
题目: Unsupervised pre-training for sequence to sequence speech recognition
摘要:
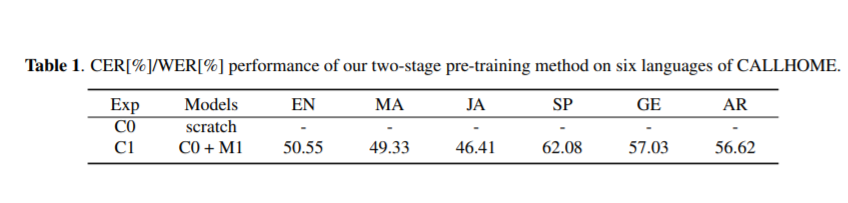
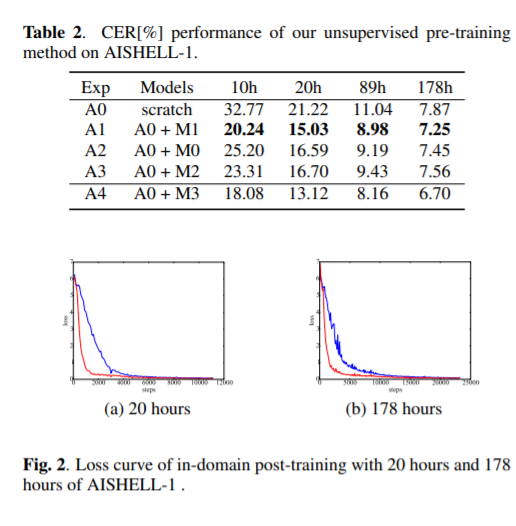
本文提出了一种新的编码-解码器序列到序列预训练模型(seq2seq)。我们的前训练方法分为两个阶段,分别是声学前训练和语言前训练。在声学预训练阶段,我们使用大量的语音来预训练编码器,通过预测掩蔽语音特征块及其上下文。在语言前训练阶段,我们使用单说话文本到语音(TTS)系统从大量的文本中生成合成语音,并使用合成的成对数据对译码器进行预训练。这种两阶段预训练方法将丰富的声学和语言知识整合到seq2seq模型中,有利于后续的自动语音识别(ASR)任务。在AISHELL-2数据集上完成无监督的预训练,我们将预训练模型应用于AISHELL-1和香港科技大学的多重配对数据比率。我们的相对错误率由AISHELL-1的38.24%降至7.88%,由香港科技大学的12.00%降至1.20%。此外,将我们的预训练模型应用到带有CALLHOME数据集的跨语言案例中。对于CALLHOME数据集中的所有六种语言,我们的预训练方法使模型始终优于基线。
作者:
徐波,研究员,1988年毕业于浙江大学,现任中国科学院自动化所所长 ,研究领域包括:多语言语音识别与机器翻译、多媒体网络内容智能处理、互动沉浸式3D互联网等。
成为VIP会员查看完整内容


相关内容
【ACL2020】不要停止预训练:根据领域和任务自适应调整语言模型,Don't Stop Pretraining: Adapt Language Models to Domains and Tasks
专知会员服务
46+阅读 · 2020年4月25日
专知会员服务
51+阅读 · 2020年3月7日
专知会员服务
43+阅读 · 2020年1月28日
Arxiv
7+阅读 · 2019年4月18日



相关VIP内容
【ACL2020】不要停止预训练:根据领域和任务自适应调整语言模型,Don't Stop Pretraining: Adapt Language Models to Domains and Tasks
专知会员服务
46+阅读 · 2020年4月25日
专知会员服务
51+阅读 · 2020年3月7日
专知会员服务
43+阅读 · 2020年1月28日
相关资讯
相关论文
Arxiv
7+阅读 · 2019年4月18日