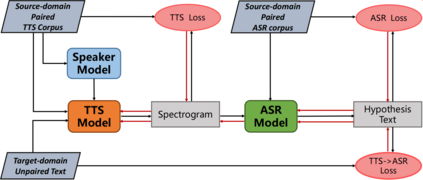
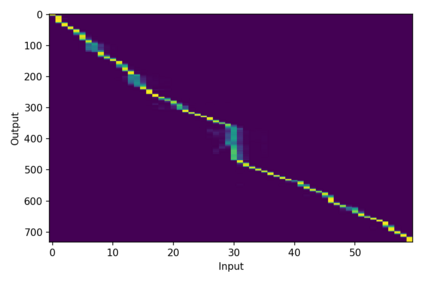
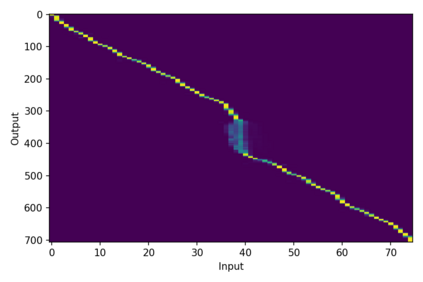
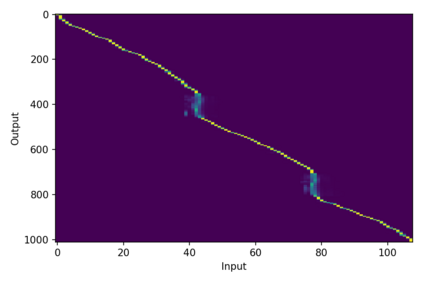
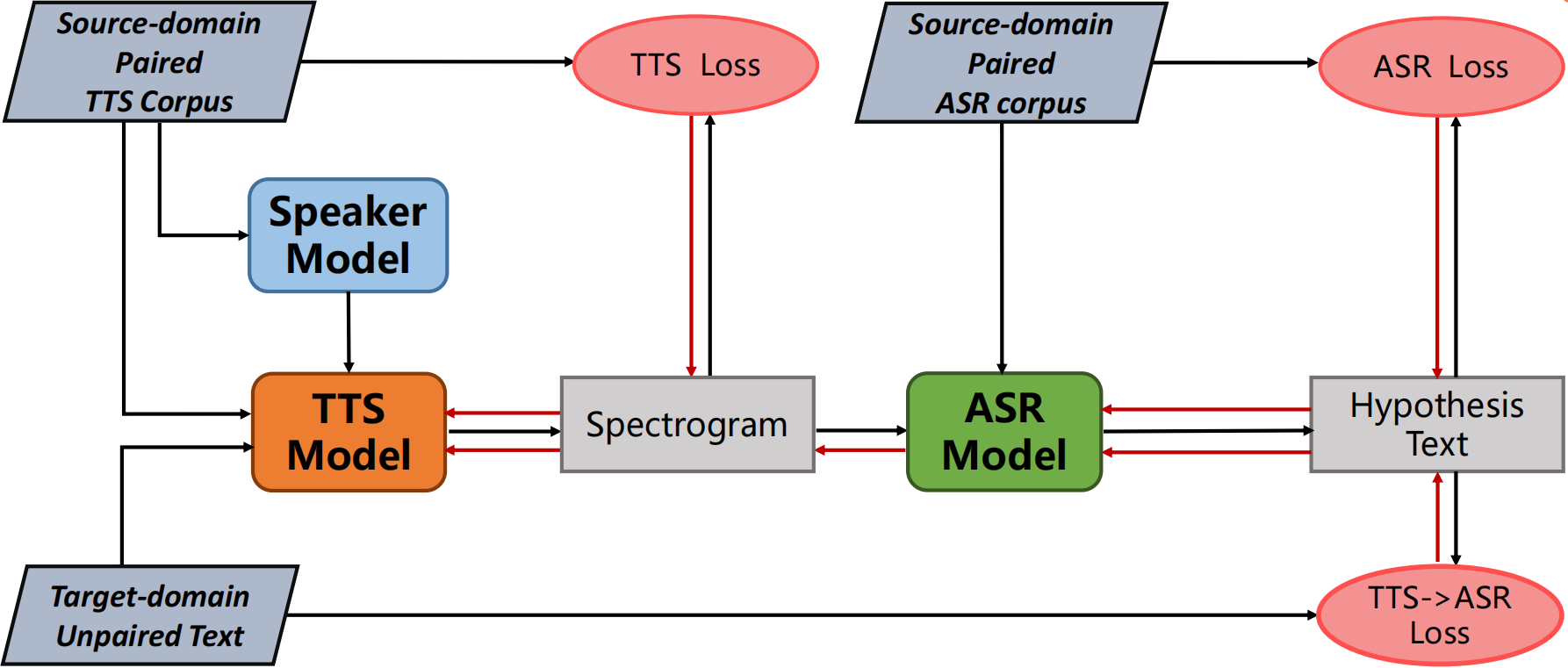
Machine Speech Chain, which integrates both end-to-end (E2E) automatic speech recognition (ASR) and text-to-speech (TTS) into one circle for joint training, has been proven to be effective in data augmentation by leveraging large amounts of unpaired data. In this paper, we explore the TTS->ASR pipeline in speech chain to do domain adaptation for both neural TTS and E2E ASR models, with only text data from target domain. We conduct experiments by adapting from audiobook domain (LibriSpeech) to presentation domain (TED-LIUM), there is a relative word error rate (WER) reduction of 10% for the E2E ASR model on the TED-LIUM test set, and a relative WER reduction of 51.5% in synthetic speech generated by neural TTS in the presentation domain. Further, we apply few-shot speaker adaptation for the E2E ASR by using a few utterances from target speakers in an unsupervised way, results in additional gains.
翻译:将终端到终端自动语音识别(E2E)自动语音识别(ASR)和文本到语音识别(TTS)合并成一个联合培训的圆圈的机器语音链,通过利用大量未保存的数据,已证明在数据增加方面行之有效。在本文中,我们探索语音链中的 TTS ->ASR 管道,对神经 TS 和 E2E ASR 模型进行域域性调整,只提供目标域内的文本数据。我们通过从音簿域(LibriSpeech)到演示域(TED-LIUM)进行实验,在TED-LIUM 测试集的E2E ASR 模型中相对字差差率降低了10%,而在演示域内线 TTS 生成的合成语音中相对减少51.5%。此外,我们通过使用目标演讲者以未超超方式发表的少数词句,对E2ESR作了微调,从而取得了更多成果。