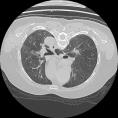
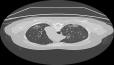
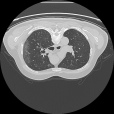
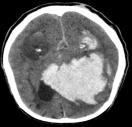
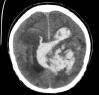
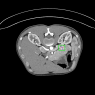
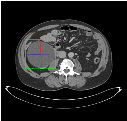
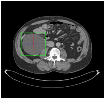
Self-paced curriculum learning (SCL) has demonstrated its great potential in computer vision, natural language processing, etc. During training, it implements easy-to-hard sampling based on online estimation of data difficulty. Most SCL methods commonly adopt a loss-based strategy of estimating data difficulty and deweighting the `hard' samples in the early training stage. While achieving success in a variety of applications, SCL stills confront two challenges in a medical image analysis task, such as universal lesion detection, featuring insufficient and highly class-imbalanced data: (i) the loss-based difficulty measurer is inaccurate; ii) the hard samples are under-utilized from a deweighting mechanism. To overcome these challenges, in this paper we propose a novel mixed-order self-paced curriculum learning (Mo-SCL) method. We integrate both uncertainty and loss to better estimate difficulty online and mix both hard and easy samples in the same mini-batch to appropriately alleviate the problem of under-utilization of hard samples. We provide a theoretical investigation of our method in the context of stochastic gradient descent optimization and extensive experiments based on the DeepLesion benchmark dataset for universal lesion detection (ULD). When applied to two state-of-the-art ULD methods, the proposed mixed-order SCL method can provide a free boost to lesion detection accuracy without extra special network designs.
翻译:自我掌握的课程学习(SCL)在计算机视觉、自然语言处理等方面显示出了巨大的潜力。在培训期间,它根据对数据困难的在线估计,采用简单到硬的抽样方法。大多数SCL方法通常在早期培训阶段采取基于损失的战略,估计数据困难和减少“硬”样本的重量。在各种应用中取得成功的同时,SCL在医学图像分析任务中仍面临两个挑战,如普遍测距,其特征为缺乏和高度等级平衡的数据:(一) 损失造成的困难测量器不准确;(二) 硬样品没有从脱重机制中得到充分利用。为了克服这些挑战,我们在本文件中建议采用新的混合顺序自我掌握课程学习(MO-SCL)方法。我们结合不确定性和损失,以更好地估计在线困难,并将硬和易的样品混合在一起,以适当减轻硬样品利用不足的问题。我们从理论上研究了我们的方法,从“脱重梯梯梯梯级”梯级优化和根据“深梯级”系统进行的广泛实验。我们提议采用“混合式自我定位”基准数据,以便采用“通用测深路”后,可以提供一种特殊测定的“ULD”方法。