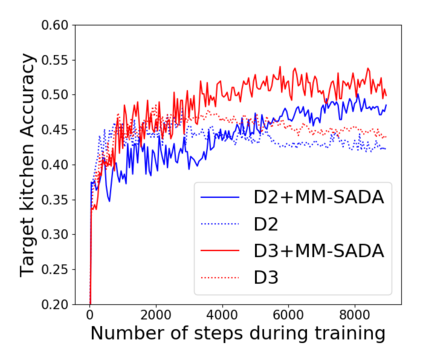
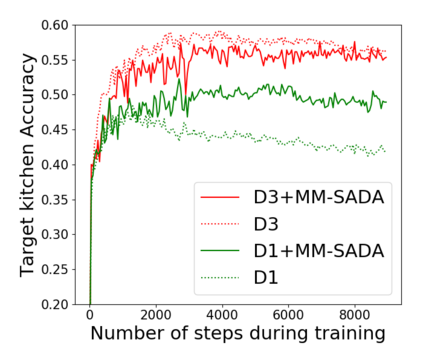
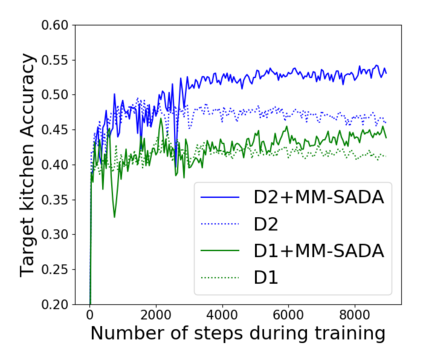
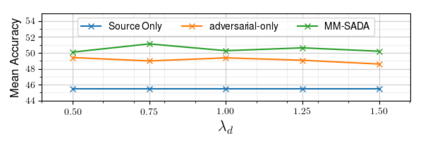
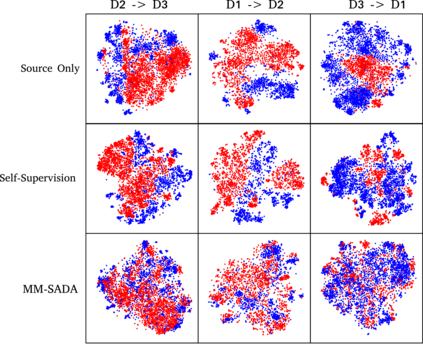
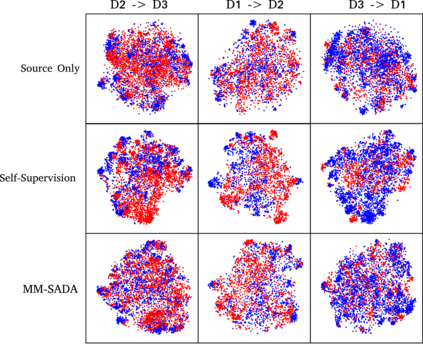
Fine-grained action recognition datasets exhibit environmental bias, where multiple video sequences are captured from a limited number of environments. Training a model in one environment and deploying in another results in a drop in performance due to an unavoidable domain shift. Unsupervised Domain Adaptation (UDA) approaches have frequently utilised adversarial training between the source and target domains. However, these approaches have not explored the multi-modal nature of video within each domain. In this work we exploit the correspondence of modalities as a self-supervised alignment approach for UDA in addition to adversarial alignment. We test our approach on three kitchens from our large-scale dataset, EPIC-Kitchens, using two modalities commonly employed for action recognition: RGB and Optical Flow. We show that multi-modal self-supervision alone improves the performance over source-only training by 2.4% on average. We then combine adversarial training with multi-modal self-supervision, showing that our approach outperforms other UDA methods by 3%.
翻译:精细的动作识别数据集显示出环境偏差,从有限的环境中捕捉到多个视频序列。在一个环境中培训一个模型,在另一个环境中部署,由于不可避免的域变换导致性能下降。无监督的域适应(UDA)方法经常在源和目标领域之间使用对抗性培训。然而,这些方法没有探索每个域内视频的多模式性质。在这项工作中,我们利用模式的对应方法作为UDA的自我监督的对齐方法,以及对抗性对齐。我们测试了我们从大规模数据集EPIC-Kitchens的三个厨房中采用的方法,使用两种通常用于行动识别的模式:RGB和光学流。我们显示,多模式的自我监督功能仅能提高对源性培训的性能,平均为2.4%。我们随后将对抗性培训与多模式的自我监督式结合起来,表明我们的方法比UDA的其他方法优于3%。