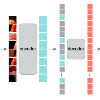
Despite the tremendous progress of Masked Autoencoders (MAE) in developing vision tasks such as image and video, exploring MAE in large-scale 3D point clouds remains challenging due to the inherent irregularity. In contrast to previous 3D MAE frameworks, which either design a complex decoder to infer masked information from maintained regions or adopt sophisticated masking strategies, we instead propose a much simpler paradigm. The core idea is to apply a \textbf{G}enerative \textbf{D}ecoder for MAE (GD-MAE) to automatically merges the surrounding context to restore the masked geometric knowledge in a hierarchical fusion manner. In doing so, our approach is free from introducing the heuristic design of decoders and enjoys the flexibility of exploring various masking strategies. The corresponding part costs less than \textbf{12\%} latency compared with conventional methods, while achieving better performance. We demonstrate the efficacy of the proposed method on several large-scale benchmarks: Waymo, KITTI, and ONCE. Consistent improvement on downstream detection tasks illustrates strong robustness and generalization capability. Not only our method reveals state-of-the-art results, but remarkably, we achieve comparable accuracy even with \textbf{20\%} of the labeled data on the Waymo dataset. The code will be released at \url{https://github.com/Nightmare-n/GD-MAE}.
翻译:尽管蒙面自动编码器(MAE)在开发图像和视频等视觉任务方面取得了巨大进展,但是在大型3D点云层中探索MAE仍因其固有的不规则性而具有挑战性。与以前的3DMAE框架不同,前者设计了一个复杂的解码器,用于从维持的区域推断蒙面信息,或采用复杂的遮面战略,我们却提出了一个简单得多的范例。核心理念是应用\ textbf{General dety\ textbf{D}N}coder,为MAE(GD-MAE)自动结合周围环境,以等级化方式恢复隐面几何知识。与此相反,我们的方法是自由的,没有引入解面码器的超额设计,也没有灵活地探索各种掩面战略。相应的部分成本低于\ textbf{12} ⁇ 亮度与传统方法相比,同时取得更好的业绩。我们展示了拟议的方法在几个大规模基准上的有效性:Waymo, KITTI, 和 ONCE。下游探测任务的持续改进显示了强的准确性和总体化能力。我们仅仅展示了标签/发行数据的方法。我们的方法将显示我们的数据。只有州/版本。