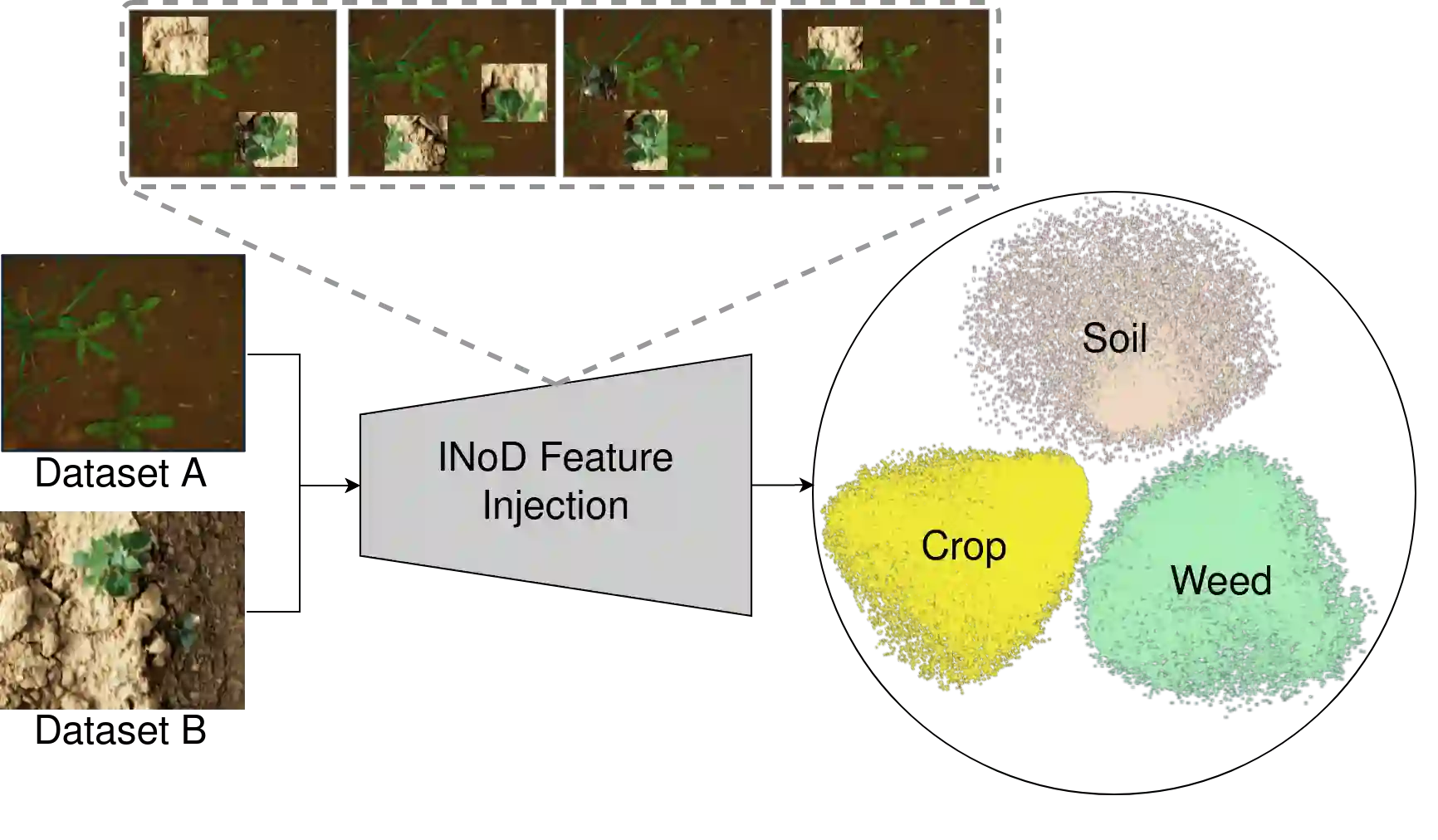
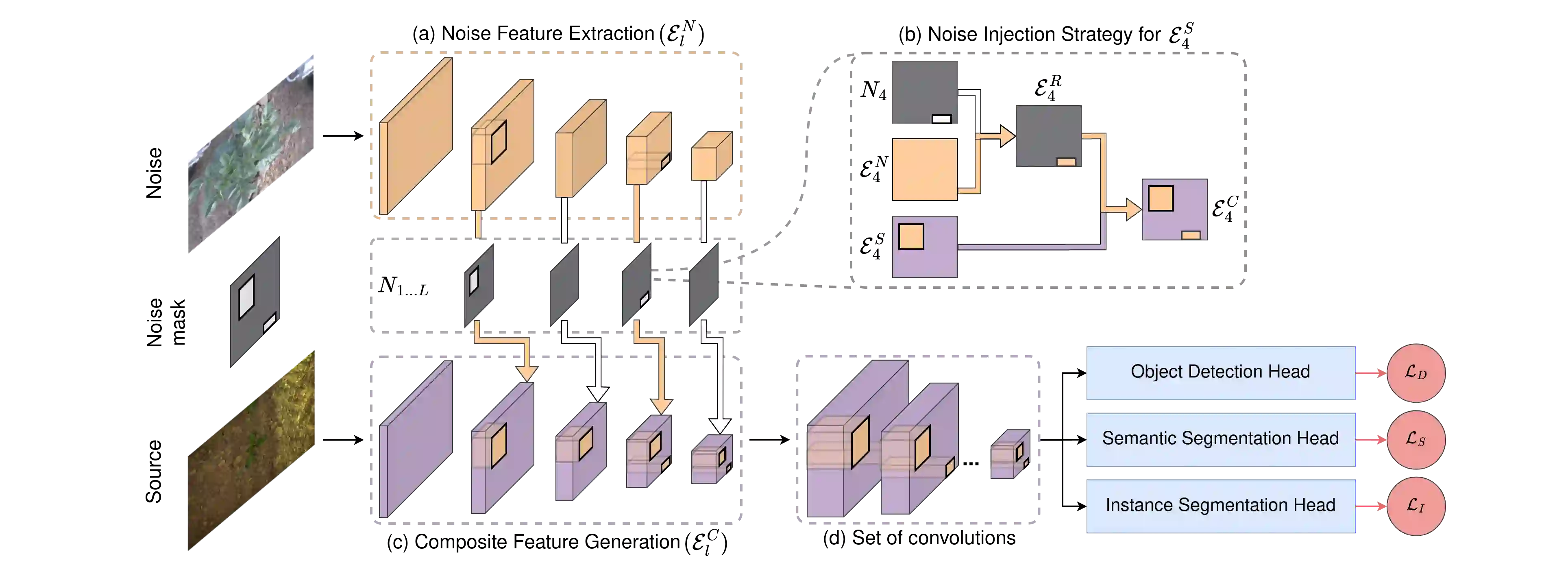
Perception datasets for agriculture are limited both in quantity and diversity which hinders effective training of supervised learning approaches. Self-supervised learning techniques alleviate this problem, however, existing methods are not optimized for dense prediction tasks in agriculture domains which results in degraded performance. In this work, we address this limitation with our proposed Injected Noise Discriminator (INoD) which exploits principles of feature replacement and dataset discrimination for self-supervised representation learning. INoD interleaves feature maps from two disjoint datasets during their convolutional encoding and predicts the dataset affiliation of the resultant feature map as a pretext task. Our approach enables the network to learn unequivocal representations of objects seen in one dataset while observing them in conjunction with similar features from the disjoint dataset. This allows the network to reason about higher-level semantics of the entailed objects, thus improving its performance on various downstream tasks. Additionally, we introduce the novel Fraunhofer Potato 2022 dataset consisting of over 16,800 images for object detection in potato fields. Extensive evaluations of our proposed INoD pretraining strategy for the tasks of object detection, semantic segmentation, and instance segmentation on the Sugar Beets 2016 and our potato dataset demonstrate that it achieves state-of-the-art performance.
翻译:摘要:农业感知数据集在数量和多样性方面都存在局限,这阻碍了监督式学习方法的有效训练。自我监督学习技术缓解了这个问题,但现有方法并未针对农业领域中密集预测任务进行优化,从而导致了性能下降。在这项工作中,我们提出了“注入噪声判别器”(INoD),它利用特征替换和数据集判别原理进行自我监督表示学习。INoD在卷积编码期间交织两个不相交数据集的特征映射,并将所得到的特征映射的数据集归属(预文本任务)预测出来。我们的方法使网络能够在观察到一个数据集中的对象时,同时与从不相交数据集中获得的相似特征一起进行推理,从而学习不含糊的对象表示。这使得网络能够推断所涉对象的更高级语义,从而在各种下游任务上提高性能。此外,我们还介绍了新颖的“弗劳恩霍夫马铃薯 2022 ”数据集,其中包括超过16,800张用于土豆田地物体检测的图像。对INoD预训练策略在糖甜菜 2016 和我们的土豆数据集上进行目标检测、语义分割和实例分割任务的广泛评估表明,它实现了最先进的性能。