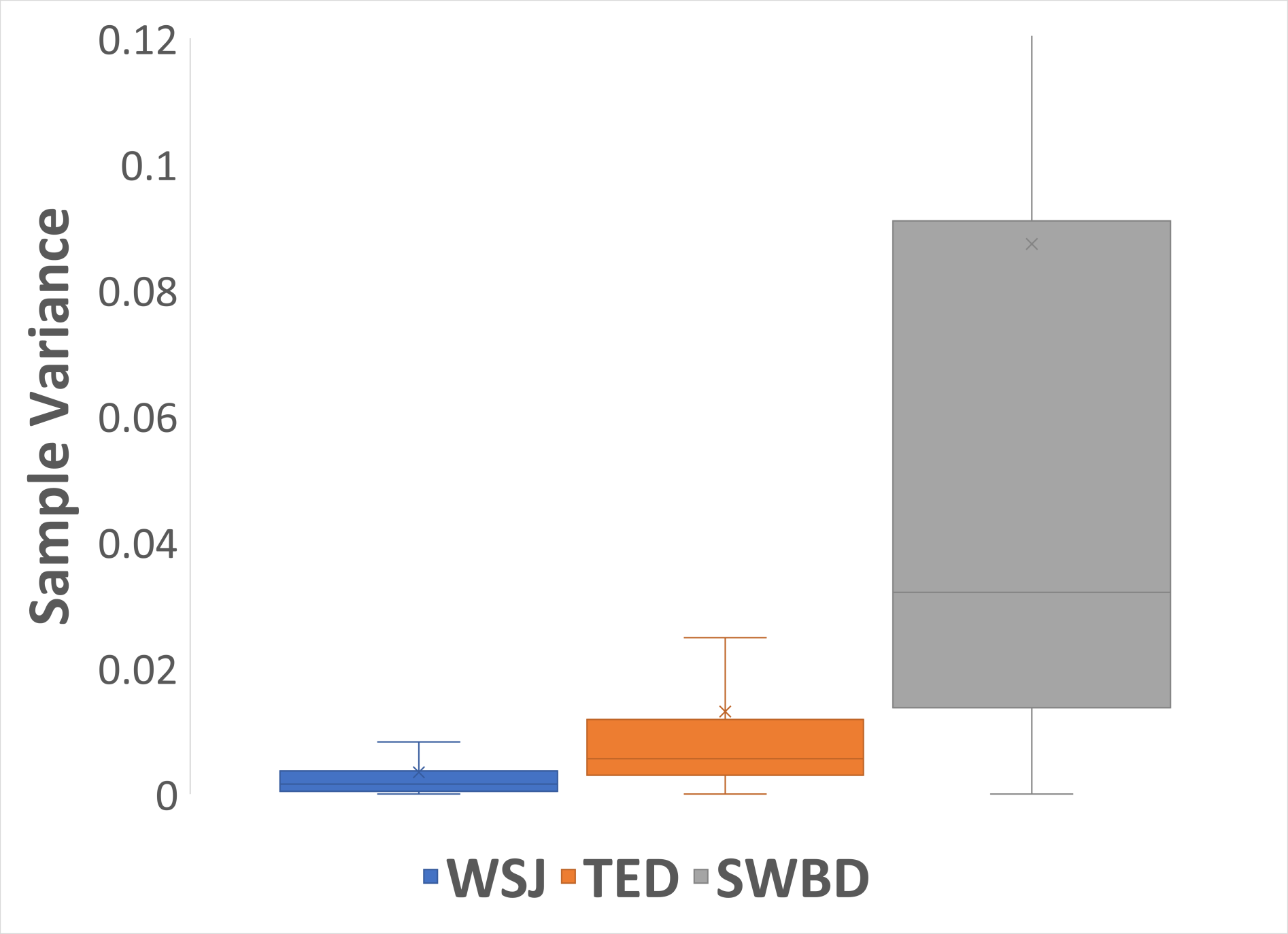
The performance of automatic speech recognition (ASR) systems typically degrades significantly when the training and test data domains are mismatched. In this paper, we show that self-training (ST) combined with an uncertainty-based pseudo-label filtering approach can be effectively used for domain adaptation. We propose DUST, a dropout-based uncertainty-driven self-training technique which uses agreement between multiple predictions of an ASR system obtained for different dropout settings to measure the model's uncertainty about its prediction. DUST excludes pseudo-labeled data with high uncertainties from the training, which leads to substantially improved ASR results compared to ST without filtering, and accelerates the training time due to a reduced training data set. Domain adaptation experiments using WSJ as a source domain and TED-LIUM 3 as well as SWITCHBOARD as the target domains show that up to 80% of the performance of a system trained on ground-truth data can be recovered.
翻译:自动语音识别( ASR) 系统的性能通常在培训和测试数据领域不匹配时会显著降低。 在本文中,我们表明,自我培训(ST)加上基于不确定性的假标签过滤法可以有效地用于域适应。 我们提议Dust, 一种基于辍学的不确定性驱动自培训技术, 这是一种基于辍学的自培训技术, 使用不同辍学环境获得的多种ASR系统预测之间的协议来衡量模型预测的不确定性。 Dust 排除了培训中具有高度不确定性的伪标签数据, 从而大大改进了与ST相比的ASR结果, 但没有过滤, 并加快了培训时间, 因为培训数据集减少。 将WSJ作为源域和TED- LIUM 3 以及 SWITCHBOARD 用于目标领域的应用实验显示, 高达80%的地面真相数据培训系统性能可以恢复。