
题目: Multi-Modal Domain Adaptation for Fine-Grained Action Recognition
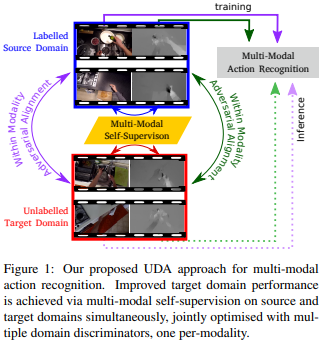
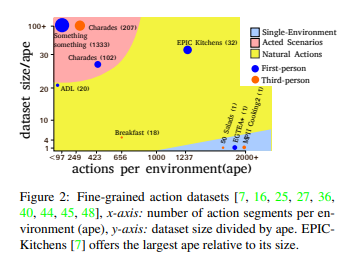
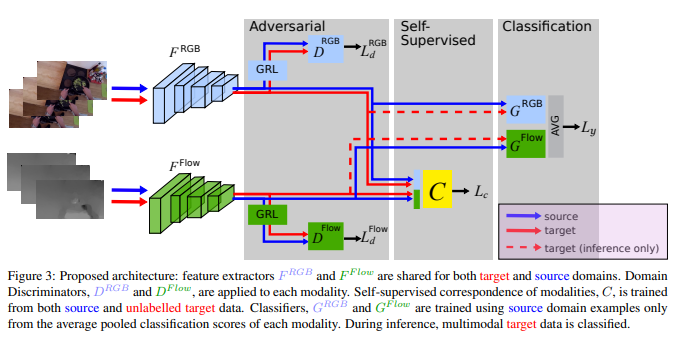
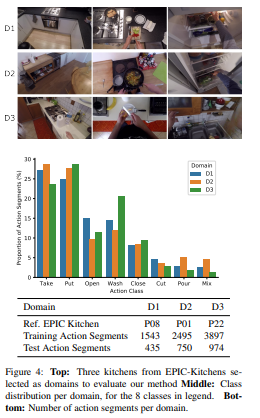
摘要: 细粒度动作识别数据集表现出环境偏差,其中多个视频序列是从有限数量的环境中捕获的。在一个环境中训练一个模型,然后部署到另一个环境中,由于不可避免的领域转换,会导致性能下降。无监督域适应(UDA)方法经常用于源域和目标域之间的对抗训练。然而,这些方法并没有探索视频在每个领域的多模态性质。在这个工作我们利用模式的通信作为UDA self-supervised对齐的方法除了敌对的对齐(图1),我们测试我们的方法在三个厨房从大规模的数据集,EPIC-Kitchens,使用两种方法通常用于行为识别:RGB和光学流。结果表明,多模态的自监督比单纯的训练平均提高了2.4%。然后我们将对抗训练与多模态自我监督相结合,结果表明我们的方法比其他的UDA方法高3%。
成为VIP会员查看完整内容
相关内容

专知会员服务
38+阅读 · 2019年12月26日




相关VIP内容
专知会员服务
38+阅读 · 2019年12月26日
相关资讯
相关论文