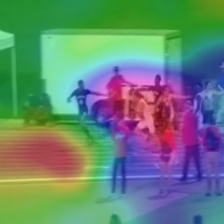Video captioning is a challenging task that requires a deep understanding of visual scenes. State-of-the-art methods generate captions using either scene-level or object-level information but without explicitly modeling object interactions. Thus, they often fail to make visually grounded predictions, and are sensitive to spurious correlations. In this paper, we propose a novel spatio-temporal graph model for video captioning that exploits object interactions in space and time. Our model builds interpretable links and is able to provide explicit visual grounding. To avoid unstable performance caused by the variable number of objects, we further propose an object-aware knowledge distillation mechanism, in which local object information is used to regularize global scene features. We demonstrate the efficacy of our approach through extensive experiments on two benchmarks, showing our approach yields competitive performance with interpretable predictions.
翻译:视频字幕是一项具有挑战性的任务,需要深入了解视觉场景。 最先进的方法利用现场水平或目标水平的信息生成字幕,但没有明确模拟物体相互作用。 因此,它们往往无法作出目视预测,而且对虚假的关联性敏感。 在本文中,我们提出了一个新颖的视频字幕时空图模型,用于利用物体在空间和时间上的相互作用。 我们的模型可以建立可解释的链接,并能够提供明确的视觉地面。 为了避免由物体数量变化造成的不稳定性性能,我们进一步提议一个有目共睹的知识蒸馏机制,其中利用当地物体信息规范全球场景特征。 我们通过在两个基准上进行广泛的实验,展示我们的方法的有效性,展示我们的方法通过可解释的预测产生竞争性性能。